 Apache Spark作为全球最流行的数据分析应用
Apache Spark作为全球最流行的数据分析应用
Apache Spark作为全球最流行的数据分析应用,现已通过此前发布的Spark 3.0版本为超过50万用户提供革命性的GPU加速。
Databricks为用户提供了先进的企业云平台Spark,每天有超过100万台虚拟机运行该平台。在Spark + AI Summit峰会上,Databricks宣布其用于机器学习的Databricks Runtime 7.0将配备内置Spark 3.0的GPU加速器感知调度功能。该功能由Databricks与NVIDIA和其他社区成员合作开发。
Google Cloud近期宣布在Dataproc image 2.0版本上提供Spark 3.0预览版,同时指出在开源社区的协作下,现在已获得强大的NVIDIA GPU加速。NVIDIA将于7月16日与Google Cloud共同举办一场网络研讨会,深入探讨这些令数据科学家感到兴奋的新功能。
此外,用于Apache Spark的新开源RAPIDS 加速器现在可以加速ETL(提取、转换、加载)和数据传输,在无需更改任何代码的情况下提高端到端分析性能。
Spark性能的加速不仅意味着能够更快获得洞见,而且由于企业可以使用更少的基础设施来完成工作负载,因此还可以帮助企业降低成本。
加速数据分析:科学计算赋予AI更强大的力量
Spark有充分的理由成为新闻媒体报导的焦点。
数据对于帮助企业机构应对不断变化的机遇和潜在威胁至关重要。为此,他们需要破译隐藏在数据中的关键线索。
每当客户点击网站、拨打客户服务电话或生成每日销售报告时,就会给企业机构贡献大量的信息。随着AI的兴起,数据分析对于帮助公司发现趋势并保持市场领先地位所起到的作用日益重要。
前不久,数据分析还依靠小型数据集来收集历史数据和洞见,通过ETL对存储在传统数据仓库中的高度结构化数据进行分析。
ETL常常成为数据科学家在获取AI预测和建议时的瓶颈。ETL预计会占用数据科学家70%至90%的时间,这会减慢工作流程并将炙手可热的人才束缚在最普通的工作上。
当数据科学家在等待ETL时,他们无法重新训练模型来获取更好的商业洞见。传统的CPU基础设施无法通过有效的扩展来适应这些工作任务,这通常会大幅增加成本。
凭借GPU加速的Spark,ETL就不会再产生这样的麻烦。医疗、娱乐、能源、金融、零售等行业现在可以经济、高效地为其数据分析提速,更快地获取洞见。
并行处理助力数据分析
GPU并行处理使计算机可以一次执行多项操作。数据中心通过大规模横向扩展这些功能来支持复杂的数据分析项目。随着运用AI和机器学习工具的企业机构日益增加,并行处理已成为加速海量数据分析和ETL管道,进而驱动这些工作负载的关键。
比如有一家零售商希望预测下一个季节的库存。该零售商需要检查近期的销售量以及去年的数据。数据科学家还可可以此分析中添加天气模型,从而了解雨季或旱季对结果产生的影响。零售商还可以整合情绪分析数据,评估今年最流行的趋势。
由于需要分析的数据源太多,因此在对不同变量可能对销售量产生的影响进行建模时,速度就显得尤为重要。这就需要将分析加入到机器学习中,而且GPU也因此变得十分重要。
RAPIDS加速器为Apache Spark 3.0提速
随着数据科学家从使用传统的分析转而采用可以更好地对复杂市场需求进行建模的AI应用,如果继续采用CPU,则必须牺牲速度或增加成本才能跟上由此产生的处理需求。而随着AI在分析中的应用日益增加,需要有新的框架来通过GPU快速、经济高效地处理数据。
用于Apache Spark的全新RAPIDS加速器将Spark分布式计算框架与功能强大的RAPIDS cuDF库相连接,实现了GPU对Spark DataFrame和Spark SQL的运行提速。RAPIDS加速器还通过搜索在Spark节点之间移动数据的最快路径来加快Spark Shuffle的运行速度。
责任编辑:tzh
-
医疗
+关注
关注
8文章
1800浏览量
58650 -
AI
+关注
关注
87文章
30084浏览量
268348
发布评论请先 登录
相关推荐
LLM在数据分析中的作用
eda与传统数据分析的区别
raid 在大数据分析中的应用
SUMIF函数在数据分析中的应用
智能制造中的数据分析应用
数据分析除了spss还有什么
数据分析的工具有哪些
数据分析有哪些分析方法
机器学习在数据分析中的应用
Spark基于DPU的Native引擎算子卸载方案

求助,关于AD采集到的数据分析问题
Spark基于DPU Snappy压缩算法的异构加速方案
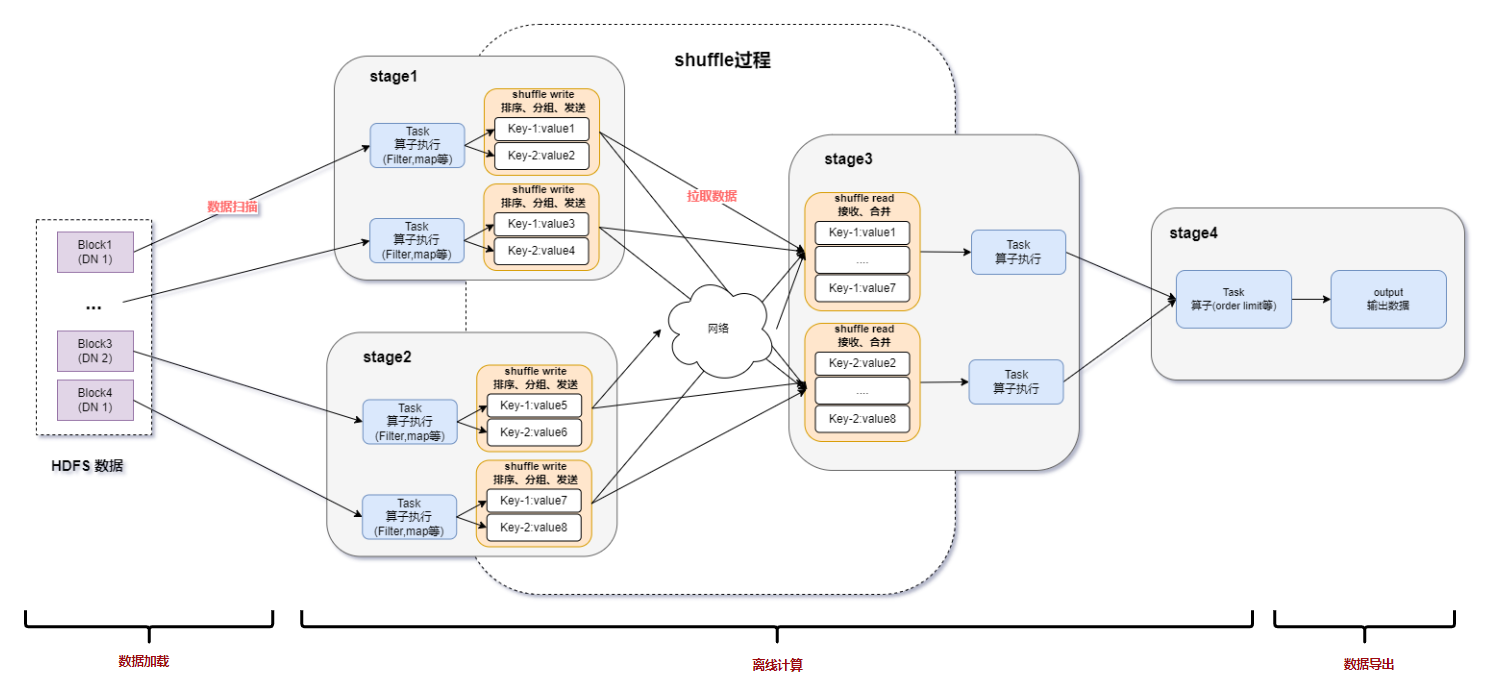
RDMA技术在Apache Spark中的应用

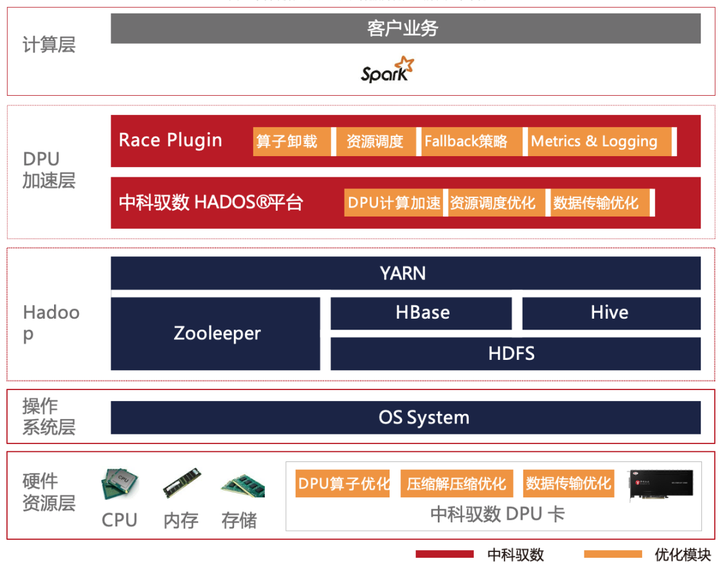
基于DPU和HADOS-RACE加速Spark 3.x





 工商网监
工商网监
评论