 如何解放你的内核?硬件加速器“使用指南”奉上
如何解放你的内核?硬件加速器“使用指南”奉上
有限脉冲响应(FIR)和无限脉冲响应(IIR)滤波器都是常用的数字信号处理算法——尤其适用于音频处理应用。因此,在典型的音频系统中,处理器内核的很大一部分时间用于FIR和IIR滤波。数字信号处理器上的片内FIR和IIR硬件加速器也分别称为FIRA和IIRA,我们可以利用这些硬件加速器来分担FIR和IIR处理任务,让内核去执行其他处理任务。在本文中,我们将借助不同的使用模型以及实时测试示例来探讨如何在实践中利用这些加速器。

图1.FIRA和IIRA系统方框图。
图1显示了FIRA和IIRA的简化方框图,以及它们与其余处理器系统和资源的交互方式。
FIRA和IIRA模块均主要包含一个计算引擎(乘累加(MAC)单元)以及一个小的本地数据和系数RAM。
为开始进行FIRA/IIRA处理,内核使用通道特定信息初始化处理器存储器中的DMA传输控制块(TCB)链。然后将该TCB链的起始地址写入FIRA/IIRA链指针寄存器,随后配置FIRA/IIRA控制寄存器以启动加速器处理。一旦所有通道的配置完成,就会向内核发送一个中断,以便内核将处理后的输出用于后续操作。
从理论上讲,最好的方法是将所有FIR和/或IIR任务从内核转移给加速器,并允许内核同时执行其他操作。但在实践中,这并非始终可行,特别是当内核需要使用加速器输出进一步处理,并且没有其他独立的任务需要同时完成时。在这种情况下,我们需要选择合适的加速器使用模型来达到最佳效果。.
在本文中,我们将讨论针对不同应用场景充分利用这些加速器的各种模型。
实时使用FIRA和IIRA

图2.典型实时音频数据流。
图2显示了典型实时PCM音频数据流图。一帧数字化PCM音频数据通过同步串行端口(SPORT)接收,并通过直接存储器访问(DMA)发送至存储器。在继续接收帧N+1时,帧N由内核和/或加速器处理,之前处理的帧(N-1)的输出通过SPORT发送至DAC进行数模转换。
加速器使用模型
如前所述,根据应用的不同,可能需要以不同的方式使用加速器,以最大限度分担FIR和/或IIR处理任务,并尽可能节省内核周期以用于其他操作。从高层次角度来看,加速器使用模型可分为三类:直接替代、拆分任务和数据流水线。
直接替代
内核FIR和/或IIR处理直接被加速器替代,内核只需等待加速器完成此任务。
此模型仅在加速器的处理速度比内核快时才有效;即,使用FIRA模块。
拆分任务
FIR和/或IIR处理任务在内核和加速器之间分配。
当多个通道可并行处理时,此模型特别有用。
根据粗略的时序估算,在内核和加速器之间分配通道总数,使二者大致能够同时完成任务。
如图3所示,与直接替代模型相比,此使用模型可节省更多的内核周期。
数据流水线
内核和加速器之间的数据流可进行流水线处理,使二者能够在不同数据帧上并行处理。
如图3所示,内核处理第N个帧,然后启动加速器对该帧进行处理。内核随后继续进一步并行处理加速器在上一迭代中产生的第N-1帧的输出。该序列允许将FIR和/或IIR处理任务完全转移给加速器,但输出会有一些延迟。
流水线级以及输出延迟都可能会增加,具体取决于完整处理链中此类FIR和/或IIR处理级的数量。
图3说明了音频数据帧如何在不同加速器使用模型的三个阶段之间传输---DMA IN、内核/加速器处理和DMA OUT。它还显示了通过采用不同的加速器使用模型将FIR/IIR全部或部分处理转移到加速器上,与仅使用内核模型相比,内核空闲周期如何增加。

图3.加速器使用模型比较。
SHARC处理器上的FIRA和IIRA
以下ADI SHARC处理器系列支持片内FIRA和IIRA(从旧到新)。
ADSP-214xx(例如,ADSP-21489)
ADSP-SC58x
ADSP-SC57x/ADSP-2157x
ADSP-2156x
这些处理器系列:
计算速度不同
基本编程模型保持不变,ADSP-2156x处理器上的自动配置模式(ACM)除外。
FIRA有四个MAC单元,而IIRA只有一个MAC单元。
ADSP-2156x的FIRA/IIRA改进
ADSP-2156x是SHARC处理器系列中的最新的产品。它是第一款单核1 GHz SHARC处理器,其FIRA和IIRA也可在1 GHz下运行。ADSP-2156x处理器上的FIRA和IIRA与其前代ADSP-SC58x/ADSP-SC57x处理器相比,具有多项改进。
性能改进
计算速度提高了8倍(从SCLK-125 MHz至CCLK-1 GHz)。
由于内核和加速器借助专用内核结构实现了更紧密的集成,因此减少了内核和加速器之间的数据和MMR访问延迟。
功能改进
添加了ACM支持,以尽量减少进行加速器处理所需的内核干预。此模式主要具有以下新特性:
允许加速器暂停以进行动态任务排队。
无通道数限制。
支持触发生成(主器件)和触发等待(从器件)。
为每个通道生成选择性中断。
实验结果
在本节中,我们将讨论在ADSP-2156x评估板上,借助不同的加速器使用模型实施两个实时多通道FIR/IIR用例的结果
用例1
图4显示用例1的方框图。采样率为48 kHz,模块大小为256个采样点,拆分任务模型中使用的内核与加速器通道比为5:7。
表1显示测得的内核和FIRA MIPS数量,以及与仅使用内核模型相比获得的节约内核MIPS结果。表中还显示了相应使用模型增加的额外输出延迟。正如我们所看到的,使用加速器配合数据流水线使用模型,可节约高达335内核MIPS,但导致1块(5.33 ms)的输出延迟。直接替代和拆分任务使用模型也分别可节约98 MIPS和189 MIPS,而且未导致任何额外的输出延迟。

图4.用例1方框图。

表1.用例1的内核和FIR/IIRA MIPS总结
用例2
图5显示用例2的方框图。采样率为48 kHz,模块大小为128个采样点,拆分任务模型中使用的内核与加速器通道比为1:1。
与表1一样,表2也显示了此用例的结果。正如我们所看到的,使用加速器配合数据流水线使用模型,可节约高达490内核MIPS,但导致1模块(2.67 ms)的输出延迟。拆分任务使用模型可节约234内核MIPS,而没有导致任何额外输出延迟。请注意,与用例1中不同,在用例2中内核使用频域(快速卷积)处理,而非时域处理。这就是为何处理一个通道所需的内核MIPS比FIRA MIPS少的原因,这可导致直接替代使用模型实现负的内核MIPS节约。

图5.用例2方框图。
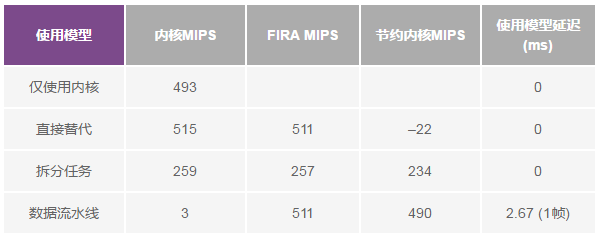
表2.用例2的内核和FIR/IIRA MIPS总结
结论
在本文中,我们看到如何利用不同的加速器使用模型实现所需的MIPS和处理目标,从而将大量内核MIPS转移到ADSP-2156x处理器上的FIRA和IIRA加速器。
-
数字信号
+关注
关注
2文章
970浏览量
47551 -
音频处理
+关注
关注
0文章
85浏览量
17775
原文标题:如何解放你的内核?硬件加速器“使用指南”奉上
文章出处:【微信号:analog_devices,微信公众号:analog_devices】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
《CST Studio Suite 2024 GPU加速计算指南》

适用于数据中心应用中的硬件加速器的直流/直流转换器解决方案

图形图像硬件加速器卡设计原理图:270-VC709E 基于FMC接口的Virtex7 XC7VX690T PCIeX8 接口卡
西门子推出Catapult AI NN软件,赋能神经网络加速器设计
PSoC 6 MCUBoot和mbedTLS是否支持加密硬件加速?
Elektrobit利用其首创的硬件加速软件优化汽车通信网络的性能

330-基于FMC接口的Kintex-7 XC7K325T PCIeX4 3U PXIe接口卡 图形图像硬件加速器
【国产FPGA+OMAPL138开发板体验】(原创)7.硬件加速Sora文生视频源代码
音视频解码器硬件加速:实现更流畅的播放效果






 工商网监
工商网监
评论