 PostgreSQL的全局死锁检测原理
PostgreSQL的全局死锁检测原理
5月26日,一年一度的PG开发者大会PGCon2020如约而至。与往年不同的是,受疫情的影响,今年的PGCon采取了线上会议的方式,虽然没有了面对面的交流,但在组织者Dan Langille等的精心安排下,会议有了更广泛的受众,干货满满。来自Greenplum原厂的Greenplum内核工程师 Hubert Zhang(张桓)与Asim Praveen合作发表了演讲《Distributed Snapshot and Global Deadlock Detector》。在演讲中Hubert通过理论结合实例的方式讲解了Postgres单节点死锁和Postgres Foreign Server Cluster中实现分布式死锁检测的技术路线。
现在让我们通过本文来回顾一下精彩的演讲内容吧!
在大数据时代,随着数据量的爆发式增长,对于分布式数据库的需求亦是水涨船高。作为最出色的开源数据库之一,Postgres也在大力探索和发展分布式解决方案。其中,Postgres Foreign Server Cluster是目前Postgres开发者邮件列表Pghacker中非常活跃的关于分布式Postgres的话题,该方案通过Foreign Data Wrapper和分区表的技术,支持将逻辑分区表,物理的存储在多个不同的Postgres节点上。为了保证分布式环境中事务的ACID,Postgres社区正在积极开发基于Foreign Server Cluster的分布式事务相关patch(https://commitfest.postgresql.。.。
但对于分布式系统来讲,除了支持分布式事务,还需要考虑全局快照,全局死锁检测等问题。Greenplum作为分布式Postgres的先驱者和成功代表,在Postgres分布式执行的诸多领域都拥有成熟、稳定的解决方案。因此,本次演讲的作者Hubert借鉴Greenplum中全局死锁检测的原理和实现,探讨了在Postgres Foreign Server Cluster中如何实现一个高效的分布式死锁检测系统。
单节点死锁原理
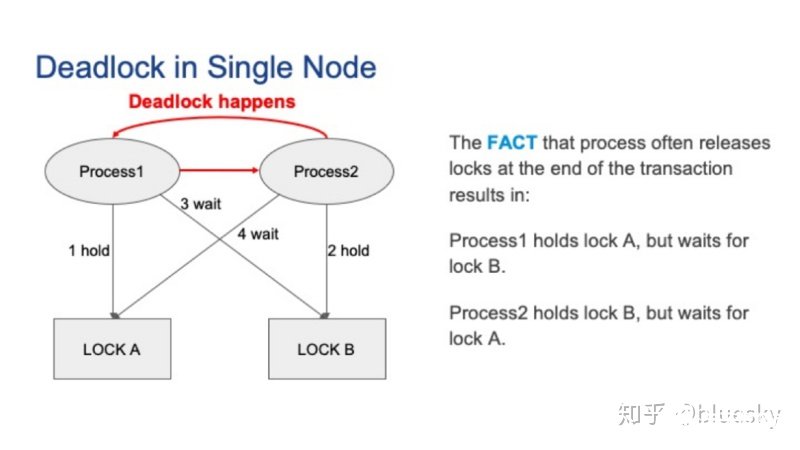
首先,让我们先来看一看单节点死锁。下图是一个单节点死锁的示例。假设有两个并发的Postgres会话,对应两个Postgres的后端进程。最初,进程1持有锁A,进程2持有锁B。接着,进程1要获取锁B,而进程2要获取锁A。由于锁通常在事务结束时才被释放,因此,本地发生死锁。
Postgresql 死锁检测器
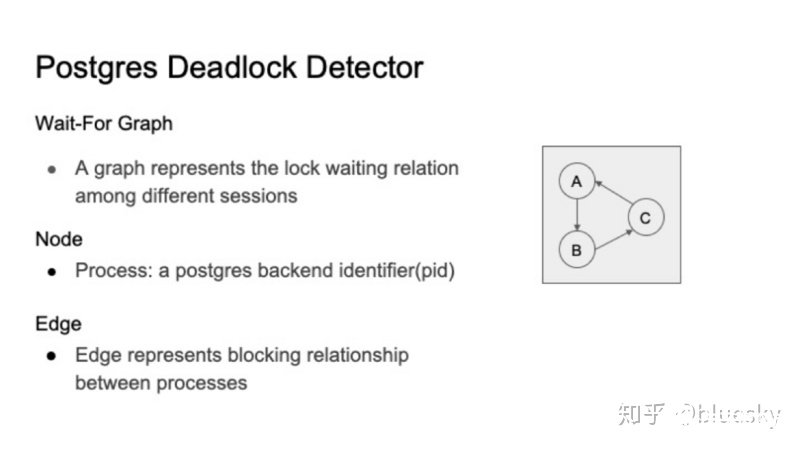
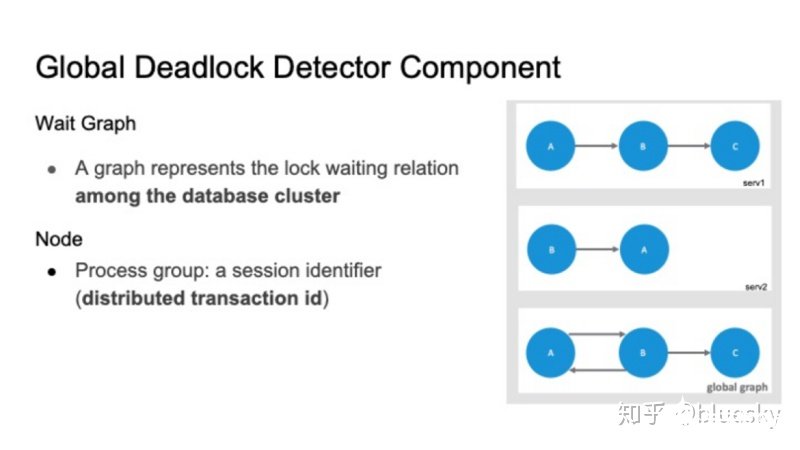
Postgres使用死锁检测器来处理死锁问题。死锁检测器负责检测死锁并打破死锁。检测器使用等待图(wait-for graph)来为不同后端进程之间的等待关系建模。图的节点由进程标识符pid标识。节点A到节点B的边表示节点A正在等待由节点B持有的锁。
Postgresql死锁检测器的基本思想如下:
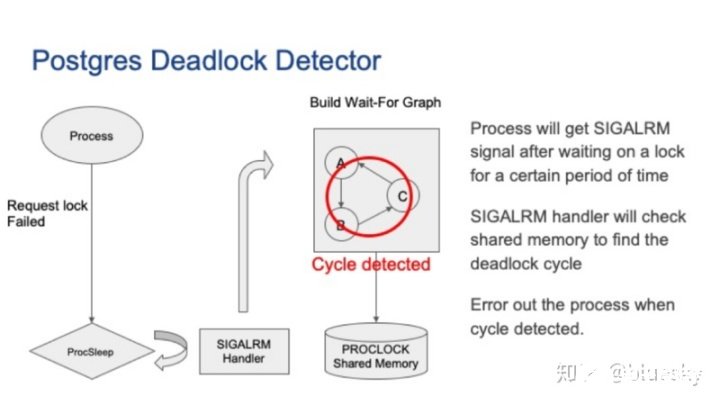
如果获取锁失败,进程将进入睡眠模式。
SIGALARM处理程序将检查PROCLOCK共享内存以构建等待图。以当前进程为起点,检查是否存在环。环意味着发生死锁。当前进程会主动退出以打破死锁。Postgres死锁检测器可以处理本地死锁问题。
分布式集群中的死锁
那么分布式集群中的死锁又是怎么样的?集群和单节点有什么区别?
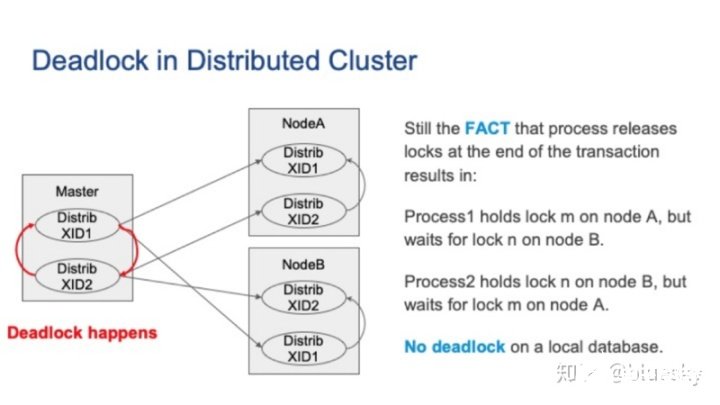
让我们从一个例子开始进行讲解。下图中,我们有包含一个主节点和两个从节点的集群。假设我们有两个并发的分布式事务。首先,分布式事务1在节点A上运行,然后事务2在节点B上运行。接着,事务1要在由事务2阻塞的节点B上运行,因此分布式事务1将被挂起。同时,假设事务2也尝试在被本地事务1阻塞的节点A上运行,则分布式事务2也将挂起。这种情况下就会发生死锁。
请注意,节点A或节点B上都没有死锁,但是死锁确实出现了。从主节点的角度来看,这就是所谓的全局死锁。
现在,让我们看一个更具体的 Postgres Foreign Server Cluster示例。在下图中,我们有两个外部服务器,它们充当了在上一张图中的从节点的角色。在主Postgres服务器上,我们创建一个分区表,在外部服务器A上部署一个分区,在外部服务器B上也部署一个分区。接着我们插入一些行,其中某些行在外部服务器A上,而其他行在外部服务器B上。
分布式系统中的全局死锁检测器
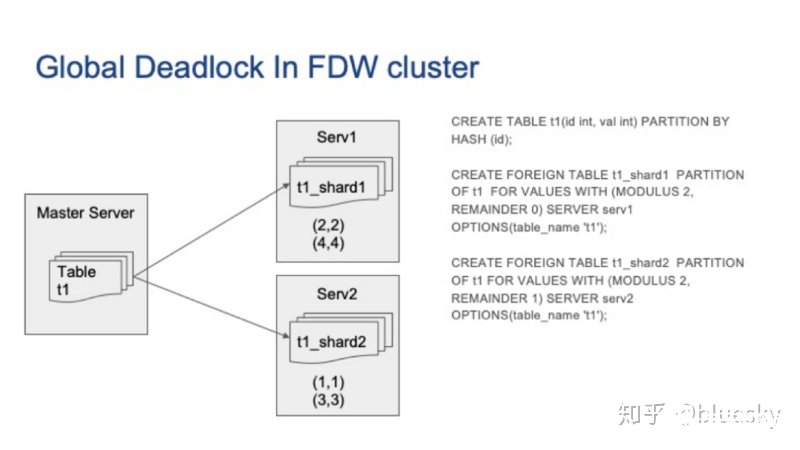
接着,我们在两个并发会话上运行以下更新查询,我们可以看到两个会话都由于死锁而挂起。但是每个外部服务器上的本地Postgres死锁检测器却无法检测到它们。
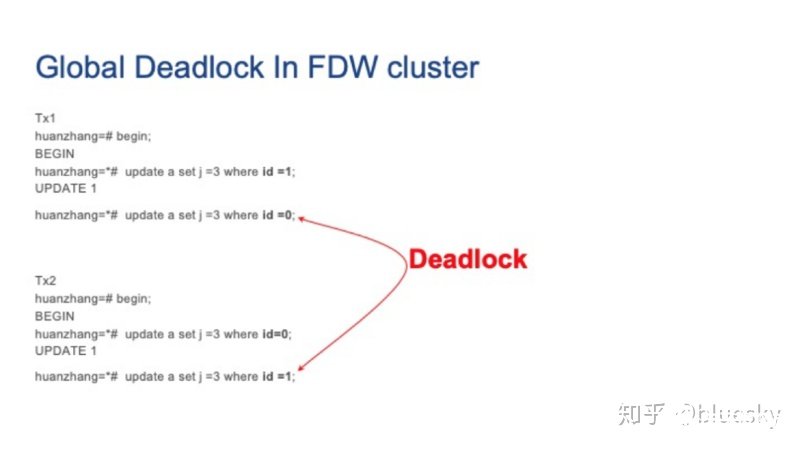
那么我们应该如何解决这种死锁问题呢?答案就是——在分布式系统中引入全局死锁检测器。
在本演讲中,我们将提出一个关于如何在Postgres fdw集群中实现全局死锁检测器的想法。但是这个概念很普遍,可以作为对其他Postgres集群实现的参考。实际上,我们参考了Greenplum全局死锁检测器的实现。首先,将全局死锁检测器实现为Postgres的Background Worker,使其更兼容Postgres,高可用等需求都可以通过Postgres的Background Worker来实现。其次,我们提出使用集中式检测算法,这意味着我们只需要在主节点上启动一个工作进程来收集事务等待关系并定期检测死锁。请注意,在Postgres的本地死锁检测器中,Postgres后端进程以自己为起点检测死锁。由于我们使用全局检测器,因此必须执行完整的等待图搜索以检测死锁。这需要一种更好的算法来检测死锁,因为Postgres的基于每个顶点的查找环算法并不高效。

全局死锁检测器模块
1. 等待图
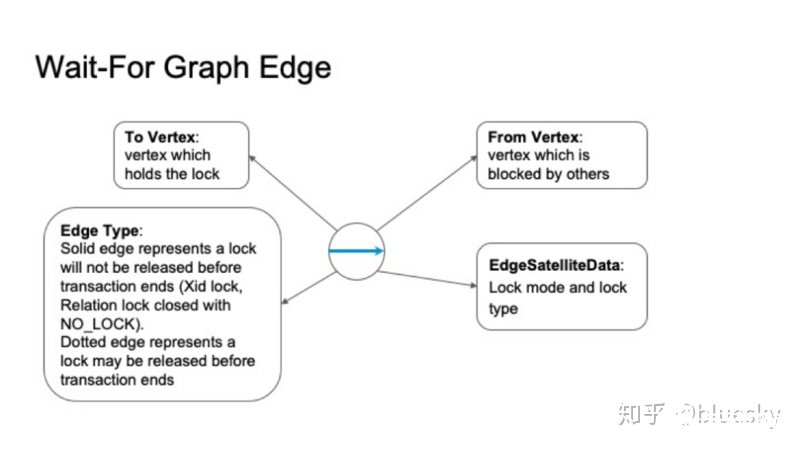
全局死锁检测器仍会使用等待图(wait for graph)来为锁等待关系进行建模。但与Postgres本地死锁检测有所不同的是,首先,等待图是基于整个集群,因此我们需要将每个外部服务器上的本地等待图进行合并,生成全局图。此外,该等待图中的节点并不再是单个Postgres进程ID,而是一个进程组,我们使用分布式事务ID来表示一个等待图中节点。
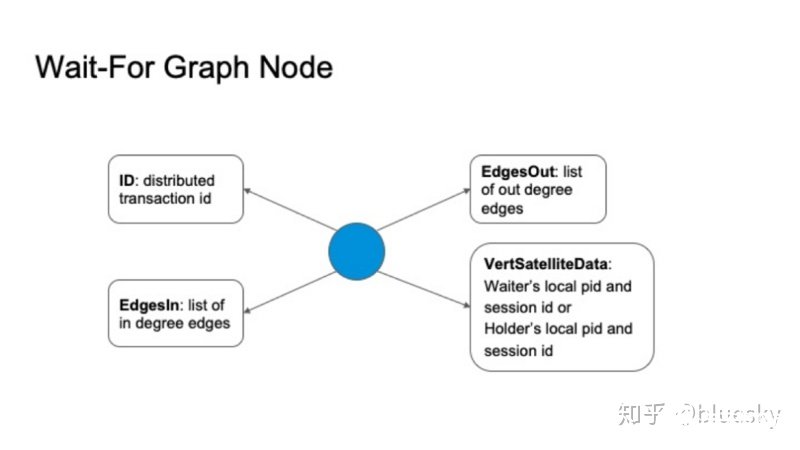
等待图中的节点具有四个主要属性:
分布式事务ID。
出度边列表
入度边列表
锁等待者或持有者的pid和sessionid信息。
从节点出发的是等待锁的,指向节点的是持锁者。
2. 等待图边
等待图中的边表示任何节点上的锁等待关系。边同样具有四个主要属性:
出度节点,持有锁。
入度节点,等待锁。
边类型:并非所有锁在事务结束时都被释放,例如,xidlock可以提前释放,而无需等待分布式事务提交。我们将这种提前结束的等待关系使用虚边表示。与之对应的是实边,事务结束使才释放的锁等待关系。稍后,我们将展示全局死锁检测算法中对这两种边的不同处理。
锁等待关系中的锁模式和锁类型。
全局死锁检测器工作原理
下面,通过全局等待图,让我们看看集群是如何处理全局死锁的。
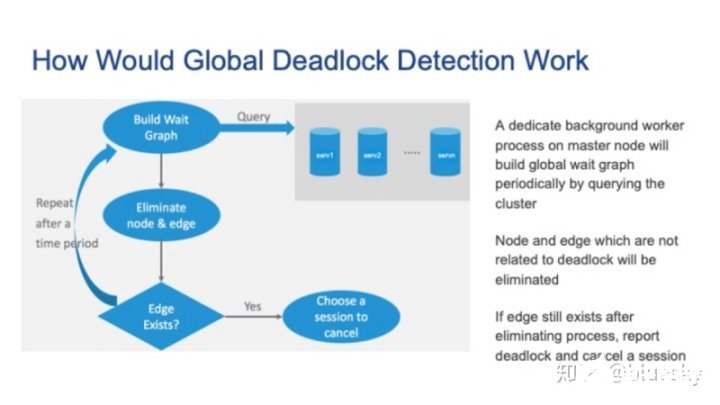
基本思路如下:主节点上的Background Worker进程通过查询集群来定期建立全局等待图。接着,删除与死锁无关的节点和边。重复此过程,直到无法删除任何节点或边。如果仍然存在边,则也存在全局死锁,我们需要选择一个会话来取消。
接下来,让我们详细介绍上述步骤。
要构建等待图,我们需要在每个Segment上收集锁信息。这是一个两阶段过程。
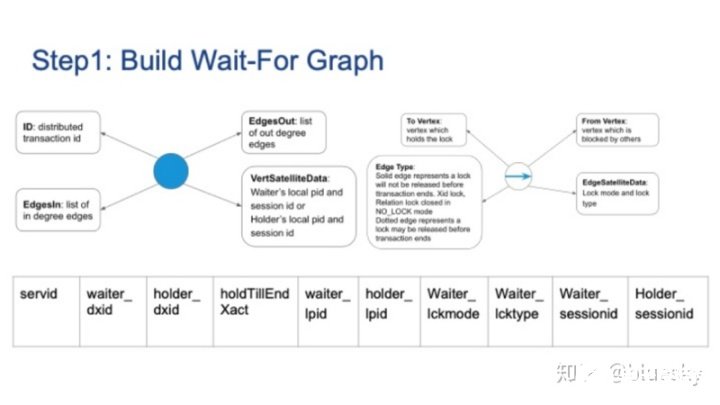
1. 构建全局图
首先,它使用Postgres内部函数GetLockStatusData从PROCLOCK共享内存中获取锁等待关系。我们需要扩展lockInstanceData结构,以涵盖分布式事务ID和holdTillEndXact标志。之后,Background Worker进程需要从每个Foreign Server收集本地锁信息,并形成一个全局锁等待图。

每个本地锁等待图包括以下属性:Segment ID,锁等待者和锁持有者的分布式事务ID,标注其为实边或虚边,以及其他属性,例如pid,sessionid,锁类型和锁模式,涵盖了之前介绍的节点和边的四个主要属性。
2. 消除节点和边
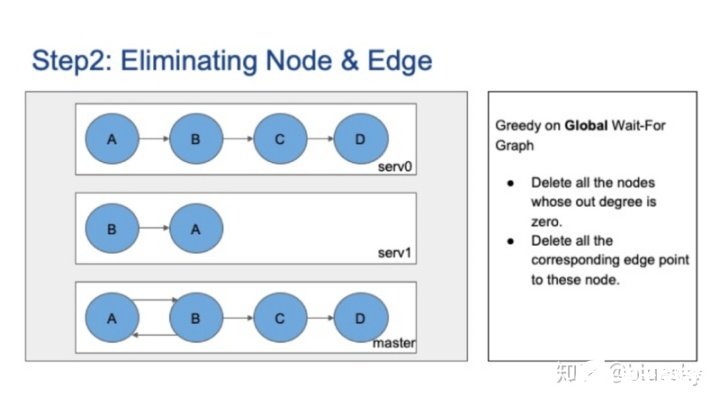
下一步是消除不相关的节点和边。我们使用启发式贪婪算法。
有两种策略。一种是对全局图的贪婪,这意味着删除所有出节点度为零的节点,并删除其相应边。这是一个示例,在全局图上,节点D没有出度,因此将其删除。然后,节点C的出站度也更改为零,因此也删除了节点C。
另一种策略是在局部图上贪婪,这意味着找到每个局部图上的所有虚边。如果虚边指向节点的出度为零,则该虚线边表示的阻塞关系可能在事务结束之前消失,因此我们也可以消除这种虚边。
下图的示例中,节点C在全局图上的出度为1,但是在Server0的局部图上,出度为0,因此我们可以将从节点A到C的虚边删除。
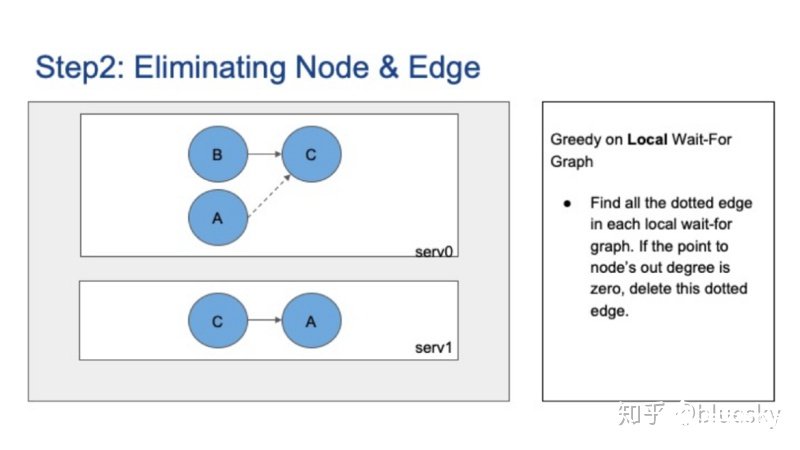
全局死锁检测器的最后一步是打破死锁。集中式检测器不同于Postgres本地死锁检测器,后者只能退出当前进程,前者可以根据策略选择取消任何会话。通用策略包括取消最新的会话或基于CPU、内存等资源占用量的策略等等。
实例分析
至此,我们已经介绍了全局死锁检测器的概述和算法。最后,让我们看看另外两种实例,以便更好地了解全局死锁检测器的工作原理。
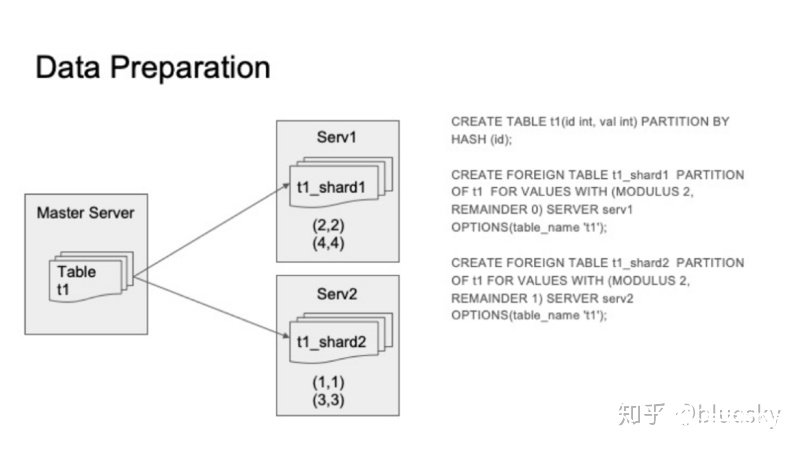
首先是数据准备工作,如下图所示。
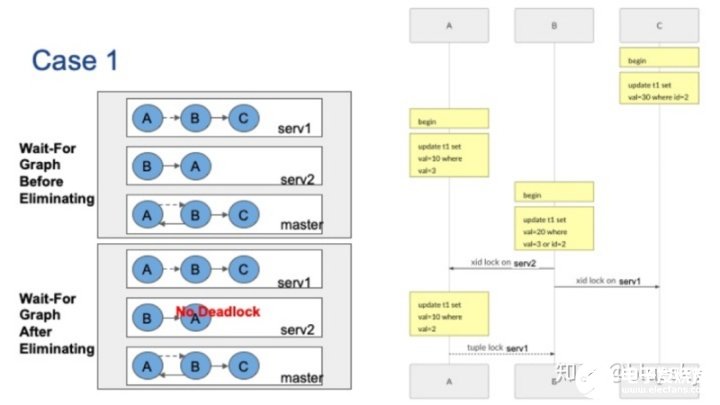
案例一
第一种例子中,有三个并发会话。会话C首先更新ID=2的元组,这将使server1上持有xid锁。会话A更新val=3的元组,它将在server2上持有xid锁。接着,会话B要更新val=3或id=2的元组,它将分别被server1和server2上的会话A和会话C阻塞。最后,会话A要更新server1上val=2的元组。
请注意,当会话B无法获取server1上的xid锁时,它将持有元组锁,以确保在会话C释放xid锁之后可以拿到锁。会话A将在元组锁上被会话B阻塞。请注意,元组锁在分布式事务结束之前就会被释放,因此这是一个虚边。原始的全局等待图在左上角,可以看到全局等待图存在循环。
现在,让我们看看如何消除不相关的节点。首先,节点C的出度为零,我们可以删除该节点和相应的边。现在在Server1的本地等待图上,指向B点的虚边没有出度,因此也可以删除该虚边。删除虚边后,节点A的出度变为零,可以删除,最后也可以删除节点B。没有边,因此在这种情况下没有全局死锁。
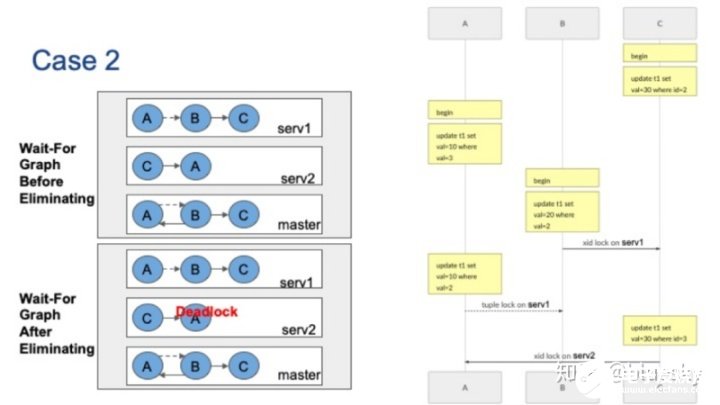
案例二
下图的第二个例子中,包括三个并发会话。会话C首先将更新ID=2的元组,这将在server1上持有xid锁。然后,会话A将更新val=3的元组,它将在server2上持有xid锁。会话B要更新val=2的元组,它将被server1上的会话C阻止。
接着,会话A想要更新server1上val=2的元组。像上图的案例1一样,会话A在元组锁上被会话B阻塞,并形成虚边。最后,会话C要更新ID=3的元组,它将被Server2上持有xid锁的会话A阻止。原始全局等待图在左上角,全局等待图同样包含循环。
回想上一张图,案例1的全局等待图与案例2相同,唯一的不同是局部图。
现在让我们看看如何消除不相关的节点。首先,让我们检查全局图:没有出节点度数为零的节点,因此没有可以删除的节点。接下来,我们检查局部图上的虚边。从节点A到节点B,我们有一条虚边,但是节点B的出度不为零,因此无法删除该虚边。我们无法删除任何节点或边,因此在这种情况下消除失败,全局死锁存在。
从以上情况可以得出结论,即使全局等待图相同,它们的全局死锁检测结果也会有所不同。
总结
以上就是本次PGCon演讲的主要内容。回顾一下,本次演讲首先讨论Postgres本地死锁检测器的实现,并通过实例说明本地死锁检测器无法解决全局死锁问题,并进一步提出了在Postgres Foreign Server Cluster中实现全局死锁检测的思路和需要注意的问题。
-
检测器
+关注
关注
1文章
864浏览量
47698 -
建模
+关注
关注
1文章
307浏览量
60777 -
进程
+关注
关注
0文章
203浏览量
13962
发布评论请先 登录
相关推荐
onsemi全局快门图像传感器—了解图像传感器的选型要点

PostgreSQL将不再支持MD5密码
MySQL还能跟上PostgreSQL的步伐吗

求助,是否有自带timeout机制的EEPROM?
HarmonyOS实战开发-全局状态保留能力弹窗
你是不是也没躲过这个坑?用了太多全局变量......

全局变量太多有哪些弊端?
纵观全局:YOLO助力实时物体检测原理及代码
浅谈MySQL常见死锁场景






 工商网监
工商网监
评论