 论Linux的页迁移(Page Migration)
论Linux的页迁移(Page Migration)
对于用户空间的应用程序,我们通常根本不关心page的物理存放位置,因为我们用的是虚拟地址。所以,只要虚拟地址不变,哪怕这个页在物理上从DDR的这里飞到DDR的那里,用户都基本不感知。那么,为什么要写一篇论述页迁移的文章呢?
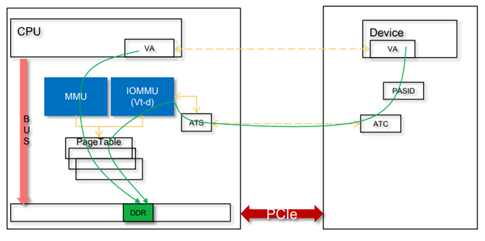
我认为有2种场景下,你会关注这个Page迁移的问题:一个是在Linux里面写实时程序,尤其是Linux的RT补丁打上后的情况,你希望你的应用有一个确定的时延,不希望跑着跑着你的Page正在换位置而导致的延迟;再一个场景就是在用户空间做DMA的场景,尤其是SVA(SharedVirtual Addressing),设备和CPU共享页表,设备共享进程的虚拟地址空间的场景,如果你DMA的page跑来跑去,势必导致设备DMA的暂停,设备的传输性能出现严重抖动。这种场景下,设备的IOMMU和CPU的MMU会共享Page table:
1.CoW导致的页面迁移
1.1 fork
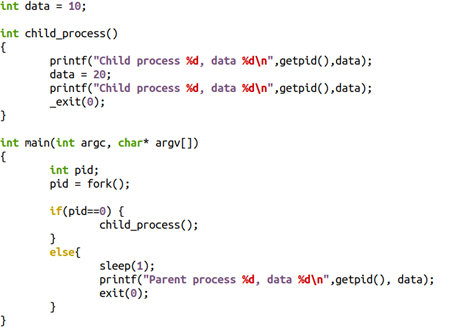
典型的CoW(写时拷贝)与fork()相关,当父子兄弟进程共享一部分page,而这些page本身又应该是具备独占属性的时候,这样的page会被标注为只读的,并在某进程进行写动作的时候,产生page fault,其后内核为其申请新的page。比如下面的代码中,把10写成20的进程,在写的过程中,会得到一页新的内存,data原本的虚拟地址会指向新的物理地址,从而发生page的migration。
1.2 KSM
其他的CoW的场景有KSM(Kernel same-page merging)。KSM会扫描多个进程的内存,如果发现有page的内容是一模一样的,则会将其merge为一个page,并将其标注为写保护的。之后对这个page执行CoW,谁写谁得到新的拷贝。比如,你在用qemu启动一个虚拟机的时候,使用mem-merge=on,就可以促使多个VM共享许多page,从而有利于实现“超卖”。
sudo /x86_64-softmmu/qemu-system-x86_64 -enable-kvm -m 1G -machinemem-merge=on
不过这本身也引起了虚拟机的一些安全漏洞,可被side-channel攻击。
比如,把下面的代码编译为a.out,并且启动两份a.out进程
./a.out&./a.out
代码:
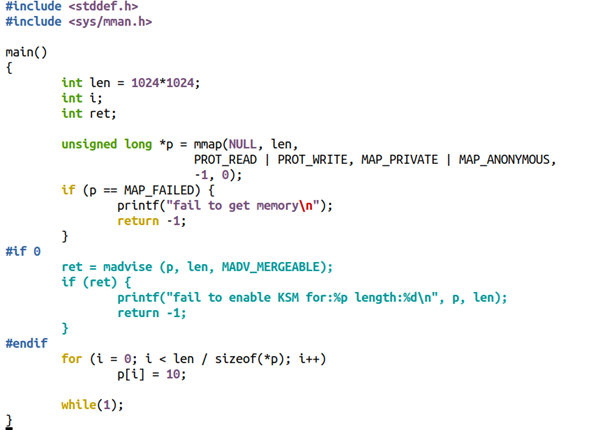
我们看到这2个a.out的内存消耗情况如下:

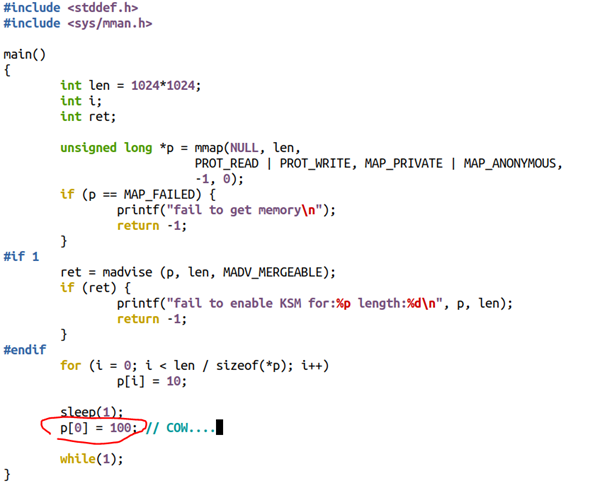
但是,如果我们把中间的if0改为if 1,也就是暗示mmap()的这1MB内存可能要merge,则耗费内存的情况发生显著变化:

耗费的内存大大减小了。
我们可以看看pageshare的情况:

Merge发生在进程内部,也发生在进程之间。
当然,如果在page已经被merge的情况下,谁再写merge过的page,则会引起写时拷贝,比如如下代码中的p[0]=100这句话。
2.内存规整导致的页面迁移
2.1 CMA引起的内存迁移
CMA (TheContiguousMemory Allocator)可运行作为dma_alloc_coherent()的后端,它的好处在于,CMA区域的空闲部分,可以被应用程序拿来申请MOVABLE的page。如下图中的一个CMA区域的红色部分已经被设备驱动通过dma_alloc_coherent()拿走,但是蓝色部分目前被用户进程通过malloc()等形式拿走。
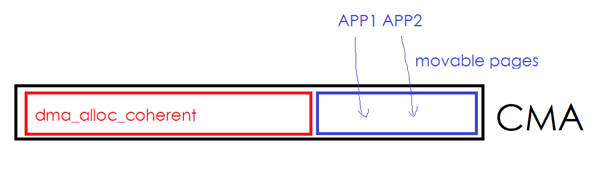
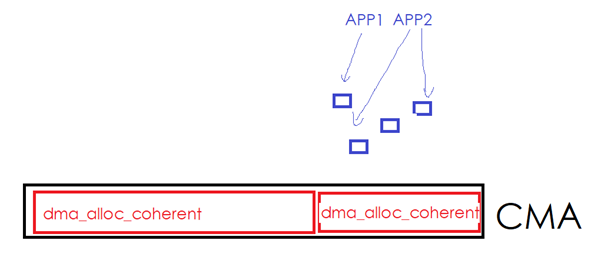
一旦设备驱动继续通过dma_alloc_coherent()申请更多的内存,则内核必须从别的非CMA区域里面申请一些page,然后把蓝色的区域往新申请的page移走。用户进程占有的蓝色page发现了迁移。
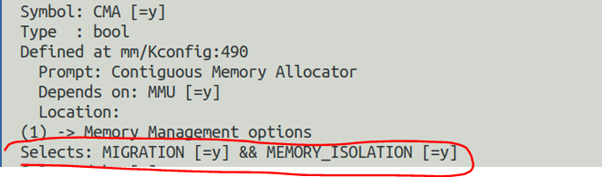
CMA在内核的配置选项中依赖于MMU,且会自动使能MIGRATION(Pagemigration)和MEMORY_ISOLATION:
2.2 alloc_pages
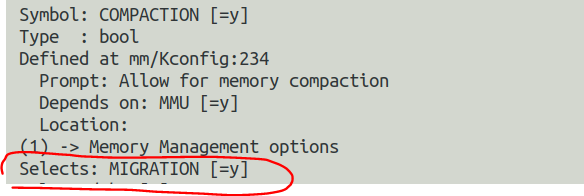
当内核使能了COMPACTION,则Linux的底层buddy分配器会在alloc_pages()中尝试进行内存迁移以得到连续的大内存。COMPACTION这个选项也会使能CMA一节提及的MIGRATION选项。
从代码的顺序上来看,alloc_pages()分配order比较高的连续内存的时候,是优先考虑COMPACTION,再次考虑RECLAIM的。
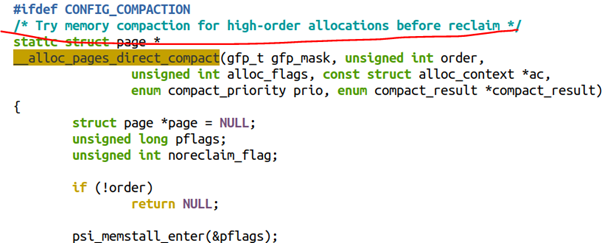
2.3 /proc/sys/vm/compact_memory
当然,上面alloc_pages所提及的compaction也可以被用户手动的触发,触发方式:
echo 1 >/proc/sys/vm/compact_memory
将1写入compact_memory文件,则内核会对各个zone进行规整,以便能够尽可能地提供连续内存块。
我的Ubuntu已经运行了一段时间,内存稍微有些碎片化了,我们来对比下手动执行
compact_memory前后,buddy的情况:

可以清晰地看出来,执行compact_memory后,DMA32 ZONE和NORMAL ZONE里面,order比较大的连续page数量都明显增大了。
2.4 huge page
再次展开内核的COMPACTION选型,你会发现COMPACTION会被透明巨页自动选中:
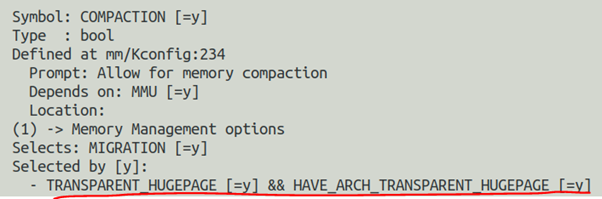
这说明透明巨页是依赖于COMPACTION选项的。
所谓透明巨页,无非就是应用程序在运行的时候,神不知鬼不觉地偷偷地就使用到了Hugepage的功能,这个过程对用户是透明的。与透明对应的无非就是不透明的巨页,这种方式下,应用程序需要显示地告诉内核我需要使用巨页。
我们先来看看不透明的巨页是怎么玩的?一般用户程序可以这样写,在mmap里面会加上MAP_HUGETLB的Flag,当然这个巨页也必须是提前预设好的,否则mmap就会失败。
ptr_ = mmap(NULL, memory_size_, PROT_READ | PROT_WRITE, MAP_PRIVATE | MAP_ANONYMOUS | MAP_HUGETLB, -1, 0);
比如下面的代码我们想申请2MB的巨页:
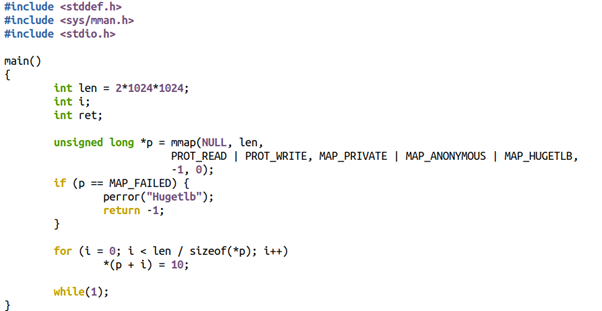
程序执行的时候会返回错误,打印如下:
$ ./a.out Hugetlb:Cannotallocatememory
原因很简单,因为现在系统里面2MB的巨页数量和free的数量都是0:

我们如何让它申请成功呢?我们首先需要保证系统里面有一定数量的巨页。这个时候我们可以写nr_hugepages得到巨页:

我们现在让系统得到了10个大小为2048K的巨页。
现在来重新运行a.out,就不在出错了,而且系统里面巨页的数量发生了变化:

Free的数量从10页变成了9页。
聪明的童鞋应该想到了,当我们尝试预留巨页的时候,它最终还是要走到buddy,假设系统里面没有连续的大内存,系统是否会进行内存迁移以帮忙规整出来巨页呢?这显然符合前面说的alloc_pages()的逻辑。从alloc_buddy_huge_page()函数的实现也可以看出这一点:
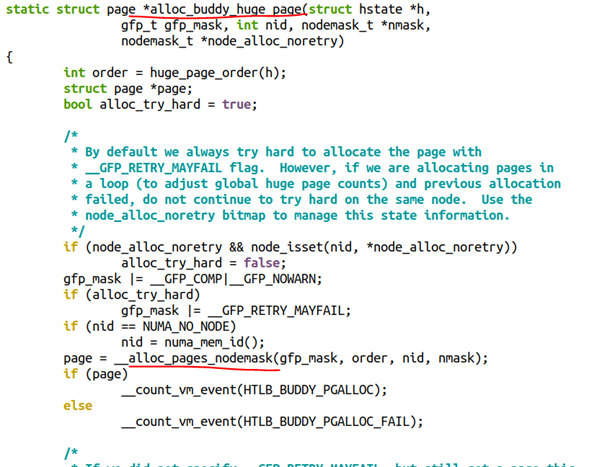
另外,这种巨页的特点是“预留式”的,不会free给系统,也不会被swap。因此可有效防止用户态DMA的性能抖动。对于DPDK这样的场景,人们喜欢这种巨页分配,减少了页面的数量和TLB的miss,缩短了虚拟地址到物理地址的重定位的转换时间,因此提高了性能。
当然,我们在运行时通过写nr_hugepages的方法设置巨页,这种方法未必一定能够成功。所以,工程中也可以考虑通过内核启动的bootargs来设置巨页,这样Linux开机的过程中,就可以直接从bootmem里面分配巨页,而不必在运行时通过order较高的alloc_pages()来获取。这个在内核文档的kernel-parameters.txt说的比较清楚,你可以在bootargs里面设置各种不同hugepagesize有多少个页数:
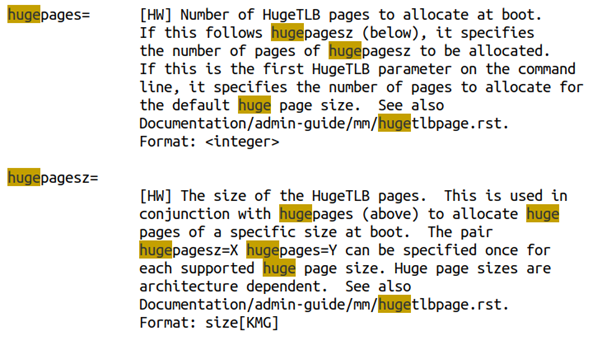
透明巨页听起来是比较牛逼的,因为它不需要你在应用程序里面通过MAP_HUGETLB来显式地指定,但是实际的使用场景则未必这么牛逼。
使用透明巨页的最激进的方法莫过于把enabled和defrag都设置为always:
echo always >/sys/kernel/mm/transparent_hugepage/enabledechoalways>/sys/kernel/mm/transparent_hugepage/defrag
enabled写入always暗示对所有的区域都尽可能使用透明巨页,defrag写入always暗示内核会激进地在用户申请内存的时候进行内存回收(RECLAIM)和规整(COMPACTION)来获得THP(透明巨页)。
我们来前面的例子代码稍微进行更改,mmap16MB内存,并且去掉MAP_HUGETLB:

运行这个程序,并且得到它的pmap情况:
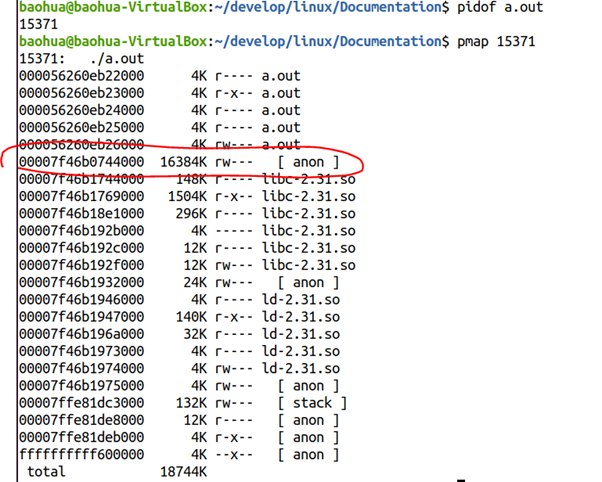
我们发现从00007f46b0744000开始,有16MB的anon内存区域,显然对应着我们代码里面的mmap(16*1024*1024)的区域。
我们进一步最终/proc/15371/smaps,可以得到该区域的内存分布情况:
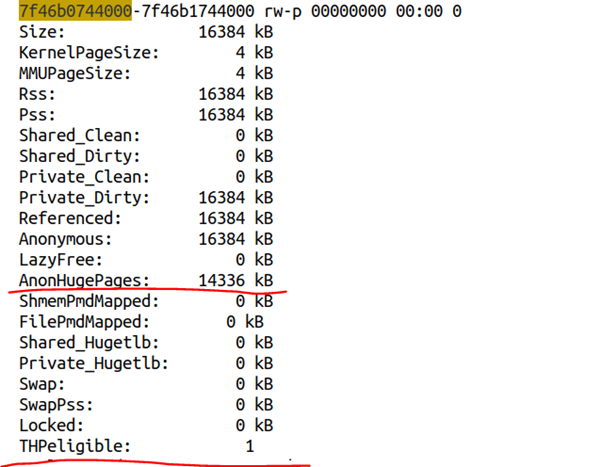
显然该区域是THPeligible的,并且获得了透明巨页。内核文档filesystems/proc.rst对THPeligible的描述如下:
"THPeligible" indicates whether the mapping is eligible for allocating THP pages - 1 if true, 0 otherwise. It just shows the current status.
透明巨页的生成,显然会涉及到前面的内存COMPACTION过程。透明巨页在实际的用户场景里面,可能反而因为内存的RECLAIM和COMPACTION而降低了性能,比如有些VMA区域的寿命很短申请完使用后很快释放,或者某些使用大内存的进程是短命鬼,进行规整花了很久,而跑起来就释放了这部分内存,显然是不值得的。类似《权力的游戏》中的夜王,花了那么多季进行内存规整准备干夜王这个透明巨页,结果夜王上来就被秒杀了,你说我花了多时间追剧冤不冤?
所以,透明巨页在实际的工程中,又引入了一个半透明的因子,就是内核可以只针对用户通过madvise()暗示了需要巨页的区间进行透明巨页分配,暗示的时候使用的参数是MADV_HUGEPAGE:

所以,默认情况下,许多系统会把enabled和defrag都设置为madvise:
echo madvise >/sys/kernel/mm/transparent_hugepage/enabledechomadvise>/sys/kernel/mm/transparent_hugepage/defrag
或者干脆把透明巨页的功能关闭掉:
echo never >/sys/kernel/mm/transparent_hugepage/enabledechonever>/sys/kernel/mm/transparent_hugepage/defrag
如果我们只对madvise的区域采用透明巨页,则用户的代码可以这么写:
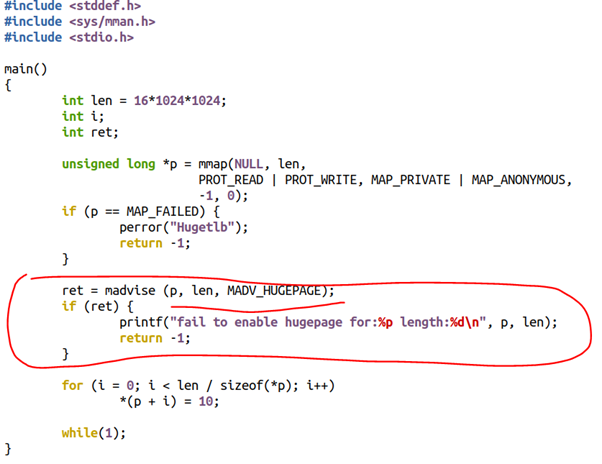
既然我都已经这么写代码了,我还透明个什么鬼?所以,我宁可为了某种确定性,而去追求预留式的,非swap的巨页了。
3.NUMABalancing引起的页面迁移
在一个典型的NUMA系统中,存在多个NODE,很可能每个NODE都有CPU和Memory,NODE和NODE之间通过某种总线再互联。下面中的NUMA系统有4个NODE,每个NODE有24个CPU和1个内存,NODE之间通过红线互联:
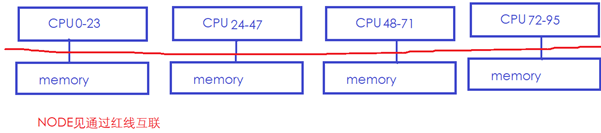
在这样的系统中,通常CPU访问本地NODE节点的memory会比较快,而跨NODE访问memory则会慢很多(红色总线慢)。所以Linux的NUMA自动均衡机制,会尝试将内存迁移到正在访问它的CPU节点所在的NODE,如下图中绿色的memory经常被CPU24访问,但是它位于NODE0的memory:
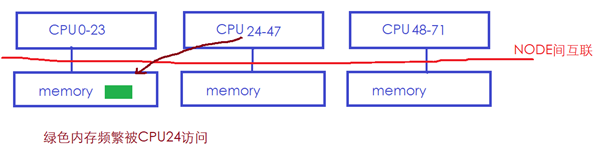
则Linux内核可能会将绿色内存迁移到CPU24所在的本地memory:
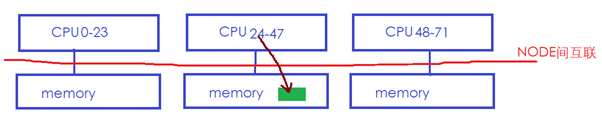
这样CPU24访问它的时候就会快很多。
显然NUMA_BALANCING也是依赖MIGRATION机制的:

下面我们来写个多线程的程序,这个程序里面有28个线程(一个主线程,26个dummy线程执行死循环,以及一个写内存的线程):

我们开那么多线程的目的,无非是为了让write_thread_start对应的线程,尽可能地不被分配到主线程所在的NUMA节点。
这个程序的主线程最开始写了64MB申请的内存,30秒后,通过write_done=1来暗示write_thread_start()线程你可以开始写了,write_thread_start()则会把这64MB也写一遍,如果主线程和write_thread_start()线程不在一个NODE节点的话,内存迁移就有可能发生。
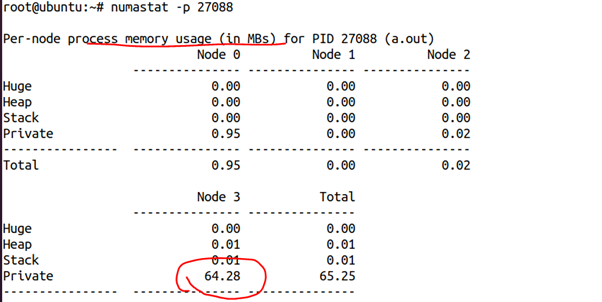
这是我们刚开始2秒的时候获得的该进程的numastat,可以看出,这64MB内存几乎都在NODE3上面:
但是30秒后,我们再次看它的NUMA状态,则发生了巨大的变化:
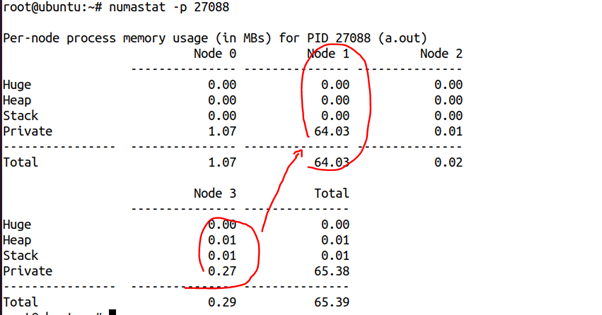
64MB内存跑到NODE1上面去了。由此我们可以推断,write_thread_start()线程应该是在NODE1上面跑,从而引起了这个迁移的发生。
当然,我们也可以通过numactl--cpunodebind=2类似的命令来规避这个问题,比如:
# numactl --cpunodebind=2 ./a.out
NUMA Balancing的原理是通过把进程的内存一部分一部分地周期性地进行unmap(比如每次256MB),在页表里面把扫描的部分的PTE设置为 “no access permission” ,以在其后访问它的时候,强制产生pagefault,进而探测page fault发生在本地NODE还是远端NODE,来获知CPU和memory是否较远的。这说明,哪怕没有真实的迁移发生,NUMA balancing也会导致进程的内存访问出现Page fault。
-
cpu
+关注
关注
68文章
10863浏览量
211799 -
Linux
+关注
关注
87文章
11304浏览量
209540 -
代码
+关注
关注
30文章
4788浏览量
68628
原文标题:宋宝华:论Linux的页迁移(Page Migration)上集
文章出处:【微信号:LinuxDev,微信公众号:Linux阅码场】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
HarmonyOS Next 应用元服务开发-应用接续动态配置迁移按需迁移页面
emc数据迁移工具的使用指南
TLV320ADC3101可以正确设置和读写PAGE0页的数据,但是读取PAGE4页上的寄存器值都为0,为什么?
云计算迁移的步骤与注意事项
请问如何设置PCM3070的EQ参数(Page44-52)并让其工作?

Linux内核中页表映射的基础知识
loongarch是如何区分大页和基本页的?
Linux内存管理之CPU本地页帧缓存
鸿蒙OS 跨设备迁移

一分钟,自动完成Redis数据迁移





 工商网监
工商网监
评论