 减少包头处理开销最直接的方法:减少数据包数量
减少包头处理开销最直接的方法:减少数据包数量
背景
目前,有大量的网络应用在处理数据包的时候只需要处理数据包头,而不会操作数据负载部分,例如防火墙、TCP/IP协议栈和软件交换机。对这类网络应用而言, 包头处理产生的开销(称为“per-packet overhead”)占了整体开销的大部分。因此,如何减少包头处理开销是优化这类应用性能的关键。
减少包头处理开销最直接的方法:减少数据包数量
如何减少包数量?
增大Maximum Transmission Unit (MTU)。在数据量一定的情况下,使用大MTU的数据包可携带更多数据,从而减少了包的总量。但MTU值依赖于物理链路,我们无法保证数据包经过的所有链路均使用大MTU。
利用网卡特性:Large Receive Offload (LRO),UDP Fragmentation Offload (UFO)和TCP Segmentation Offload (TSO)。如图1所示,LRO将从物理链路收到的TCP包(如1500B)合并为长度更长的TCP包(如64KB);UFO和TSO将上层应用发送的长数据负载的UDP和TCP包(如64KB)拆分成长度更短的数据包(如1500B),以满足物理链路的MTU限制。通过在网卡上进行包合并和拆分,在不需要任何CPU开销的情况下,上层应用就可以处理数量大大减少的大包。然而,LRO、TSO和UFO通常只能处理TCP和UDP包,而且并非所有的网卡都支持这些特性。
软件包合并 (Generic Receive Offload,GRO)和包拆分 (Generic Segmentation Offload,GSO)。与前两种方法相比,GRO和GSO有两个优点:第一,不依赖于物理链路和网卡;第二,能够支持更多的协议类型,如VxLAN和GRE。
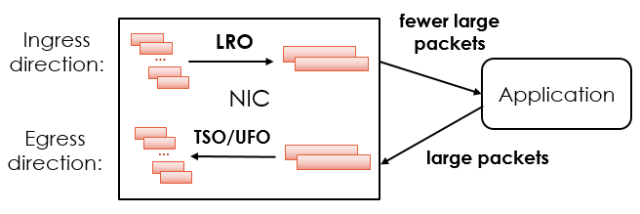
图1. LRO、UFO和TSO工作原理
为了帮助基于DPDK的应用程序(如Open vSwitch)减少包头处理开销,DPDK分别于17.08和17.11支持了GRO和GSO。如图2所示, GRO和GSO是DPDK中的两个用户库,应用程序直接调用它们进行包合并和分片。
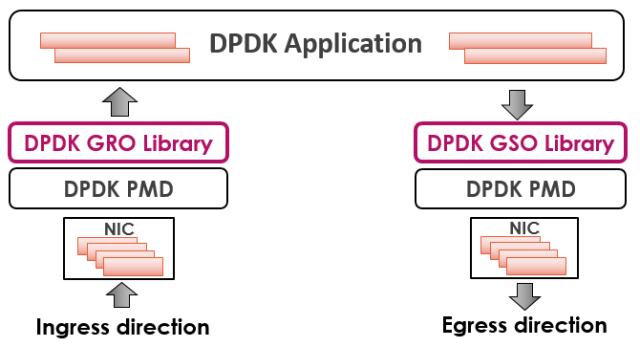
图2. DPDK GRO和DPDK GSO
1
GRO库和GSO库结构
图3描绘了GRO库和GSO库的结构。根据数据包类型,GRO库定义了不同的GRO类型。每一种GRO类型负责合并一种类型的数据包,如TCP/IPv4 GRO处理TCP/IPv4数据包。同样的,GSO库也定义了不同的GSO类型。GRO库和GSO库分别根据MBUF的packet_type域和ol_flags域将输入的数据包交给对应的GRO和GSO类型处理。
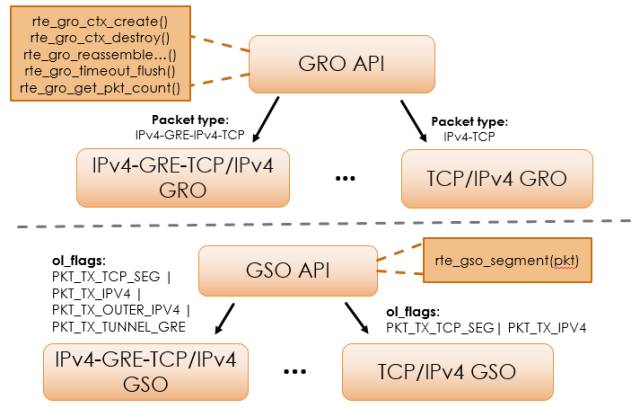
图3. GRO库和GSO库的框架
2
如何使用GRO库和GSO库?
使用GRO和GSO库十分简单。如图4所示,只需要调用一个函数便可以对包进行合并和分片。

图4. 代码示例
为了支持不同的用户场景,GRO库提供了两组API:轻量模式API和重量模式API,如图5所示。轻量模式API应用于需要快速合并少量数据包的场景,而重量模式API则用于需要细粒度地控制合包并需要合并大量数据包的场景。
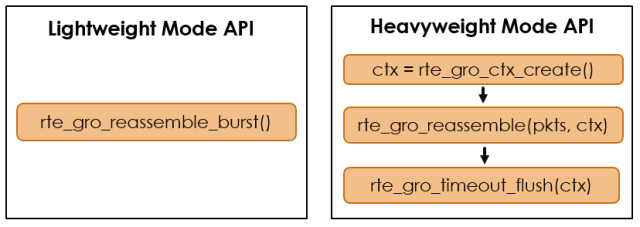
图5. 轻量模式API和重量模式API
3
DPDK GRO的合包算法
算法挑战
在高速的网络环境下,高开销的合包算法很可能会导致网卡丢包。
包乱序(“Packet Reordering”)增加了合包难度。例如Linux GRO无法合并乱序的数据包。
这就要求DPDK GRO的合包算法:
足够轻量以适应高速的网络环境
能够合并乱序包
基于Key的合包算法
为解决上述两点挑战,DPDK GRO采用基于Key的合包算法,其流程如图6所示。对新到的数据包,首先按照流(“flow”)对其进行分类,再在其所在的流中寻找相邻的数据包(“neighbor”)进行合并。若无法找到匹配的流,就插入一条新流并将数据包存储到新流中。若无法找到邻居,则将数据包存储到对应的流中。
基于Key的合包算法有两个特点。首先,通过流分类来加速数据包的合并是十分轻量的一种做法;其次,保存无法合并的数据包(如乱序包)使得之后对其进行合并成为可能,故减轻了包乱序对合包带来的影响。
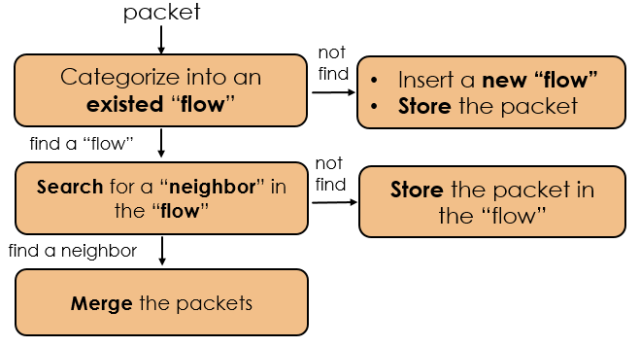
图6. 基于Key的合包算法流程
例如,TCP/IPv4 GRO使用源和目的Ethernet地址、IP地址、TCP端口号以及TCP Acknowledge Number定义流,使用TCP Sequence Number和IP ID决定TCP/IPv4包是否为邻居。若两个TCP/IPv4的数据包能够合并,则它们必须属于同一个流,并且TCP序号和IP ID必须连续。
4
DPDK GSO的分片策略
分片流程
如图7所示,将一个数据包分片有3个步骤。首先,将包的数据负载分成许多长度更小的部分;其次,为每一个数据负载部分添加包头(新形成的数据包称为GSO Segment);最后,为每个GSO segment更新包头(如TCP Sequence Number)。

图7. GSO分片流程
GSO Segment的结构
生成一个GSO Segment的最简单方法就是拷贝包头和数据负载部分。但频繁的数据拷贝会降低GSO性能,因此,DPDK GSO采用了一种基于零拷贝的数据结构——Two-part MBUF——来组织GSO Segment。如图8所示,一个Two-part MBUF由一个Direct MBUF和多个Indirect MBUF组成。Direct MBUF用来存储包头,Indirect MBUF则类似于指针,指向数据负载部分。利用Two-part MBUF,生成一个GSO Segment仅需拷贝长度较短的包头,而不需要拷贝较长的数据负载部分。

图8. Two-part MBUF的结构
GRO库和GSO库的状态
目前,GRO库还处于一个初期阶段,仅对使用最广泛的TCP/IPv4数据包提供了合包支持。GSO库则支持更丰富的包类型,包括TCP/IPv4、VxLAN和GRE。
-
cpu
+关注
关注
68文章
10922浏览量
213323 -
网卡
+关注
关注
4文章
315浏览量
27493 -
交换机
+关注
关注
21文章
2662浏览量
100259
原文标题:怎么提高网络应用性能?让DPDK GRO和GSO来帮你!
文章出处:【微信号:LinuxDev,微信公众号:Linux阅码场】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
使用tlk2711发现每次接受的数据包头对,但内容错误,为什么?
CAN通信节点多时,如何减少寄生电容和保障节点数量?

mtu配置步骤详解 mtu与数据包丢失的关系
利用P4与Vivado工具简化数据包处理设计
华纳云:服务器平均响应时间和数据包大小之间的影响
能否在ESP结束之前通过串行端口停止传入的UDP数据包的传输以解析下一个UDP数据包?
如何直接从phy mac层发送和接收802.11数据包?
请问如何使用AT CIPSEND或AT CIPSENDBUF发送多个数据包?
用ESP32-CAM和ESP-WROVER-KIT做局域网视频传输时,如何修改UDP数据包最大长度?
如何在AIROC GUI上获取良好数据包和总数据包?
请问高端网络芯片如何处理数据包呢?





 工商网监
工商网监
评论