 一款AI模型Foley Music,它可以根据演奏手势完美还原乐曲原声!
一款AI模型Foley Music,它可以根据演奏手势完美还原乐曲原声!

不会乐器也可以玩的很嗨 ”
会玩乐器的人在生活中简直自带光环!
不过,学会一门乐器也真的很难,多少人陷入过从入门到放弃的死循环。
但是,不会玩乐器,就真的不能演奏出好听的音乐了吗?
最近,麻省理工(MIT)联合沃森人工智能实验室(MIT-IBM Watson AI Lab)共同开发出了一款AI模型Foley Music,它可以根据演奏手势完美还原乐曲原声!
而且还是不分乐器的那种,小提琴、钢琴、尤克里里、吉他,统统都可以。
只要拿起乐器,就是一场专业演奏会!如果喜欢不同音调,还可以对音乐风格进行编辑,A调、F调、G调均可。
这项名为《Foley Music:Learning to Generate Music from Videos》的技术论文已被ECCV 2020收录。
接下来,我们看看AI模型是如何还原音乐的?
1
会玩多种乐器的Foley Music
如同为一段舞蹈配乐需要了解肢体动作、舞蹈风格一样,为乐器演奏者配乐,同样需要知道其手势、动作以及所用乐器。
如果给定一段演奏视频,AI会自动锁定目标对象的身体关键点(Body Keypoints),以及演奏的乐器和声音。
身体关键点:由AI系统中的视觉感知模块(Visual Perception Model)来完成。它会通过身体姿势和手势的两项指标来反馈。一般身体会提取25个关2D点,手指提起21个2D点。
乐器声音提取:采用音频表征模块(Audio Representation Model),该模块研究人员提出了一种乐器数字化接口(Musical Instrument Digital Interface,简称MIDI)的音频表征形式。它是Foley Music区别于其他模型的关键。
研究人员介绍,对于一个6秒中的演奏视频,通常会生成大约500个MIDI事件,这些MIDI事件可以轻松导入到标准音乐合成器以生成音乐波形。
在完成信息提取和处理后,接下来,视-听模块(Visual-Audio Model)将整合所有信息并转化,生成最终相匹配的音乐。
我们先来看一下它完整架构图:主要由视觉编码,MIDI解码和MIDI波形图输出三个部分构成。
视觉编码:将视觉信息进行编码化处理,并传递给转换器MIDI解码器。从视频帧中提取关键坐标点,使用GCN(Graph-CNN)捕获人体动态随时间变化产生的潜在表示。
MIDI解码器:通过Graph-Transfomers完成人体姿态特征和MIDI事件之间的相关性进行建模。Transfomers是基于编解码器的自回归生成模型,主要用于机器翻译。在这里,它可以根据人体特征准确的预测MIDI事件的序列。
MIDI输出:使用标准音频合成器将MIDI事件转换为最终的波形。
2
实验结果
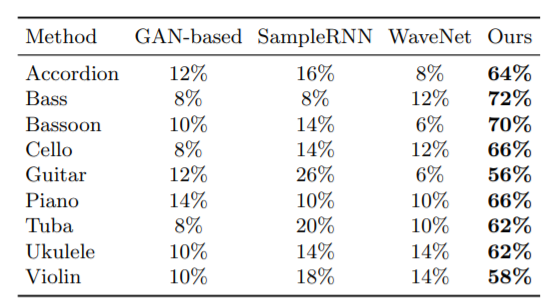
研究人员证实Foley Music远优于现有其他模型。在对比试验中,他们采用了三种数据集对Foley Music进行了训练,并选择了9中乐器,与其它GAN-based、SampleRNN和WaveNet三种模型进行了对比评估。
其中,数据集分别为AtinPiano、MUSIC及URMP,涵盖了超过11个类别的大约1000个高质量的音乐演奏视频。乐器则为风琴,贝斯,巴松管,大提琴,吉他,钢琴,大号,夏威夷四弦琴和小提琴,其视频长度均为6秒。以下为定量评估结果:
可见,Foley Music模型在贝斯(Bass)乐器演奏的预测性能最高达到了72%,而其他模型最高仅为8%。
另外,从以下四个指标来看,结果更为突出:
正确性:生成的歌曲与视频内容之间的相关性。
噪音:音乐噪音最小。
同步性:歌曲在时间上与视频内容最一致。
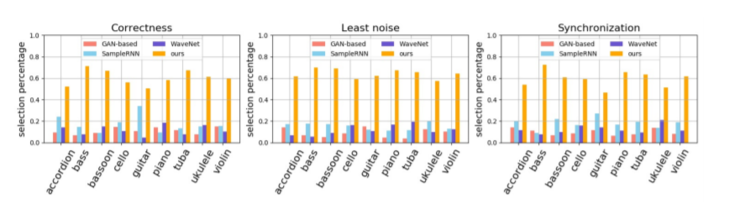
黄色为Foley Music模型,它在各项指标上的性能表现远远超过了其他模型,在正确性、噪音和同步性三项指标上最高均超过了0.6,其他最高不足0.4,且9种乐器均是如此。
另外,研究人员还发现,与其他基准系统相比,MIDI事件有助于改善声音质量,语义对齐和时间同步。
说明
GAN模型:它以人体特征为输入,通过鉴别其判定其姿态特征所产生的频谱图是真或是假,经过反复训练后,通过傅立叶逆变换将频谱图转换为音频波形。
SampleRNN:是无条件的端到端的神经音频生成模型,它相较于WaveNet结构更简单,在样本级层面生成语音要更快。
WaveNet:是谷歌Deepmind推出一款语音生成模型,在text-to-speech和语音生成方面表现很好。
另外,该模型的优势还在于它的可扩展性。MIDI表示是完全可解释和透明的,因此可以对预测的MIDI序列进行编辑,以生成AGF调不同风格音乐。如果使用波形或者频谱图作为音频表示形式的模型,这个功能是不可实现的。
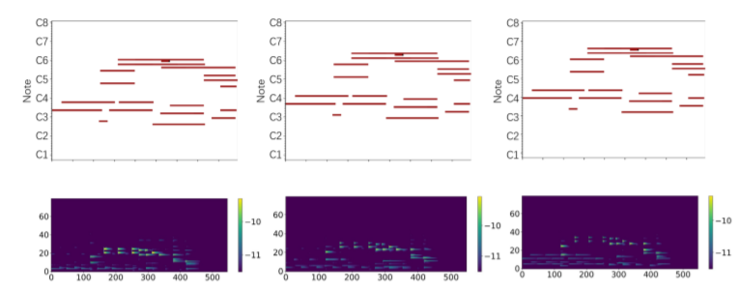
最后研究人员在论文中表明,此项研究通过人体关键点和MIDI表示很好地建立视觉和音乐信号之间的相关性,实现了音乐风格的可拓展性。为当前研究视频和音乐联系拓展出了一种更好的研究路径。
-
AI
+关注
关注
91文章
41432浏览量
302779 -
人工智能
+关注
关注
1821文章
50385浏览量
267138 -
模型
+关注
关注
1文章
3835浏览量
52293
原文标题:只看手势动作,就能完美复现音乐,MIT联合沃森实验室团队推出最新AI,多种高难度乐器信手拈来!
文章出处:【微信号:WW_CGQJS,微信公众号:传感器技术】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
AI大模型小龙虾-OpenClaw-0基础从入门到实战
HM博学谷狂野AI大模型第四期
AI大模型微调企业项目实战课

边缘AI算力临界点:深度解析176TOPS香橙派AI Station的产业价值
大模型 ai coding 比较
使用NORDIC AI的好处
小新AI语音互动礼盒上线啦!正版IP原声对话!启明云端乐鑫代理

灵动微电子最新最火热的一款芯片推荐
【技术讨论】智能戒指手势交互:如何优化PCBA成本与实现<20ms低延迟?
传统工业AP搞不定的PROFINET实时传输,为什么它可以?

OpenAI开源模型登陆IBM watsonx.ai开发平台
新品上线|Maix4-HAT 大模型 AI 加速套件 ,一键解锁树莓派多模态 AI 力量!

AlphaEvolve:一款基于Gemini的编程Agent,用于设计高级算法



评论