 企业级内存条的Memory ECC
企业级内存条的Memory ECC
我们今天来简单讨论一下企业级内存条的Memory ECC。

图 (1)
图(1)是一个带有ECC的RDIMM,图中我们已经将各个组件和关键的金手指信号区域标示出来。首先,我们来认识一下这几个关键词: Device:内存颗粒,根据其存放内容不同,又分为数据颗粒和ECC颗粒。通常有X4,X8和X16,代表每个颗粒对外的数据线路是4 lane,8 lane和16 lane。
Channel:一个Channel由一个或者多个Rank组成,其宽度由控制器决定。当前主流的个人电脑和服务器中,一个Channel的宽度为64bit,可根据内存控制器是否支持ECC而扩展额外的8bit。也就是说如果不支持ECC的Channel,其宽度为64bit,而支持ECC的Channel,其宽度为72bit。市面上两种内存条都有销售。
Rank:一个Channel里面,同一个CS(Chip Select)信号选中的所有Device就是一个Rank。同一个Rank中所有的Device共用命令,地址和控制信号。拿读操作举例,内存控制器发起的一个读操作,其实将作用于该Channel的某个Rank中所有的Device。所有Device的数据线共同输出达到内存控制器所需的宽度。例如,采用X4的颗粒,组成不带ECC功能的一个Rank则需要64/4 = 16个X4的Device。大家可以计算一下如果采用X8或者X16宽度的颗粒,需要多少个呢?
注:本文我们将主要以X4的Device来讨论
注:X16的颗粒一般不被用来组成带ECC的Rank
Cacheline:Cacheline通常是指是处理器中Cache Unit(缓存模块)缓存一笔数据的标准大小。根据处理器的不同,Cacheline的大小是不一样的。当前主流的个人电脑和服务器中,Cacheline的大小为64 Byte。为了设计方便,处理器内部搬运可被缓存的数据也采用同样的大小64B。为了满足该需求,一个Rank被设计成了64bit的数据位宽,而JEDEC(DDR标准组织)设计了burst传输。一个Burst的长度可以是8,从而一次读操作,可以让颗粒一次吐出8笔数据。从而达到64bit X 8 = 64B的大小。具体参考图(2)。

图(2)
CE(CorrectableError):可纠正错误是指硬件(芯片)可以直接纠正的错误。由于内存控制器设计不一样,对于可纠正错误的能力可能存在不同。例如,主流x86服务器的内存控制器(支持带ECC的内存条),在一次读操作中,一个X4宽度的Device内的任意错误都是可纠正的,包括ECC的Device。如果Rank是X8宽度的Device组成,其纠正能力还是与X4的Device宽度及位置保持一致。在X8的一个Device中,只有DQ0-3,或者DQ4-7可以被纠正。如果是DQ2-5,虽然是X4宽度但位置与X4时不对应,也无法纠正。
注:DQ0即D0,或者D0_0,DQ63则是D63,或者D15_3
UCE(Uncorrectable Error):不可纠正错误是指硬件(芯片)无法直接纠正的错误。例如,在一次读操作中,错误数据位分布在不同X4的Device范围,以现有内存控制设计来看,属于不可纠正错误。
下面我们简单介绍一下内存控制器是如何侦错和纠错的。由于ECC具体算法属于各家的IP,这里介绍的方法只是帮助大家理解该功能。首先,内存控制器能够纠错,就必须先能发现错误。如果每次消费的数据大小是64B,在不增加额外信息的情况下,我们是无法知道该数据是否有改变的,因为64B的数据可以是任何01的组合,即任意数据都是合法的。另一方面,额外的信息需要额外的存储,从成本考虑,这额外信息应该越小越好。JEDEC组织提出增加额外8 x 8 = 64bit的数据来帮助一个64B的数据完成ECC。 从物理角度看,一个X4 Device组成的Rank将会增加两个Device用于ECC。一种可行的做法是,其中一个Device负责存放CRC(Cyclic Redundancy Check)校验信息用于侦错,另一个Device负责存放奇偶校验信息(Parity),配合纠正错误。
Parity:Parity基本功能是发现保护数据中是否有bit翻转。保护方法是统计保护数据中1的个数,如果是偶校验,当保护数据中1的个数是偶数时,Parity为0,否则为1,所以Parity只需要一个bit就能发现保护数据中是否有一个bit的数据翻转(0到1或者1到0)。当然对于奇数个bit都有一样的检测效果。但当偶数bit翻转的时候,Parity将无法知道。在了解了Parity基本功能后,我们来看看内存控制器是如何计算Parity并存放的。如图(3)所示。

图(3)
Burst传输中每一笔64bit数据,4bit Parity和4bit CRC的具体对应关系如下: P0=D0_0+D1_0+D2_0+…D15_0+C0 P1=D0_1+D1_1+D2_1+…D15_1+C1 P2=D0_2+D1_2+D2_2+…D15_2+C2 P3=D0_3+D1_3+D2_3+…D15_3 +C3
注:D15_3为Device15的DQ3信号,从Rank角度看,为图中的D63
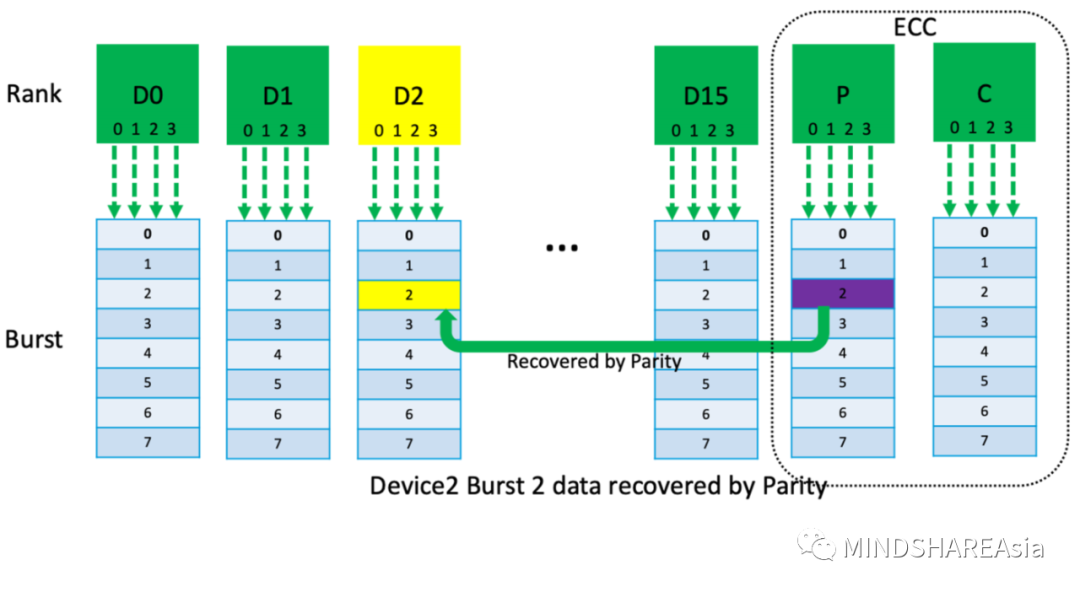
假设Device 2 在Burst的第三笔数据中有bit翻转,则无论是D2_0, D2_1, D2_2, D2_3 或者都错了,请参考图(4),我们都可以通过Parity bits反算回来,前提是burst的第三笔数据中其他Device没有出现错误。具体计算如下:
D2_0=P0(-)(D0_0+D1_0+D3_0…D15_0+C0)
D2_1=P1(-)(D0_1+D1_1+D3_1…D15_1+C1)
D2_2=P2(-)(D0_2+D1_2+D3_2…D15_2+C2)
D2_3=P3(-)(D0_3+D1_3+D3_3…D15_3+C3)
图(4)
CRC:我们怎样知道读取的Cacheline数据是正确的还是错误的?这里将会用到CRC来进行校验。一种比较简单的校验方式就是除法。我们设计一个除数,让被保护数据(被除数)去除以这个除数,然后会得到商和余数。通常余数比设计的除数要小。在存储一个Cacheline大小数据到内存条上的时候,内存控制器会计算CRC的值,并存放到CRC的Device中去。读取的时候再计算一遍,然后和内存条读回来的CRC的值进行比较。如果一致,则认为数据没有发生变化。否则,认为数据出错。 从上述理论可以推出,CRC校验位越多,则侦错能力越强。CRC设计不一样,侦错不同数据翻转的能力不同。可能存在数据错了,但侦错不了的情况。 既然有漏测的情况,为什么我们还会继续使用?这就和错误类型的概率有关了。通常情况下,一个bit翻转的可能性比较高,多bit同时翻转的可能性比较低。多bit翻转在同一个device里的几率比较高,多device同时翻转的概率比较低。 举个例子,当一个Cacheline的数据从内存条里读出来后,通过CRC校验,我们会发现数据有可能已经发生改变。这个时候,我们先假设出现了CE(Correctable Error)问题。则通过Parity信息反算Device数据,需要一个Device一个Device的假设,然后重新计算CRC和之前存储的CRC进行比较。所以最多的情况可能要假设18次。 如果全部弄完仍然CRC对不上,则属于UCE(Uncorrectable Error)问题啦。当然,大家会发现,ECC校验过程会影响内存读写延时。
到这里,大家应该了解了Memory ECC的基本算法了,Parity针对的是每个Burst,CRC是以半个CacheLine或者其他大小为单位处理的。如果是跨Device的Error,真的无法纠错吗?如果有,请将你的实现方案发给我们吧,我们将在下期公布读者的“可行”方案哦。
-
处理器
+关注
关注
68文章
19293浏览量
229927 -
服务器
+关注
关注
12文章
9184浏览量
85479 -
内存条
+关注
关注
0文章
145浏览量
19529
原文标题:真相!企业级内存条到底牛在哪儿?
文章出处:【微信号:SSDFans,微信公众号:SSDFans】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
如何选择DDR内存条 DDR3与DDR4内存区别
佰维特存推出工业级ECC DDR4 SODIMM内存条,守护极端环境下的工业存储需求

十铨科技推出首款工业级DDR5 6400MT/s内存条
金士顿发布FURY Renegade DDR5 CUDIMM内存条
金百达、精亿、光威这三个品牌的内存条哪个好?
英睿达推出首批CUDIMM、CSODIMM内存条
电脑内存条的作用和功能
内存时钟和内存条有什么不同
内存条接触不良会导致哪些情况
卓越性能精亿内存条赤龙银甲系列DDR4 16G(8GX2) 3200 内存条测评 值得推荐价格亲民质量过硬的国货老牌
DDR5内存条上的时钟走线

研华工控机购买指南:DDR3、DDR4、DDR5怎么选?如何选择内存条?

江波龙进军企业级存储,万事俱备坚定高端之路
服务器内存条和普通内存条的区别
企业级SSD-高性能系列固态硬盘推荐






 工商网监
工商网监
评论