 一种针对该文本检索任务的BERT算法方案DR-BERT
一种针对该文本检索任务的BERT算法方案DR-BERT

基于微软大规模真实场景数据的阅读理解数据集MS MARCO,美团搜索与NLP中心提出了一种针对该文本检索任务的BERT算法方案DR-BERT,该方案是第一个在官方评测指标MRR@10上突破0.4的模型。
本文系DR-BERT算法在文本检索任务中的实践分享,希望对从事检索、排序相关研究的同学能够有所启发和帮助。
背景提高机器阅读理解(MRC)能力以及开放领域问答(QA)能力是自然语言处理(NLP)领域的一大重要目标。在人工智能领域,很多突破性的进展都基于一些大型公开的数据集。比如在计算机视觉领域,基于对ImageNet数据集研发的物体分类模型已经超越了人类的表现。类似的,在语音识别领域,一些大型的语音数据库,同样使得了深度学习模型大幅提高了语音识别的能力。 近年来,为了提高模型的自然语言理解能力,越来越多的MRC和QA数据集开始涌现。但是,这些数据集或多或少存在一些缺陷,比如数据量不够、依赖人工构造Query等。针对这些问题,微软提出了一个基于大规模真实场景数据的阅读理解数据集MS MARCO (Microsoft Machine Reading Comprehension)[1]。该数据集基于Bing搜索引擎和Cortana智能助手中的真实搜索查询产生,包含100万查询,800万文档和18万人工编辑的答案。 基于MS MARCO数据集,微软提出了两种不同的任务:一种是给定问题,检索所有数据集中的文档并进行排序,属于文档检索和排序任务;另一种是根据问题和给定的相关文档生成答案,属于QA任务。在美团业务中,文档检索和排序算法在搜索、广告、推荐等场景中都有着广泛的应用。此外,直接在所有候选文档上进行QA任务的时间消耗是无法接受的,QA任务必须依靠排序任务筛选出排名靠前的文档,而排序算法的性能直接影响到QA任务的表现。基于上述原因,我们主要将精力放在基于MS MARCO的文档检索和排序任务上。 自2018年10月MACRO文档排序任务发布后,迄今吸引了包括阿里巴巴达摩院、Facebook、微软、卡内基梅隆大学、清华等多家企业和高校的参与。在美团的预训练MT-BERT平台[14]上,我们提出了一种针对该文本检索任务的BERT算法方案,称之为DR-BERT(Enhancing BERT-based Document Ranking Model with Task-adaptive Training and OOV Matching Method)。DR-BERT是第一个在官方评测指标MRR@10上突破0.4的模型,且在2020年5月21日(模型提交日)-8月12日期间位居榜首,主办方也单独发表推文表示了祝贺,如下图1所示。DR-BERT模型的核心创新主要包括领域自适应的预训练、两阶段模型精调及两种OOV(Out of Vocabulary)匹配方法。
图1 官方祝贺推文及MARCO 排行榜相关介绍Learning to Rank在信息检索领域,早期就已经存在很多机器学习排序模型(Learning to Rank)用来解决文档排序问题,包括LambdaRank[2]、AdaRank[3]等,这些模型依赖很多手工构造的特征。而随着深度学习技术在机器学习领域的流行,研究人员提出了很多神经排序模型,比如DSSM[4]、KNRM[5]等。这些模型将问题和文档的表示映射到连续的向量空间中,然后通过神经网络来计算它们的相似度,从而避免了繁琐的手工特征构建。
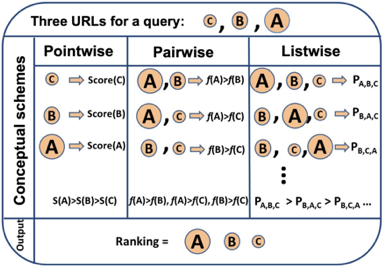
图2 Pointwise、Pairwise、Listwise训练的目标 根据学习目标的不同,排序模型大体可以分为Pointwise、Pairwise和Listwise。这三种方法的示意图如上图2所示。其中,Pointwise方法直接预测每个文档和问题的相关分数,尽管这种方法很容易实现,然而对于排序来说,更重要的是学到不同文档之间的排序关系。基于这种思想,Pairwise方法将排序问题转换为对两两文档的比较。具体来讲,给定一个问题,每个文档都会和其他的文档两两比较,判断该文档是否优于其他文档。这样的话,模型就学习到了不同文档之间的相对关系。 然而,Pairwise的排序任务存在两个问题:第一,这种方法优化两两文档的比较而非更多文档的排序,跟文档排序的目标不同;第二,随机从文档中抽取Pair容易造成训练数据偏置的问题。为了弥补这些问题,Listwise方法将Pairwsie的思路加以延伸,直接学习排序之间的相互关系。根据使用的损失函数形式,研究人员提出了多种不同的Listwise模型。比如,ListNet[6]直接使用每个文档的top-1概率分布作为排序列表,并使用交叉熵损失来优化。ListMLE[7]使用最大似然来优化。SoftRank[8]直接使用NDCG这种排序的度量指标来进行优化。大多数研究表明,相比于Pointwise和Pairwise方法,Listwise的学习方式能够产生更好的排序结果。BERT自2018年谷歌的BERT[9]的提出以来,预训练语言模型在自然语言处理领域取得了很大的成功,在多种NLP任务上取得了SOTA效果。BERT本质上是一个基于Transformer架构的编码器,其取得成功的关键因素是利用多层Transoformer中的自注意力机制(Self-Attention)提取不同层次的语义特征,具有很强的语义表征能力。如图3所示,BERT的训练分为两部分,一部分是基于大规模语料上的预训练(Pre-training),一部分是在特定任务上的微调(Fine-tuning)。
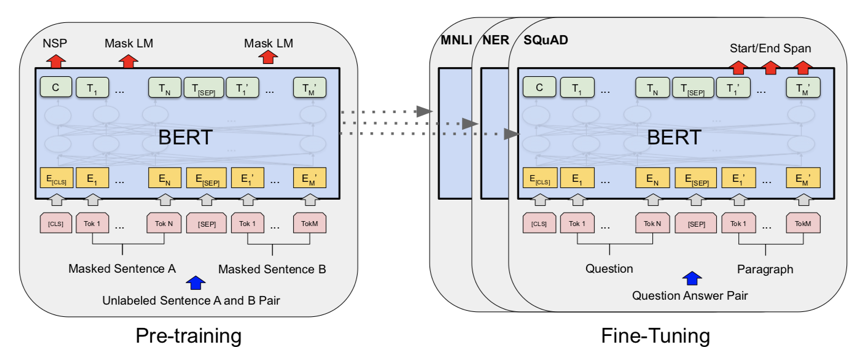
图3 BERT的结构和训练模式 在信息检索领域,很多研究人员也开始使用BERT来完成排序任务。比如,[10][11]就使用BERT在MS MARCO上进行实验,得到的结果大幅超越了当时最好的神经网络排序模型。[10]使用了Pointwise学习方式,而[11]使用了Pairwise学习方式。这些工作虽然取得了不错的效果,但是未利用到排序本身的比较信息。基于此,我们结合BERT本身的语义表征能力和Listwise排序,取得了很大的进步。模型介绍任务描述

基于DeepCT候选初筛由于MS MARCO中的数据量很大,直接使用深度神经网络模型做Query和所有文档的相关性计算会消耗大量的时间。因此,大部分的排序模型都会使用两阶段的排序方法。第一阶段初步筛选出top-k的候选文档,然后第二阶段使用深度神经网络对候选文档进行精排。这里我们使用BM25算法来进行第一步的检索,BM25常用的文档表示方法包括TF-IDF等。 但是TF-IDF不能考虑每个词的上下文语义。DeepCT[12]为了改进这种问题,首先使用BERT对文档单独进行编码,然后输出每个单词的重要性程度分数。通过BERT强大的语义表征能力,可以很好衡量单词在文档中的重要性。如下图4所示,颜色越深的单词,其重要性越高。其中的“stomach”在第一个文档中的重要性更高。

图4 DeepCT估单词的重要性,同一个词在不同文档中的重要性不同
DeepCT的训练目标如下所示:
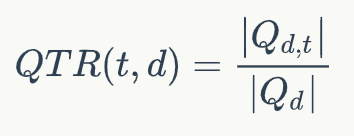
其中QTR(t,d)表示文档d中单词t的重要性分数,Qd表示和文档d相关的问题,Q{d,t}表示文档d对应的问题中包含单词t的子集。输出的分数可以当做词频(TF)使用,相当于对文档的词的重要性进行了重新估计,因此可以直接使用BM25算法进行检索。我们使用DeepCT作为第一阶段的检索模型,得到top-k个文档作为文档候选集合D={D1,D2,...,Dk}。领域自适应预训练由于我们的模型是基于BERT的,而BERT本身的预训练使用的语料和当前的任务使用的语料并不是同一个领域。我们得出这个结论是基于对两部分语料中top-10000高频词的分析,我们发现MARCO的top-10000高频词和BERT基线使用的语料有超过40%的差异。因此,我们有必要使用当前领域的语料对BERT进行预训练。由于MS MARCO属于大规模语料,我们可以直接使用该数据集中的文档内容对BERT进行预训练。我们在第一阶段使用MLM和NSP预训练目标函数在MS MARCO上进行预训练。两阶段精调
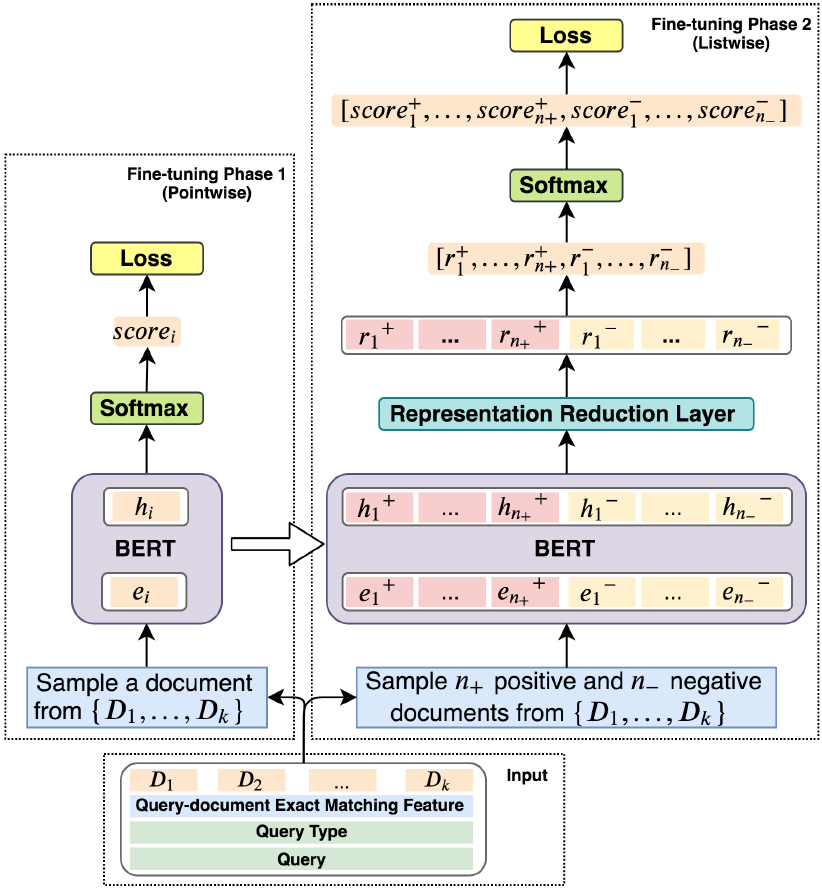
图5 模型结构 下面介绍我们提出的精调模型,上图5展示了我们提出的模型的结构。精调分为两个阶段:Pointwise精调和Listwise精调。Pointwise问题类型感知的精调
第一阶段的精调,我们的目标是通过Pointwise的训练方式建立问题和文档的关系。我们将Query-Document作为输入,使用BERT对其编码,匹配问题和文档。考虑到问题和文档的匹配模式和问题的类型有很大的关系,我们认为在该阶段还需要考虑问题的类型。因此,我们使用问题,问题类型和文档一起通过BERT进行编码,得到一个深层交互的语义表示。具体的,我们将问题类型T、问题Q和第i个文档Di拼接成一个序列输入,如下式所示:

其中

经过BERT编码后,我们取最后一层中
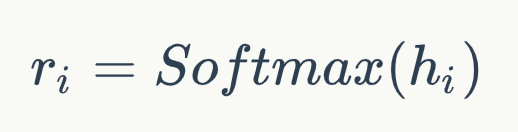
该分数Ti通过交叉熵损失函数进行优化。通过以上的预训练,模型对不同的问题学到了不同的匹配模式。该阶段的预训练可以称为类型自适应(Type-Adaptive)模型精调。Listwise 精调为了使得模型直接学习不同排序的比较关系,我们通过Listwise的方式对模型进行精调。具体的,在训练过程中,对于每个问题,我们采样n+个正例以及n-个负例作为输入,这些文档是从候选文档集合D中随机产生。注意,由于硬件的限制,我们不能将所有的候选文档都输入到当前模型中。因此我们选择了随机采样的方式来进行训练。
和预训练中使用BERT的方式类似,我们得到正例和负例中每个文档的表示,hi+和hi-。然后通过一个单层感知机将上面得到的表示降维并转换成一个分数,即:
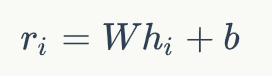
其中W和b是模型中可学习的参数。接下来对于每个文档的分数,我们通过一个文档级别的比较和归一化得到:
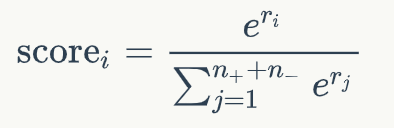
这一步,我们将文档中的正例的分数和负例的分数进行比较,得到Listwise的排名分数。我通过这一步,我们得到了一个文档排序列表,我们可以将文档排序的优化转化为最大化正例的分数。因此,模型可以通过负对数似然损失优化,如下式所示:
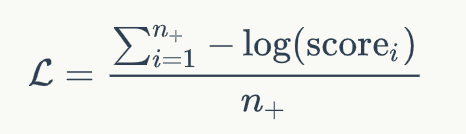
至于为什么使用两个阶段的精调模型,主要出于如下两点考虑:
1. 我们发现首先学习问题和文档的相关性特征然后学习排序的特征相比,直接学习排序特征效果好。
2. MARCO是标注不充分的数据集合。换句话说,许多和问题相关的文档未被标注为1,这些噪声容易造成模型过拟合。第一阶段的模型可以用来过滤训练数据中的噪声,从而可以有更好的数据监督第二阶段的精调模型。解决OOV的错误匹配问题在BERT中,为了减少词表的规模以及解决Out-of-vocabulary(OOV)的问题,使用了WordPiece方法来分词。WordPiece会把不在词表里的词,即OOV词拆分成片段,如图6所示,原始的问题中包含词“bogue”,而文档中包含词“bogus”。在WordPiece方法下,将“bogue”切分成”bog”和“##ue”,并且将“bogus”切分成”bog”和“##us”。我们发现,“bogus”和“bogue”是不相关的两个词,但是由于WordPiece切分出了匹配的片段“bog”,导致两者的相关性计算分数比较高。

图6 BERT WordPiece处理前/后的文本 为了解决这个问题,我们提出了一种是对原始词(WordPiece切词之前)做精准匹配的特征。所谓“精确匹配”,指的是某个词在文档和问题中同时出现。精准匹配是信息检索和机器阅读理解中非常重要的一个技术。根据以往的研究,很多阅读理解模型加入该特征之后都可以有一定的效果提升。具体的,在Fine-tuning阶段,我们对于每个词构造了一个精准匹配特征,该特征表示该单词是否出现在问题以及文档中。在编码阶段之前,我们就将这个特征映射到一个向量,和原本的Embedding进行组合:

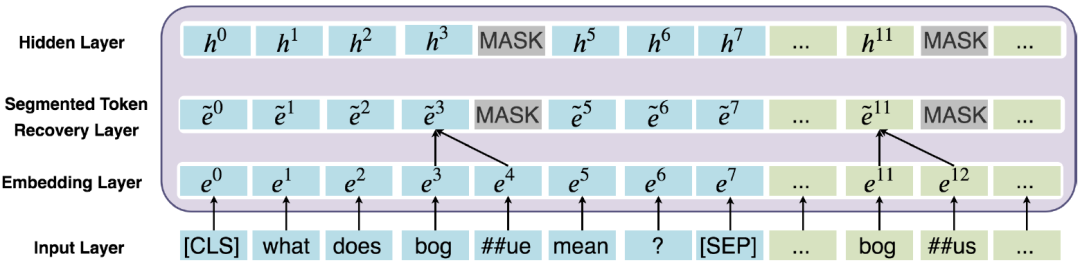
图7 词还原机制的工作原理 除此之外,我们还提出了一种词还原机制如图7所示,词还原机制能够将WordPiece切分的Subtoken的表示合并,从而能更好地解决OOV错误匹配的问题。具体来说,我们使用Average Pooling对Subtoken的表示合并作为隐层的输入。除此之外,如上图7所示,我们使用了MASK处理Subtoken对应的非首位的隐层位置。值得注意的是,词还原机制也能很好地避免模型的过拟合问题。这是因为MARCO的集合标注是比较稀疏的,换句话说,有很多正例未被标注为1,因此容易导致模型过拟合这些负样本。词还原机制一定程度上起到了Dropout的作用。总结与展望以上内容就对我们提出的DR-BERT模型进行了详细的介绍。我们提出的DR-BERT模型主要采用了任务自适应预训练以及两阶段模型精调训练。除此之外,还提出了词还原机制和精确匹配特征提高OOV词的匹配效果。通过在大规模数据集MS MARCO的实验,充分验证了该模型的优越性,希望这些能对大家有所帮助或者启发。
-
微软
+关注
关注
4文章
6752浏览量
108076 -
算法
+关注
关注
23文章
4802浏览量
98521 -
数据集
+关注
关注
4文章
1240浏览量
26261
原文标题:MT-BERT在文本检索任务中的实践
文章出处:【微信号:zenRRan,微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
一种基于低噪声电源管理架构的射频采样系统设计方案

算法工程师需要具备哪些技能?
一种无OS的MCU实用软件框架
一文说透了如何实现单片机的多任务并发!
探索 RTKA210030DR0000BU 演示板:高效电源解决方案
基于安路DR1M90 FPSoC的Linux系统全流程开发指南(4)
基于安路DR1M90 FPSoC 的Linux 系统全流程开发指南(3)

基于安路DR1M90 FPSoC 的Linux 系统全流程开发指南(1)
思必驰任务型对话算法通过国家备案
8种常用的CRC算法分享
复杂的软件算法硬件IP核的实现
针对AES算法的安全防护设计
比特误码率测试仪接收端受限眼图自动校准最佳实践

格灵深瞳突破文本人物检索技术难题



评论