 三篇ACL2020论文即围绕谣言判别中的可解释性
三篇ACL2020论文即围绕谣言判别中的可解释性
引言
谣言始终与人类社会的发展形影相随,随着互联网的发展和网上言论的开放,虚假的、未经证实的信息极易在社交网络平台上广泛传播,带来不良社会影响。目前,网络谣言常被定义为“广泛流传的、真实性受到质疑的、表面上可信但极具迷惑性难以辨别真伪的信息”(Zubiaga, 2018)。
对网络谣言真实性进行判别是较为复杂的系统性任务,可粗粒度分为谣言检测(rumor detection)、立场分类(stance classification)、谣言判别(rumor verification)流程式子任务。同时社交网络中可追踪的文本内容、用户特征、信息传播轨迹,为谣言检测及真伪性判别提供了丰富的信息来源和建模思路,这也使得端到端的谣言判别更具挑战。
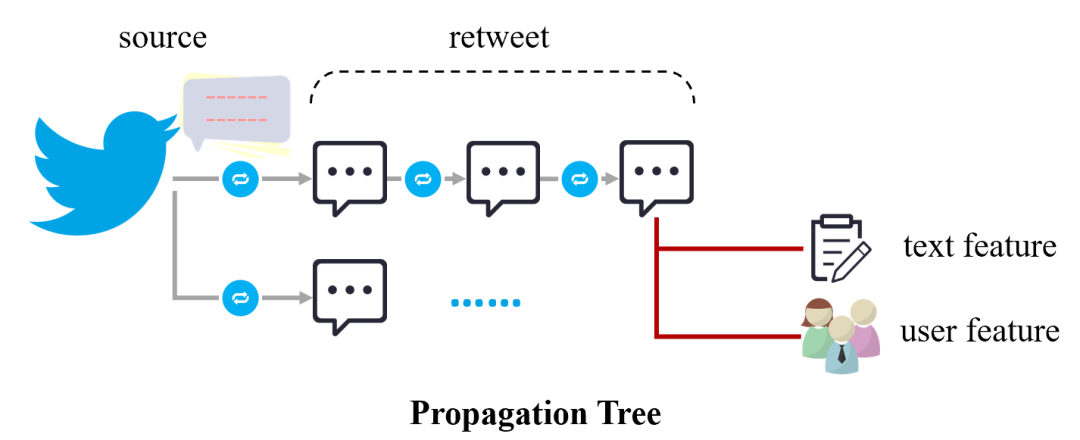
网络谣言形成的信息传播树及特征来源
早期,学者们多采用从文本、用户、传播等方面提取特征的思路,尽可能的刻画谣言传播形态。随着深度学习的发展,更具泛化性的文本表示方法(如词向量、预训练模型),更适配于消息传播的信息整合模型(如基于消息发布时间的序列化模型、基于信息传播轨迹的树结构/图结构模型),更简便的子任务协同训练框架(如多任务学习),使得神经网络模型在谣言判别上的性能不断提升。
然而,随着深度模型复杂度增加,模型内部的决策过程却愈加难以解释和验证,也对谣言判别的实际应用推广带来了限制。本次DISC小编分享的三篇ACL2020论文即围绕谣言判别中的可解释性,介绍网络谣言传播中易感用户及话题挖掘、判别线索取证、数据及模型不确定性衡量的相关工作。
文章概览
基于图网络和协同注意力机制的用于可解释社交媒体虚假新闻检测的模型(Graph-aware Co-Attention Networks for Explainable Fake News Detection on Social Media)
论文地址:https://www.aclweb.org/anthology/2020.acl-main.48.pdf
该篇文章延续了谣言判别中的传统思路,尽可能准确的刻画谣言的传播模式。主要围绕信源文本和参与传播用户的特征进行建模,并借助协同注意力机制捕捉信源文本中的敏感话题以及传播过程中可疑度的用户。
基于决策树和协同注意力机制的可解释的谣言判别的模型(Decision Tree-based Co-Attention Networks for Explainable Claim Verification)
论文地址:https://www.aclweb.org/anthology/2020.acl-main.97.pdf
该篇文章秉持谣言传播中具有“自证性”,即假消息的相关评论或转发中会出现对其真实性进行佐证的内容。通过决策树筛选出可作为判别线索的消息,接着借助协同注意力机制探索信源文本与相关线索的交互关系,由此可呈现出模型在筛选佐证时的决策过程和更细粒度的关键文本和话题。
评估谣言判别模型中的预测不确定性(Estimating Predictive Uncertainty for Rumour Verification Models)
论文地址:https://www.aclweb.org/anthology/2020.acl-main.623.pdf
该篇文章立足于谣言判别的实际应用场景,认为训练完好的模型在面对突发谣言事件依然面对跨领域迁移的挑战,大部分现有模型泛化能力都较差,因此借助不确定性衡量及主动学习的思路,提出了谣言判别中可衡量数据和模型不确定性的指标,并以此指标拒绝对模型泛化不友好的训练样本,探索对模型性能的影响。
数据概览
早期与谣言检测有关的工作多集中于通过事件关键词检索的方式,获取讨论激烈、事实性难辨的社交网络短文本,文本之间相对较为孤立。后有学者提出根据消息的转发关系形成完善的信息传播树,从更为全局和全面的角度评估消息及相关讨论的真伪性(Mou, 2015)。目前,谣言判别常采用的数据集也均以信息传播树的方式进行组织,每一个待判断的传播树的完整的信息传播结构以及树层面的类别标签,以上三篇文章涉及的数据集罗列如下。
Twitter15(Liu, 2016):从国外谣言公布网站(如snopes.com, emergent.info)获取已进行判别的社交网络信息,再由其发布的Twitter消息源爬取相关的转发信息形成信息传播树,共包含1374个信息传播树;传播树标签包含非谣言/真实信息/虚假信息/未被证实信息,各个类别比例较为均衡,训练、验证及测试集为随机划分。
Twitter16(Ma, 2016):构造思路与Twitter 15一致,根据当年热门事件进行了扩充,包含735个信息传播树,每棵树包含消息数目更少。
PHEME(Zubiaga, 2016; Zubiaga, 2017):从9个和政治、民生密切相关的主题出发,搜集了与这些主题相关的Twitter内容及其引发的讨论信息,筛选社交讨论性质更明显的形成信息传播树,根据谣言检测、立场分类、谣言判别的任务流程由新闻从业者进行标注,通过谣言检测将6425个信息传播树分类为谣言/非谣言,对于2402个谣言信息传播树再判别为真实信息/虚假信息/未被证实信息;采用LOEO(leave one event out)的验证方式,使其更贴近实际应用场景,但不同事件文本和类别差异都很大,极具挑战性。
RumourEval(Derczynski, 2017):是PHEME数据集的子集,筛选了立场标签较为完善的325个传播树,作为Semeval-2017 task 8的评测数据集,训练、验证及测试集为随机划分。
论文细节
1

基于图网络和协同注意力机制的用于可解释社交媒体虚假新闻检测的模型
论文动机
此前相关研究主要受到三方面的局限:
短文本社交网络文本建模能力不足。大部分用户在转发信源时发表的言论都较为简短,且许多仅为转发行为缺少实质性新增话语,基于信息传播树仅对消息文本进行建模表示能力有限。
构建准确的信息传播树代价昂贵。部分社交网络平台对爬取转发链数目进行了限制,并且部分用户设置了阅读权限,获取的传播树常存在缺失或截断的现象。
复杂模型的可解释性不足。即使模型最终输出真伪性标签,但内部决策过程很难验证,并且对于进一步实际应用,如挖掘潜在恶意用户、造谣惯用话术等没有帮助。
因此文章在对信源建模后,仅使用涉及的传播用户对信息传播树进行建模,并且融入协同注意力机制,对判决过程中的关键用户和关键信息进行呈现。
模型
整体模型大致可拆解为4部分:
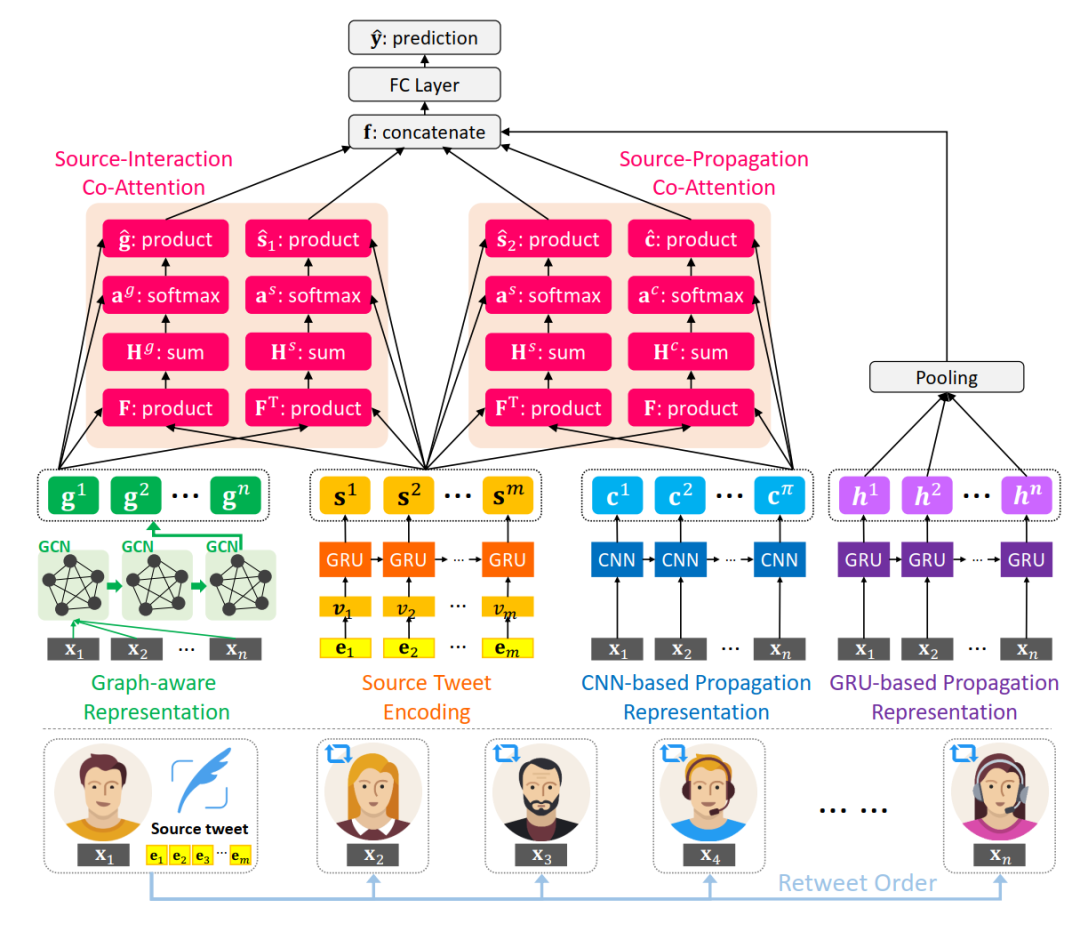
1. 信源文本表示
对原始消息文本中的词语进行one-hot编码,再使用GRU序列模型进行表示:
2. 用户传播特征表示
根据用户的个人资料(个人简介字数、昵称字数、关注数、被关注数、是否认证、是否开启地理定位、距离传播树中上一条消息的时间间隔、转发所在树的深度)提取用户特征,根据用户的发文时间形成序列,分别使用CNN和GRU得到传播序列的表示。
分别使用两个模型进行建模,经过CNN得到的序列表示在进行协同注意力融合时更为友好,而GRU能体现传播过程中参与用户类型的变化。
3. 用户潜在交互网络表示
除了在时间轴上用户参与较为宏观的表示,用户之间点对点的交互关系也能刻画信息的传播模式。为了简化传播树构造过程,文章直接将传播树内涉及的用户组成全连接图,以用户之间的余弦相似度初始化边权重以及图的邻接矩阵
,接着使用GCN得到具有交互特征的用户表示。
4. 协同注意力网络及预测
使用协同注意力机制得到融合表示,其中对信源和用户传播表示的融合表示计算如下:
对信源和用户交互表示的融合计算方式类似。
再将信源和用户交互表示的融合表示、信源和用户传播表示的融合表示、用户传播的序列化表示拼接,通过全连接层得到最终预测结果,以交叉熵损失函数作为优化目标来训练。
结果
模型在Twitter15、Twitter16两个数据集上都取得了更优的性能。
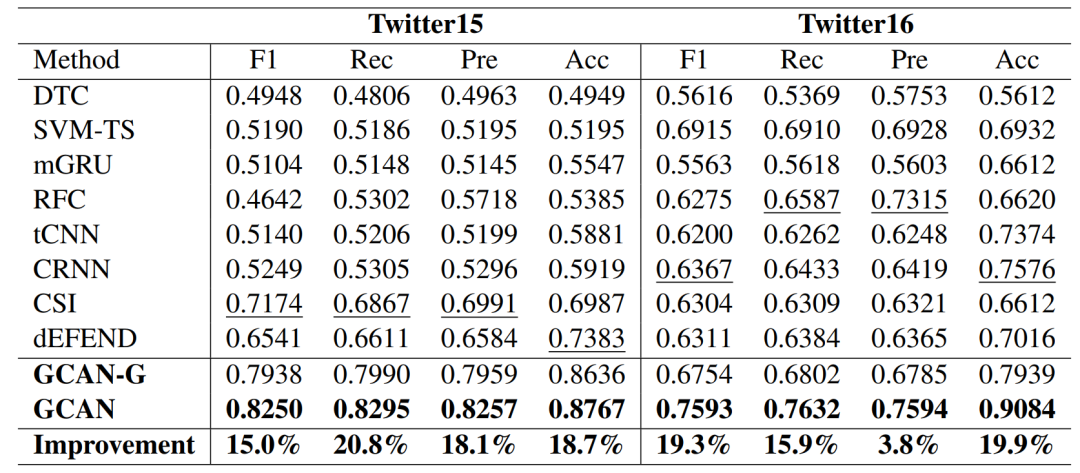
消融实验也验证了各个部件的有效性。
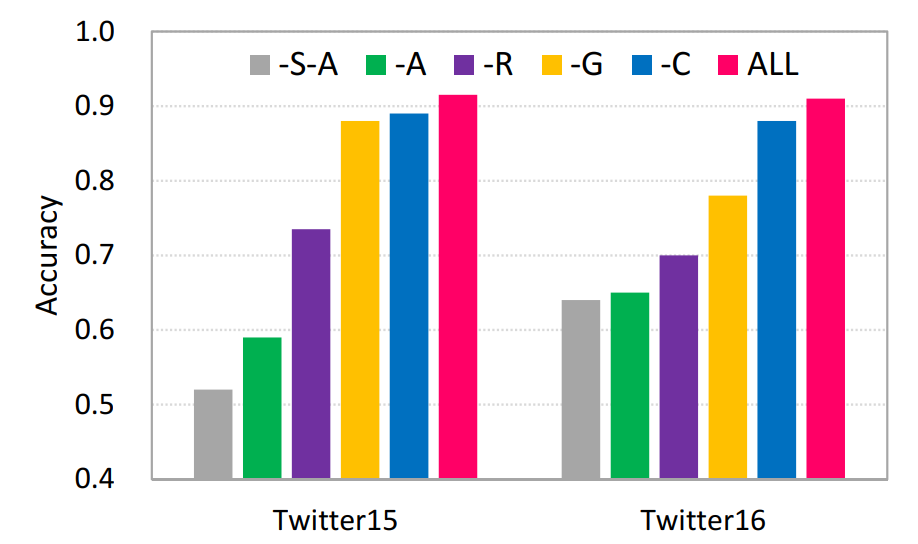
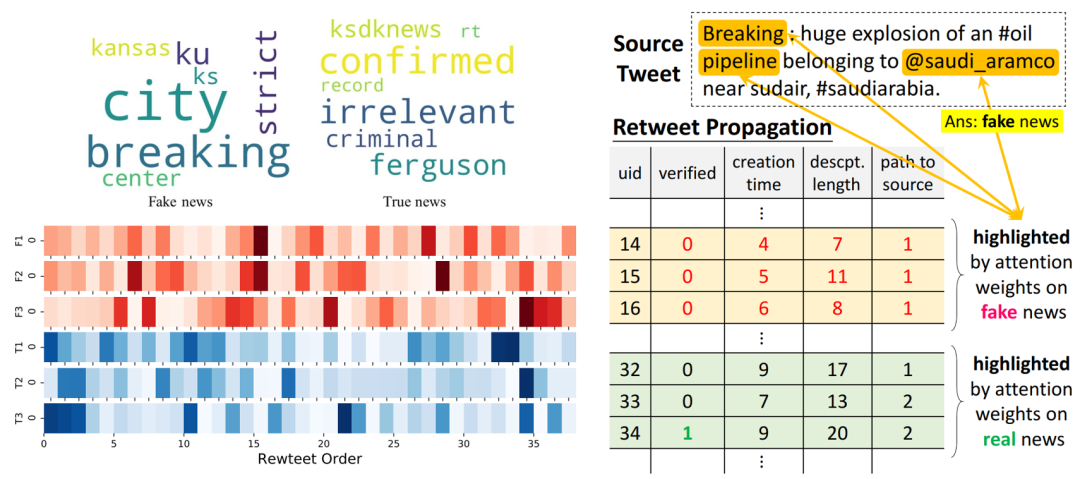
在可解释性的论证方面,分别提取关于信源中基于词的注意力权重、在用户传播表示中基于用户的注意力权重,分析真实信息/虚假信息案例中的关键词、传播判别模式和更易参与虚假信息传播的用户特征。
2

基于决策树和协同注意力机制的可解释的谣言判别模型
论文动机
虽然此前研究大多表明信息传播树中的后续讨论内容(如话题争议点、对原始信息真实的质疑等)对于整体判断有帮助,但缺少定位到具体有所呼应、有所论证单条消息的过程。此外,后续讨论内容与原始消息之间具体的词级别的交互未进行深入探索。
因此文章使用决策树具有解释性的呈现出筛选佐证的过程,并基于协同注意力机制探索信源与相关佐证之间词级别的关联,形成对信息传播树真伪性判别可解释性的逻辑链条。
模型
模型可分为2个部件:
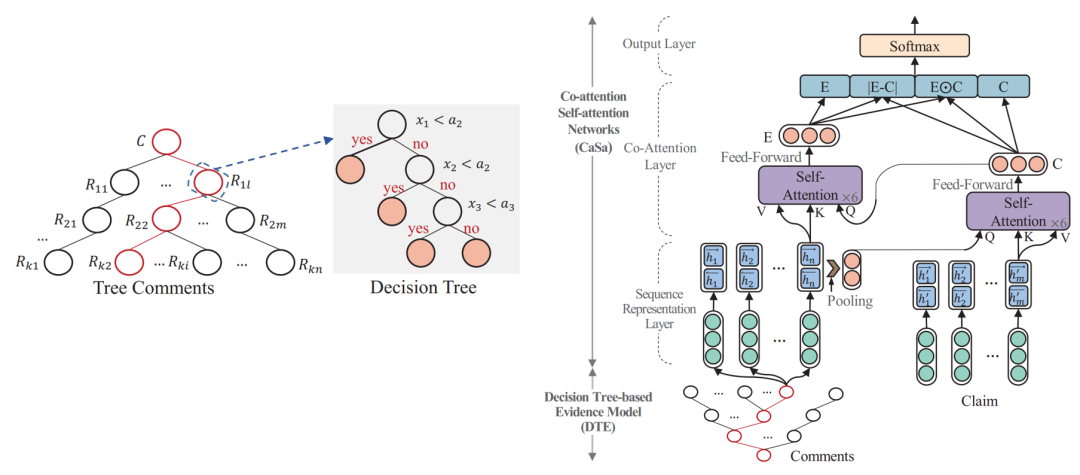
1. 基于决策树模型筛选佐证信息
根据以往研究构造与后续讨论相关性、可信度相关的3个数值型特征:消息与信源之间的语义相似度,发表消息用户的可信度,该条的可信度。
多次试验,分别设置3个数值特征的临界值条件,只要3个特征之一小于其阈值则将该条消息纳入佐证集合。
2. 基于协同注意力机制进行预测
对信息源文本使用双向LSTM更新词语表示;接着将第1步中提取出的佐证拼接起来,同样使用双向LSTM更新词表示。
基于协同注意力机制或者两者互相融合的表示。即在注意力权重计算公式中,保持关键字矩阵K、值矩阵V本身表示,将查询矩阵Q更换为需要进行交互的表示。
以计算O的方式获得两者交互融合的表示E和C后,进行求差、求内积并拼接的操作,得到信息传播树的表示,最后使用全连接层输出类别标签,并使用交叉熵损失函数进行训练。
结果
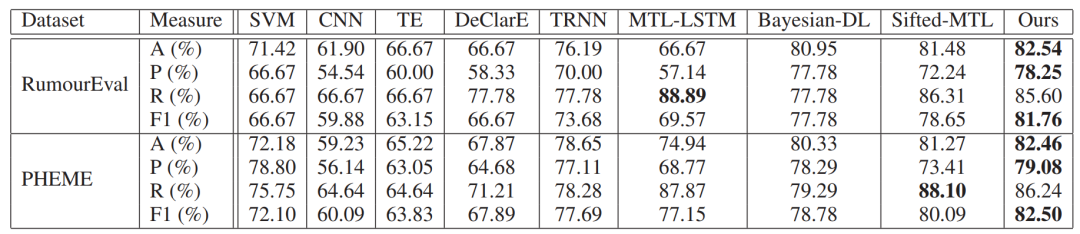
文章在RumourEval和PHEME数据集上进行测试(随机划分训练、验证、测试集),在大多数分类评价指标上都优于已有模型。
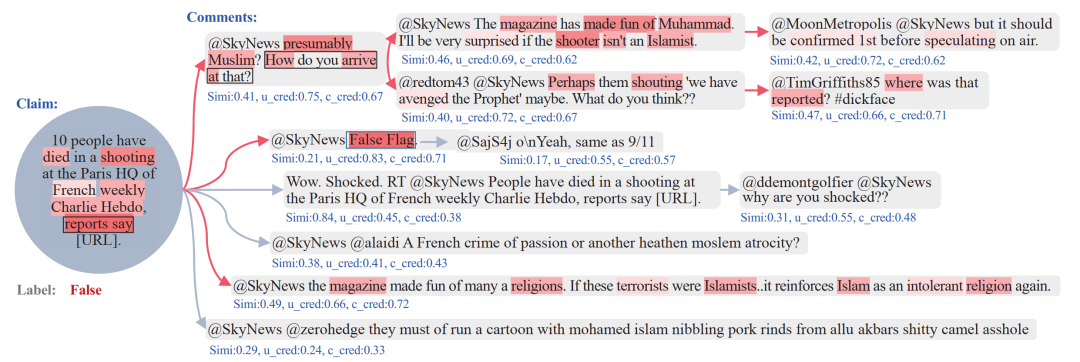
在可解释性的论证方面,文章抽取出1个信息传播树的案例,可视化了提出模型的决策过程。图中蓝色文本代表决策树模型中3个特征的具体数值,根据这些特征筛选出的佐证由红色箭头标记出来。同时,不同深色的红色阴影代表了计算的协同注意力权重,可以看到一些与谣言判别更相关的事件描述词。
3

评估谣言判别模型中的预测不确定性
论文动机
在实际应用场景下,谣言判别是极为复杂的系统性任务,智能化的谣言判别方法还不能完全取代人的细致全面的判断,但能缩小人工核查的范围。如果能更准确的找出对于模型难以判别的样例,再交由人工判断,将更加优化实际生活中对谣言的发现和判别。
另外,由于大多数模型是基于历史数据进行训练的,面对新产生的突发事件,模型的泛化能力往往不佳。若能剔除对整体泛化性能影响较大的训练样例,则有望进一步提升模型对新事件的泛化能力。
因此,文章借鉴在不确定性衡量方面相关工作以及主动学习的实验设置,提出了一系列用于衡量数据和模型不确定性的指标,并探索这些指标与模型预测能力、训练数据筛选之间的关联。
方法
文章先基于谣言判别的基线模型获取可比较的基础性能,接着计算不同类型的不确定性指标,并以此剔除训练样本再次训练,分析基线模型性能变化。
1. 基线模型
基线模型采用在RumourEval 2019任务上具有不错性能的枝化LSTM模型(branchLSTM),即根据信息传播的方向,将每条传播序列抽取出来,对每个序列使用LSTM进行表示得到预测标签后,再对所涉及的所有序列结果进行大多数投票得到传播树的预测标签。
2. 不确定性衡量
不确定性可从数据和模型两个层面进行考虑。数据的不确定性主要与所训模型的分类边界有关,距离分类边界越近,数据层面的不确定性就越高,加入轻微扰动则容易使得分类结果转变。模型的不确定性主要与各维表示对模型分类结果的代表性能相关,若仅保留部分维度的表示,预测结果依然稳定,则表明模型的不确定性较低。
在衡量模型不确定性(epistemic uncertainty)时,重复输出预测结果前的dropout层N次,由于dropout具有随机性,则每次预测结果将有所差异,用以下三个指标进行衡量:
变异比(variation ratio),即和主要预测类别不同的类别所占的比例,
熵(entropy),由于预测类别时得到的one-hot向量,对每一维度的概率求熵:
方差(variance),对于N次dropout的结果,计算代表类别概率的每一维度的方差,取最大值作为模型不确定衡量指标。
3. 数据筛选
在获得每个样例的数据和模型方面的不确定性数值指标后,通过非监督和监督方式舍弃样本。
非监督的舍弃即根据样本某一类型的不确定性进行排序,按一定比例舍弃掉不确定性高的样本。
监督的舍弃即从训练数据中再划分一小部分数据训练一个较为简单的预分类器(SVM或随机森林),输入特征为各种类型的不确定性指标,原有的one-hot预测结果和真实标签,分类错误的数据则打上被拒绝的标签。由此对剩下的训练数据通过预分类器判断是否需要舍弃。监督的舍弃方法能尽可能的利用到不同类型的不确定性衡量指标,且舍弃数目由预分类器给出而不需要人为试验多次。
结果
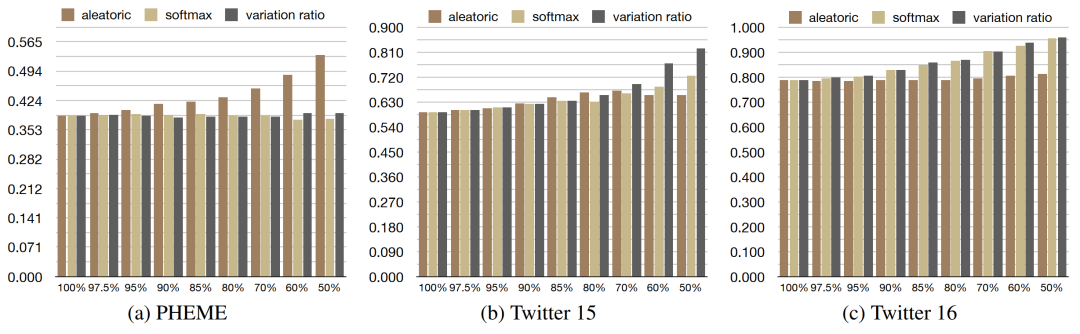
文章在PHEME、Twitter15、Twitter16数据集上进行了实验,结果表明在进行了数据舍弃后,模型的性能均有提升,尤其采用有监督方式的舍弃,提升更为显著。

在不同数据上,根据不同类型不确定性指标进行非监督的数据舍弃有明显差别。由于PHEME数据集验证方式为LOEO,测试集与验证集语义差距、类别比例都较大,因此根据数据不确定性效果提升更为明显。而Twitter15、Twitter16数据集较为均衡,针对模型不确定性的数据舍弃更为有效。
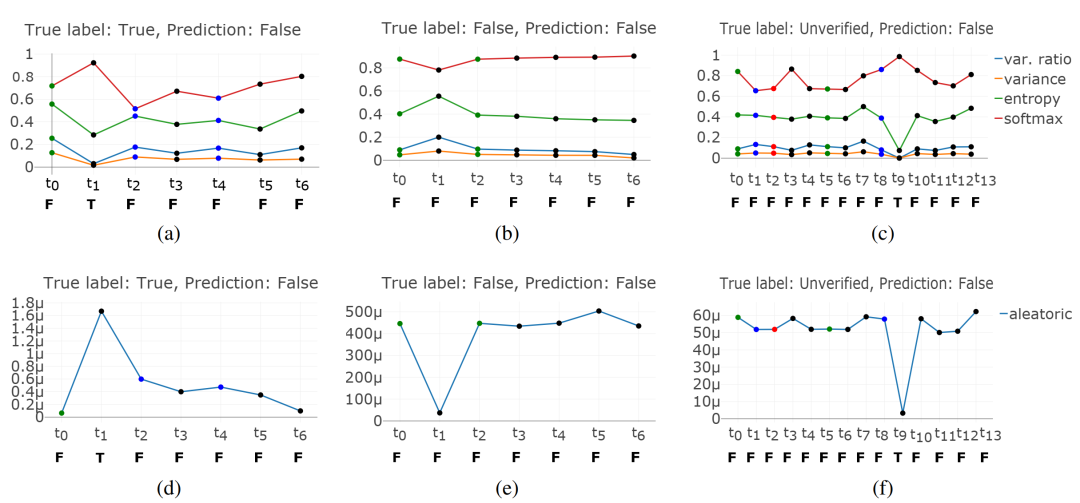
同时文章借助PHEME数据中传播树中部分消息的立场标签,探究了随时间变化,不断增多传播树相关的讨论,模型预测结果和不确定性的变化。图中展示了3个真实标签分别为真实/虚假/未经证实而预测标签均为虚假的样例,横轴代表该传播树不同时刻的消息,横轴下方的大写字母代表仅将该时刻前数据输入模型得到的预测标签;纵轴表示仅将该时刻前数据输入模型得到的不确定性的具体数值,图中上半部分代表模型不确定性,下半部分代表数据不确定性,并且图中每个圆点颜色代表不同立场(绿色-支持/红色-反对/蓝色-质疑/黑色-评论)。
可以看到,随着传播树信息的不断丰富,不确定性指标呈现出下降趋势;观察每一时刻的预测标签,预测结果和仅利用原始消息差别不多,说明在此模型下信源信息对谣言判别尤为重要。
总结
以上三篇文章均为社交网络谣言判别中可解释性探索提供了不同的解决思路。其中,协同注意力机制的广泛应用能有效的融合不同来源的信息(如信源和用户之间,信源和佐证之间),并定位对于谣言判别更为关键的部分。另外,对数据和模型不确定性的细化衡量能使人更加认识数据集的内置偏差或是模型的自身缺陷。
-
数据集
+关注
关注
4文章
1208浏览量
24739 -
深度学习
+关注
关注
73文章
5507浏览量
121298 -
cnn
+关注
关注
3文章
353浏览量
22254
原文标题:【论文分享】ACL 2020 社交网络谣言判别中可解释性相关研究
文章出处:【微信号:zenRRan,微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
机器学习模型可解释性的结果分析
什么是“可解释的”? 可解释性AI不能解释什么
斯坦福探索深度神经网络可解释性 决策树是关键


机器学习模型的“可解释性”的概念及其重要意义
机器学习模型可解释性的介绍
图神经网络的解释性综述
《计算机研究与发展》—机器学习的可解释性

文献综述:确保人工智能可解释性和可信度的来源记录





 工商网监
工商网监
评论