 基于深度的关键点匹配算法实现单步多人绝对三维姿态
基于深度的关键点匹配算法实现单步多人绝对三维姿态
由单帧彩色图像恢复多人的三维姿态和人与相机的绝对位置关系是一个具有挑战性的任务,因为图像在拍摄过程中损失了深度和尺度信息。在 ECCV2020 上,商汤与浙大联合实验室提出了单步多人绝对三维姿态估计网络和 2.5D 人体姿态表示方法,并且基于所提出的深度已知的关键点匹配算法,得到绝对三维人体姿态。该方法结合图像的全局特征和局部特征,能获得准确的人体前后关系和人与相机的距离,在 CMU Panoptic 和 MuPoTS-3D 多人三维人体姿态估计数据集上均达到 SOTA(state-of-the-art),并且在未见过的场景中具有很好的泛化能力。
论文名称:SMAP: Single-Shot Multi-PersonAbsolute 3D Pose Estimation

动机
基于单帧图像的人体绝对三维姿态估计在混合现实、视频分析、人机交互等领域有很广泛的应用。近几年研究人员多将注意力集中于人体相对三维姿态估计任务上,并且取得了不错的成果。但是对于多人场景下人体绝对三维姿态估计任务,除了要估计相对人体三维姿态,更重要的是估计人与相机的绝对位置关系。
当前大多数方法对检测到的人体区域进行裁剪后,分别估计绝对位置。有的方法利用检测框的大小作为人体尺寸的先验,通过网络回归深度信息,但是这样的方法忽略了图像的全局信息;另外一些方法基于一些假设,通过后处理的手段估计人体深度,如地面约束,但是这样的方法依赖于姿态估计的准确度,而且很多假设在实际场景中无法满足(比如人脚不可见)。
我们认为要准确地估计人的绝对三维位置需要利用图像中所有与深度相关的信息,比如人体尺寸、前后遮挡关系、人在场景中的位置等。近年来有很多工作利用卷积神经网络回归场景的深度信息,这启发我们使用网络直接估计场景中所有人的深度信息,而不是在后处理过程中恢复深度。
综上,我们提出了新的单步自底向上的方法估计多人场景的人体绝对三维姿态,它可以在一次网络推理后得到所有人的绝对位置信息和三维姿态信息。另外,我们还提出了基于深度信息的人体关键点匹配算法,包括深度优先匹配和自适应骨长约束,进一步优化关键点的匹配结果。
方法介绍
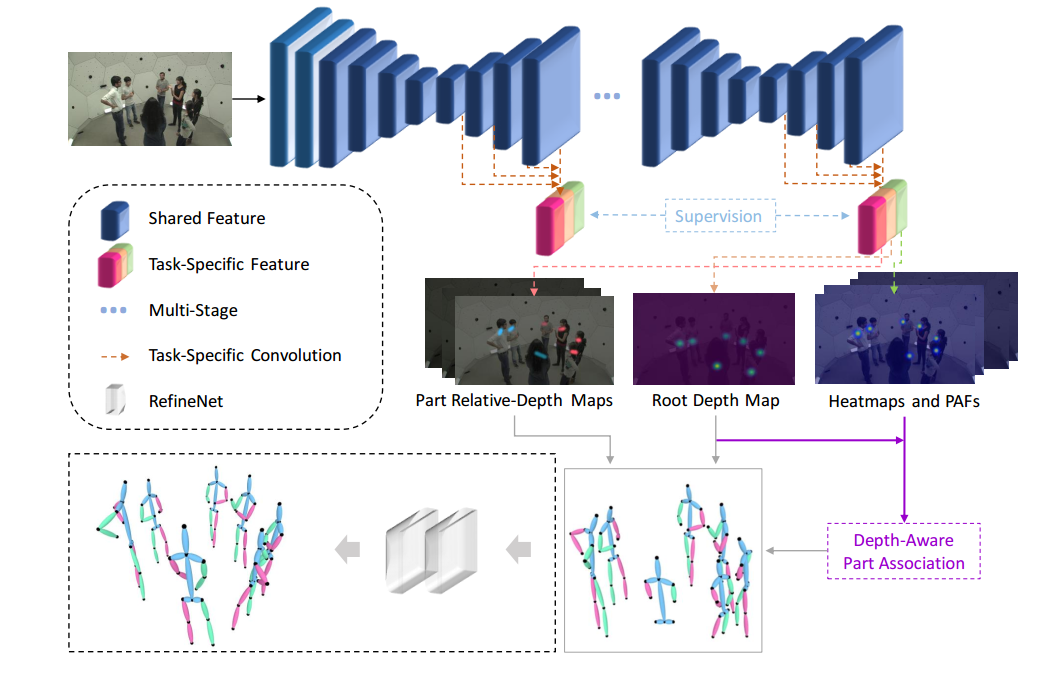
上图展示了所提出方法的流程,包括 SMAP 网络,基于深度的关键点匹配(Depth-Aware Part Association), 和可选的微型优化网络(RefineNet)。输入一张彩色图像,SMAP 网络同时输出人体根节点深度图(Root Depth Map)、二维关键点热度图(Heatmaps)、关键点连接向量场(PAFs)和骨骼相对深度图(Part Relative-Depth Maps)。基于以上的 2.5D 特征表示方法,进行关键点匹配,然后利用相机模型得到人体绝对三维关键点坐标。最后,可以使用微型优化网络对结果进行补全和优化。
2.12.5D特征表示方式
2.1.1人体根节点深度图(RootDepthMap)
由于图像中人体数目是未知的,我们提出了人体根节点深度图来表示场景中人的绝对深度,根节点深度图中,每个人根节点(如脖子或腰部)位置的值表示其根节点的绝对深度,在训练时,只对根节点位置进行监督。其优势在于,不受图中人数限制,并且只需要三维人体姿态数据便可以训练,而不需要整张图的深度信息。
对于同一个深度下的同一个人,具有不同内参(FoV, field of view)的相机会得到不同的二维图像,这对建立二维信息(如人体尺寸)和绝对深度之间的映射关系是不利的,所以需要对输入网络的深度利用 FoV 进行归一化:
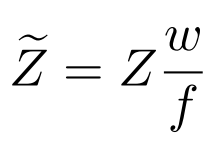

2.1.2Heatmaps和 PAFs
对于二维信息,我们采用与 OpenPose 相同的表示方式。关键点热度图(Heatmaps)表示关键点位于某个像素的概率,关键点连接向量场(PAFs)表示关键点之间相连的方向和概率。
2.1.3骨骼相对深度图(PartRelative-DepthMaps)
骨骼相对深度图生成方式与 PAFs 相同,区别在于它的值表示的是关键点之间的深度差。
2.2基于深度的关键点匹配算法
由关键点热度图(Heatmap)得到人体根节点位置后,便可以从根节点深度图(Root DepthMap)中读取每个人的深度信息,我们利用深度信息进一步优化人体关键点匹配算法,以解决二维关键点匹配算法中存在的歧义性问题。
如图第一行所示,我们提出深度优先匹配,当两个人存在遮挡时,如果同一个关键点有所重叠,单纯基于二维信息的匹配方式无法确定该关键点的所属关系,有可能导致大部分关键点的错连,如第三列所示。而重叠的关键点在绝大多数场景中应该属于前一个人,所以基于网络推断的深度信息,我们给予靠近相机的人更大的连接优先级,如第四列所示。 另外,我们还提出了自适应骨长距离约束。在二维匹配算法中,一般设置图像宽度的一半为关键点匹配的距离约束,但是由于人与相机距离不同,在二维图像中呈现的尺寸不同,固定的约束无法起到很好的效果,如图中第二行第三列所示。对于每个骨骼,我们使用训练集中该骨骼的平均长度作为其实际长度,然后利用网络输出的深度计算其在二维图像中的最大长度如下:
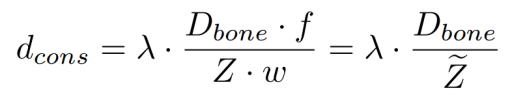

2.3绝对三维姿态恢复
由基于深度的匹配算法获得人体关键点匹配结果后,可以由根节点绝对深度和骨骼相对深度得到每一个关键点的绝对深度,然后利用如下公式
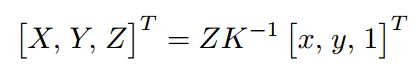
反投影得到人体关键点绝对三维坐标。其中 K 是相机内参矩阵,在绝大部分应用中都是已知的,如果未知,可以使用估计值。
由上述步骤恢复的结果可能会引入两种误差:由于骨架是以级联的方式表示的,在恢复末端关节点深度时,会有累计误差;另外,严重的遮挡和图像截断会导致人体某些关键点的缺失。对此,我们提出了微型补全网络 RefineNet,输入估计的相对二维和三维关键点坐标,输出优化和补全后的相对三维关键点坐标。RefinNet 并不会对人体根节点绝对深度进行优化。
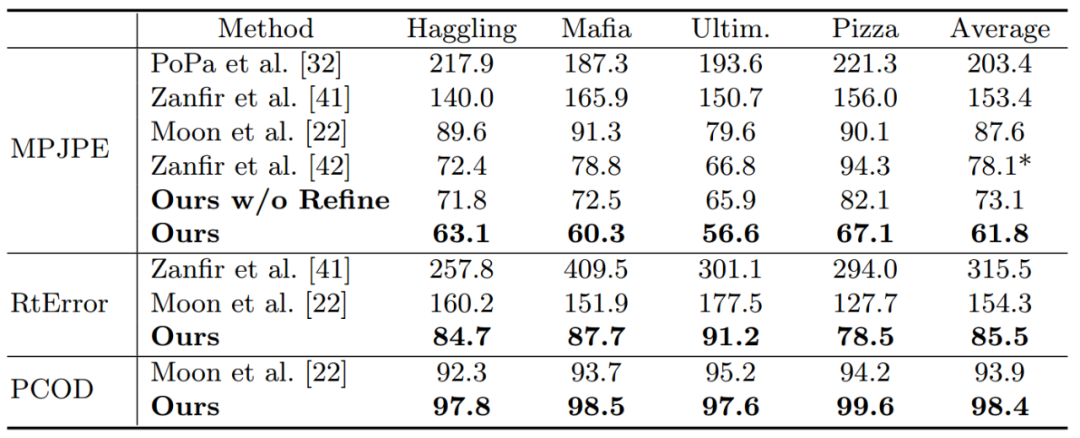
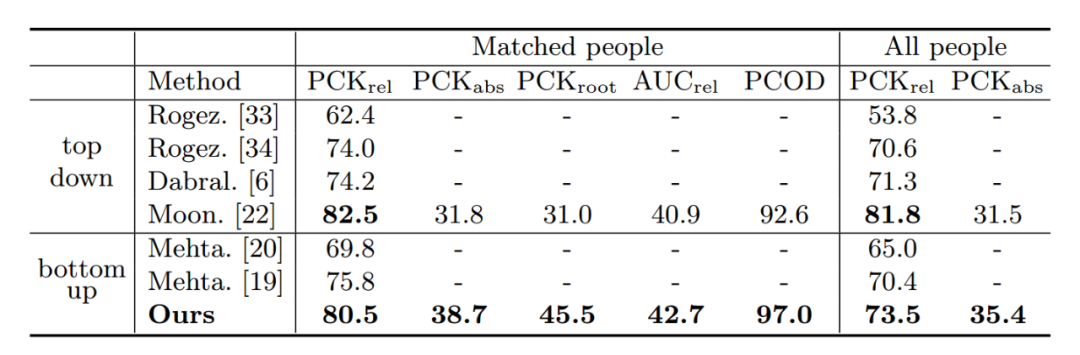
实验结果 我们提出的方法在 CMU Panoptic 和 MuPoTS-3D 多人三维人体姿态估计数据集上均达到 SOTA。
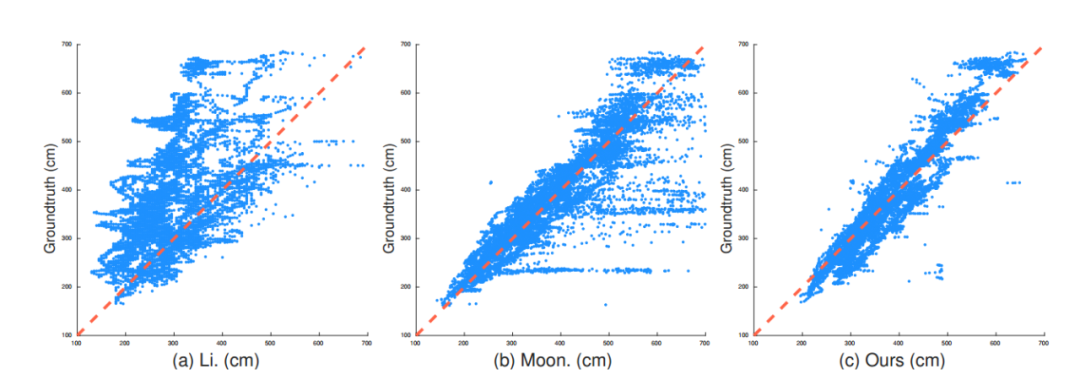
另外,我们对不同可选的深度估计方法进行了对比。第一种,回归全图的深度[1],如图第一列;第二种,根据检测框的尺寸回归人体深度[2],如图第二列。散点图的横坐标为人体深度估计值,纵坐标为实际值,散点越靠近 x=y 直线说明回归的深度越准确。可以看出,我们提出的方法(Root Depth Map)具有更好的深度一致性和泛化能力。
为了体现单步自底向上网络相对于自顶向下网络[2]的优势,我们进行了定性分析。图中左边为自顶向下网络的结果,可见自顶向下的方法会受到姿态变化、人体遮挡、人体截断的影响,而我们提出的自底向上的方法可以利用全局信息缓解这个问题。
-
三维
+关注
关注
1文章
507浏览量
28971 -
匹配算法
+关注
关注
0文章
24浏览量
9376 -
SMAP
+关注
关注
0文章
4浏览量
8845
原文标题:ECCV2020 | SMAP: 单步多人绝对三维姿态估计
文章出处:【微信号:tyutcsplab,微信公众号:智能感知与物联网技术研究所】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
基于OpenGL 的汽车转向三维模型设计
三维快速建模技术与三维扫描建模的应用
三维模型的空间匹配与拼接

利用并查集的多视匹配点提取算法

彩色分割立体匹配的三维目标快速重建
图像匹配应用及方法

什么样的点可以称为三维点云中的关键点呢?
总结!三维点云基础知识





 工商网监
工商网监
评论