 卷积神经网络能用INT4为啥要用INT8?
卷积神经网络能用INT4为啥要用INT8?
1
性能挑战
企业日益重视基于 AI 的系统在数据中心、汽车、工业和医疗等领域中的产品化。
这带来了两大挑战:
AI 推断需要完成的计算量成数量级增加,同时还要保持价格、功耗、时延和尺寸大小不变。 AI 科学家继续日复一日地在算法和模型上开展创新,需要各种不同的硬件架构提供最佳性能。
2
方案概述
对于 AI 推断,在提供与浮点媲美的精度的同时,int8 的性能优于浮点。然而在资源有限的前提下,int8 不能满足性能要求,int4 优化是解决之道。通过 int4 优化,与现有的 int8 解决方案相比,赛灵思在实际硬件上可实现高达 77% 的性能提升。赛灵思4 位激活和 4 位权重 (4A4W) 全流程硬件友好型量化解决方案可实现更优异的精度/资源权衡取舍。
该白皮书介绍了在Zynq UltraScale+ MPSoC 和 Zynq-7000 SoC 系列(16nm和28nm)上面向CNN4位XDPU实现的低精度加速器。这种加速器通过高效地映射卷积计算,充分发挥其DSP功能。这种解决方案可提供优于XDPU两倍的解决方案级性能。在ADAS系统中执行2D检测任务时,这种实现方案能在ZynqUltraScale+MPSoCZCU102板上实现230fps的推断速度,与8位XDPU相比性能提高1.52倍。
此外,在用于ADAS系统中的不同任务时,该解决方案可实现媲美全精度模型的结果。
3
技术导读
对持续创新的强烈需求需要使用灵活应变的领域专用架构 (DSA)。优化 AI 推断性能和降低功耗的主要趋势之一是使用较低精度和混合精度。为降低硬件设计复杂性,模型量化被当作关键技术应用于各类硬件平台。大量工作被投入用于最大限度地降低 CNN 运算量和存储成本。这项研究充分地证明,对于大多数计算机视觉任务,在不严重牺牲精度的情况下,权重和激活可以用 int8 表达。
然而对于某些边缘应用而言,硬件资源仍然不足。在对边缘应用使用较低的位宽(如 1 位、2 位)时,一些常见的硬件设计解决方案使用简化的乘法器。尽管这些解决方案时延低、吞吐量大,但它们与全精度模型相比,仍然存在较大的精度差距。因此,在模型精度和硬件性能之间寻求平衡变得至关重要。
赛灵思运用几种常见的网络结构(ResNet50V1、ResNet50V2 、MobilenetV1和MobilenetV2),在 ImageNet 分类任务上通过使用几种不同的量化算法进行了实验。结果显示精度随着位宽减少而下降。尤其是在位宽低于 4 时精度下降显著。此外,赛灵思也使用 Williams 等介绍的 Roofline 模型,分析不同位宽下的硬件性能。
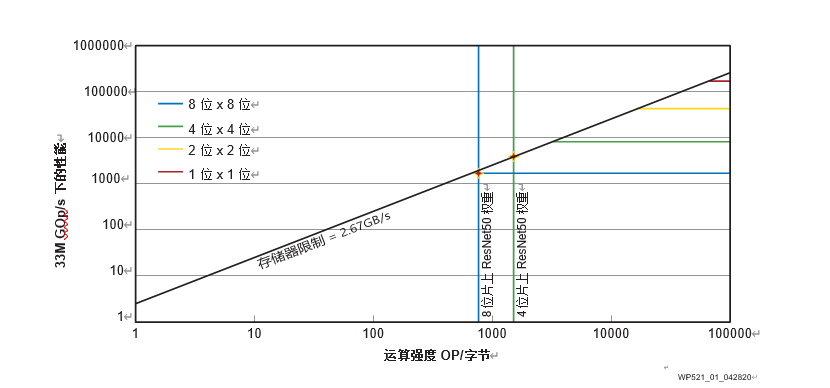
在ZCU102上以不同位宽运行Roofline模型
如图 1 所示,以赛灵思 ZCU102 评估板为例,随着 MAC 的精度降低,硬件成本降低,性能得到提高。此外,实验结果还显示,低比特量化可通过降低存储器需求提高性能。这在 ResNet-50 神经网络的卷积运算强度上得到证实。该网络分别用 8 位精度和 4 位精度进行了运算。因此,int4 在模型精度和硬件性能之间实现了最佳权衡。
-
神经网络
+关注
关注
42文章
4773浏览量
100889 -
AI
+关注
关注
87文章
31097浏览量
269428 -
adas
+关注
关注
309文章
2186浏览量
208704
原文标题:卷积神经网络能用 INT4 为啥要用 INT8 ?- 最新白皮书下载
文章出处:【微信号:FPGA-EETrend,微信公众号:FPGA开发圈】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐





 工商网监
工商网监
评论