 解读英特尔GPU架构
解读英特尔GPU架构
来源:半导体行业观察
在英特尔2020年度架构日中,英特尔将大量时间用于讨论公司的GPU架构计划。虽然这对英特尔来说并非罕见,但目前该公司仍然以CPU内核而闻名。因此,他们在图形方面的市场关注度一直较弱。但是正如英特尔在其他领域的举措,随着时代的变化,英特尔不仅将越来越多的裸芯片投入到GPU中,而且在接下来的两年中,他们正在转变为PC GPU领域真正意义上的第三人,并且推出了他们的首个产品:独立GPU。
从英特尔曾宣布的Xe GPU架构可以看出,该公司打算成为一家自上而下的GPU供应商。这意味着Intel要为数据中心和HPC集群到高端游戏机和笔记本电脑的所有产品提供分离式和集成的GPU。由于这些涉及到大量的工程设计,因此对于一家在过去十年中仅提供集成GPU的公司来说,这是一次巨大的飞跃。但终于在经过数年的讨论和展望之后,英特尔客户想象中的Xe即将成为现实。
我们将在其他文章中重点介绍与Xe相关的内容,本文的重点内容是Xe-LP。我们先快速回顾一下英特尔Xe计划的现状,目前的最新动态以及Xe-LP更大的适用范围。
早在2018年首次宣布时,英特尔就制定了针对单个GPU架构Xe的计划,该架构由三个不同的微架构组成:Xe-LP,Xe-HP和Xe-HPC。Xe-LP分别从底部到顶部跨越市场,并进入集成和入门级离散图形,然后Xe-HP进入发烧级和数据中心部分,最终Xe-HPC将用于高性能计算集群。例如,即将到来的Aurora正是美国能源部期待已久的超级计算机。
从那时起,英特尔对该计划进行了一些修订,曾经的三个微体系结构变成了四个。在今天的英特尔年度架构日中,英特尔宣布推出Xe-HPG,这是针对游戏芯片的另一种微架构。本文将重点讨论Xe-HPG,而这正是英特尔产品堆栈中缺失的高层次难题,因为与Xe-HP相比,它提供了高性能的游戏和图形芯片。该芯片聚焦于数据中心功能,例如FP64和多区块可伸缩性。Xe-HPG计划将于2021年启动,与Xe系列的其他产品不同的是,Xe-HPG将完全由第三方工厂制造。
由于Xe-LP再次引发热议,今年英特尔首款Xe微体系结构的推出变得更加重要。为了应用于更广泛的设计,英特尔针对Xe的计划包括建立连续的Xe部件(对Xe-HPC而言,这一点尤为重要)。该设计包含越来越多的基本构建基块以扩展GPU的数量(即便如此还是不够)。因此,Xe-LP是Xe系列的基础,这一点不仅适用于图形,也适用于架构。英特尔为Xe-LP设计的产品将对整个Xe产品堆栈产生重大影响。
Xe-LP:与Tiger Lake集成,但属于分离式
英特尔针对Xe的产品计划虽然看似将它们推广到了更广泛的领域,但这正是由于英特尔GPU始终具有一个相同的起点:集成显卡。作为英特尔新推出的Tiger Lake SoC的一部分,Xe和Xe-LP将在市场上首次亮相,该公司将于9月2日推出该芯片。尽管英特尔并没有谈论Tiger Lake产品方面的其他内容(英特尔宁愿保留今天的架构,也不愿在9月发布产品),但Tiger Lake显然是Xe-LP设计的重点。因此,正如我们在讨论Xe-LP的功能时所得出的结论:是 Tiger Lake促成了这一切。
今日,据英特尔官方透露, Tiger Lake的零件只用一个Xe-LP切片就明显达到极限。现在,这一代产品已经成为Intel基本的GPU执行单元(EU)中的96个。总体而言,该公司的目标是使Ice Lake(Gen11)图形的性能提升至2倍。
但是Xe-LP不仅仅应用于Tiger Lake。正如英特尔先前所披露,该公司正在开发分布式GPU版本,他们将其称为DG1。DG1的设计用于与笔记本电脑和其他移动设备中的Tiger Lake配对。DG1是20多年来英特尔首款分布式GPU,也是英特尔GT3和GT4e集成GPU配置的精神继任者。相较于使用大型GPU来构建小批量CPU设计,英特尔更倾向于OEM厂商出售的分布式GPU,该GPU基于集成GPU的体系结构和10nm SuperFin工艺。
DG1将于今年发货,所以敬请期待它在性能更高的Tiger Lake笔记本电脑中出现。但是,英特尔在其他方面的披露很少,因为他们今天没有谈论有关产品配置的其他信息。因此,尽管我们知道它基于Xe-LP并且专注于移动设备(英特尔已排除了应用于台式机的所有可能性),但我们没有任何诸如配置或内存等内容的官方详细信息。
作为最终支柱,服务器空间会留在Xe-LP上。英特尔将为他们称为SG1的服务器提供一个四核GPU产品。这个基于四个DG1 GPU的产品将替代英特尔的Xeon可视化计算加速器系列。Xeon VCA卡旨在利用英特尔早期的集成GPU,其以英特尔的QuickSync媒体模块来加速该过程,从而瞄准视频编码市场。现在,英特尔拥有分布式GPU,因此他们不再需要为视频编码市场组合CPU,而可以仅使用GPU出售加速器。对于更大的GPU生态系统来说,这是一个利基市场。但是对于英特尔来说,这是一个至关重要的市场。因此他们希望SG1能使服务器运营商崛起并且获得关注,或者至少摆脱其令人厌恶的寄生虫形象。
Xe-LP功能集:具有可变速率阴影的DirectX FL 12_1
在介绍完了架构深层驱动器之后,本文首先将简要概述Xe-LP的图形功能集。因为此处没有太多新话题要讨论,我将其称为快速摘要。
从API级别的角度来看,Xe-LP的功能集实际上与Intel的Gen11图形集完全相同。与AMD的RDNA1架构不同,英特尔已决定将精力集中在更新GPU架构的底层方面,从而对底层部分进行诸多更改。最终,相对于图形功能而言,上层的变化相对较小。
最终结果是Xe-LP是DirectX功能级别12_1加速器,并且他还具有几个附加功能。尤其是第1层的可变速率阴影(最初在Intel的Gen11硬件中引入)在Xe-LP中又回来了。尽管不如更新的2层功能实现强大,但它提供基本的VRS支持,并且游戏可以按每次渲染请求设置。值得注意的是,英特尔仍然是唯一支持第1层的供应商。AMD和NVIDIA已经(或正在)直接进入第2层。

至少对英特尔来说这是一个好消息,在AMD将其逐步纳入其所有产品之前,他们已经在Gen11方面领先于这场比赛,甚至为其最慢的集成GPU都提供了12_1支持。因此,在这一点上,英特尔仍然可以与其他集成显卡解决方案相提并论。
不利之处在于,这也意味着英特尔是唯一一家在2020年推出不支持下一代功能的新GPU /体系结构的硬件供应商,Microsoft&co将其命名为DirectX 12 Ultimate。功能级别12_2面向消费者的商品名DirectX Ultimate结合了对可变速率着色第2层的支持,以及光线跟踪,网格着色器和采样器反馈。对英特尔而言,能否在2020年的集成部分进行光线追踪的始终是一个很大的疑问。但是能有所进展已经令人欣慰。另外,由于它是不带12_2功能的独立GPU,因此DG1显得有些奇怪。
Xe-LP切成薄片:96个EU扩大50%
英特尔没有把重点放在高级图形功能上,而是将注意力转移到了GPU的低级架构细节上。Xe-LP是未来Xe GPU的奠基石,因此,在这个领域,英特尔需要正确地处理设计和功率效率方面的问题,以便为构建未来的产品奠定稳固的基础。 可以肯定的是,英特尔早期GPU设计中的基础类比范围也是如此。尽管Xe是一个新的品牌,并且是英特尔更大的起点,但它并不是仅仅是英特尔GPU的设计。相反,它是Gen11的重点发展,其更新和替换了出于可伸缩性或效率方面的原因而需要更改的那些位。因此,Gen11可以保留很多东西,而Intel GPU的基本组织结构保持不变。

与往常一样,这意味着我们将从Xe-LP Slice和英特尔的总体GPU设计目标开始。英特尔公司最大的通用构建块,即公司的GPU分为一个或多个切片,一个切片包含计算和渲染所需的核心功能块的完整副本。这包括几何图形和栅格前端,线程分配硬件,EU本身,纹理单元以及ROP像素后端。
英特尔借助Xe-LP将片中的几乎所有内容扩展了50%。这意味着与Intel的Gen11 iGPU碰巧只占一小块的情况相比,在GPU的大多数方面都可以多执行50%的执行硬件。这包括增加50%的EU(使总数增加到96个EU),纹理单元和ROP,总速率分别为48像素/时钟和24像素/时钟。

切片中没有被这样一个因素明确放大的唯一部分是前端。仍然有一个单独的几何/栅格化器/像素调度前端为切片的其余部分提供数据,并且由于Intel尚未披露几何吞吐量的任何变化,我在这里假设Intel仍仅按时钟每时钟调度1个基元片。因此,任何改进都必须取决于时钟速度。 而且时钟速度肯定在提高。与英特尔的Willow Cove CPU内核一样,该公司正在努力提高其新的10纳米SuperFin工艺的能效和时钟速度的改进,以使其能够提高GPU时钟速度以满足其性能目标。正如我们之前讨论的那样,英特尔希望在这里将Gen11的GPU性能提高一倍,而执行硬件的50%最多只能满足一半的需求,其余的大部分增长将来自更高的时钟速度。作为参考,英特尔的Ice Lake部件最高达到1.1 GHz,因此,鉴于英特尔的性能预测,看到Tiger Lake和DG1达到1.6 GHz或更高的频率也就不足为奇了。
因此,完善英特尔提高GPU性能的计划来自Xe-LP设计的第三大支柱:提高效率。EUs的增加促使了FLOP的增加,而提高能效使Intel可以将芯片的时钟提高到更高,以增加更多FLOP。但是仅增加FLOP是不够的,体系结构的有效吞吐量还必须提高,这样才能将更多的理论上的FLOP转化到(convert?)实际工作中。
这就是英特尔秘诀的来源,而英特尔技术市场部门的贡献并不多。我们会在短时间内对EU进行一些显著的低层更改,但这些更改更多是关于推动上述电源效率更改。相反,吞吐量效率的变化更加模糊。在这里,英特尔只是告诉我们,他们已经使用工作负载分析来识别并消除整个GPU中的多个小瓶颈,从而提高图形和计算吞吐量的效率。 英特尔的L1缓存更改也可能在其中起作用,尽管该公司目前并没有过多地考虑这些更改。不过,我们将在查看整个内存系统时再稍作讨论。
分片重组
另一方面,扩大总体范围导致英特尔已经重组了更大范围内的子范围。子切片在某些方面类似于NVIDIA SM和GPU中的一个较小的构建块,其专注于各种形式的计算和着色以及纹理化。对于英特尔的Gen11 GPU,该公司将GPU分为8个子切片,每个子切片包含8个EU。但是,使用Xe-LP可以扩大每个子分片的数量,并减少总分片的数量。
Xe-LP上的完整片现在是6个子片。每个Xe-LP子片段依次看到其许多属性都翻了一番。子切片中的EU数量增加了一倍,达到16个,而子纹理采样器的吞吐量已从4像素/时钟提高到8像素/时钟。每个子切片还获得一个L1数据/纹理缓存,该缓存为64KB,可以在L1数据和纹理存储之间动态分配。该缓存似乎将取代Gen11记录不充分的L2缓存,后者在层次结构中扮演着类似的角色。 这些子更改又与英特尔对EU所做的一些更改并存,我们将在下一页介绍这些更改。由于EUs失去了一点点独立性并变得结对,每个子线程的线程控制单元数保持恒定为8。因为总体而言它们需要处理和管理的子线程更少了,所以这可能有助于英特尔针对未来解决方案的可扩展性。 这一变化的结果意味着,英特尔的iGPU可扩展性步骤也将有所不同。Ice Lake出厂时启用了64个EU(8个子分区),48个EU(6个子分区)或32个EU(4个子分区),具体取决于SKU,而Tiger Lake的粒度现在仅为切片的六分之一。因此,这意味着一半的GPU现在为48个EU(3个子分区),一个完整的GPU为96个EU(6个子分区),并且英特尔必须决定是否以及如何在启用80或64个EU的情况下在中间运输SKU。由于英特尔今天不提供生产信息,我们只能进行相关推测。但是如果在完全启用的Xe-LP iGPU之后的下一层是64 EU配置,则其性能将大大下降,造成了33%潜在增长的损失。
Xe-LP执行单元:成双成对
更深入地讲,我们拥有Xe-LP GPU架构中最小的线程级构建块,即古老的执行单元。多年来,英特尔已对其进行了几次调整,而对于Xe-LP,它们又在进行调整。 作为快速更新单元,截止到英特尔的Gen11 GPU架构为止,EU由一个线程控制单元和两组4宽SIMD组成。一个块处理浮点数和整数运算,而另一块可以处理浮点数和特殊函数,英特尔将其称为“扩展运算”。尽管如此,Gen11的最小波面宽度为8个线程宽(SIMD8),因此执行一个波面可能需要多个时钟周期,而英特尔会将多个波面交织为一种延迟隐藏形式。

同时,Xe-LP给EU的设计带来了一些重要的变化。首先,一个EU不再是一个独立的大区。现在,两个EU共享一个线程控制单元。结果,线程控制单元现在获得了两个EU(不再是一个)的组合资源来分散工作。尽管SIMD阵列本身也发生了变化,这使问题进一步复杂化,但其影响在于,GPU中的线程控制单元现在越来越少,这将减少在任何给定时刻In-flight波面数量。 实际上,有人争论这两个EU是否为描述它们的最准确方法。最佳选择将它们捆绑在一起作为一个单一的“大EU”,因为这两个部分都不是真正独立的。但是由于缺少更多底层细节,而且我确定英特尔希望在对EU进行计数时保持半一致性,所以他们选择了96个“小EU”。 同时,无论您如何捆绑EU,都存在EU本身的问题。对于Xe-LP,英特尔已经重组了SIMD模块。一对具有功能差异的SIMD4已不再支持SIMD8和SIMD2。较大的SIMD8本质上将先前在Gen11的两个SIMD4模块之间分配的所有浮点和整数ALU组合在一起,并从中分离出一个SIMD8。最终结果是FPU ALU的数量没有改变(每个EU仍然是8个ALU),但是可以处理整数的管道数量已经改变(从4到8),可以扩展的ALU数量也已经改变运算法则(从4到2)。
说到这一点,扩展运算现在已移至其自己的SIMD2,并且每个EU都有一个。这意味着执行扩展的数学函数不再像Gen11那样直接阻止浮点算术的执行(EU不必为此放弃FP管道)。需要着重强调的一点是,EU可以同时向FP / INT SIMD8和EM SIMD2同时发布指令,这意味着在至少某些情况下,进行扩展运算也不会间接阻止FP / INT运算。
与共同发布时出现的问题一样,细节仍然很棘手。在这一点上,我们尚不清楚共同发布的局限性是什么。但它仍然很可能更适合英特尔实际看到的那种工作负载。AMD和NVIDIA还使用专用的EM / SFU单元,并且比例也很小,对于这两家公司来说,所有这些似乎都很好。因此,在这方面,英特尔的ALU设置看起来更像是它的现代竞争对手。我怀疑,这也是英特尔为了从Xe-LP上相同数量的FLOP中获取更多效果而做出的瓶颈优化形式之一。 这些ALU更改还会影响波面在GPU中的移动方式。SIMD8是常规算术中最小的ALU阵列,英特尔的最小波面尺寸现在与底层硬件相同。这意味着Xe-LP至少在最小波面尺寸的情况下,不再需要多个周期来在单个周期内从波面执行一条指令。在Gen11中,英特尔还允许存在SIMD16和SIMD32波阵面,而我正在等待Xe-LP白皮书以确认是否保留了这些(在这种情况下,它们仍然需要多个周期),或者英特尔是否正在将所有内容强制设为SIMD8。 值得注意的是,这一变化与AMD去年的RDNA(1)架构非常相似,它通过增加SIMD大小并返回其波面大小来消除波面的多周期执行。在这种情况下,这样做是为了帮助保持其SIMD插槽的占用率更高,并减少指令等待时间,如果英特尔也遇到类似的情况,我不会感到惊讶。
这种重组的另一个好处是,英特尔能够从整体上简化其线程调度硬件。直到第11代,英特尔仍在使用硬件记分板来确定何时运行线程以及何时准备就绪线程的数据。但是,借助Xe-Lp,计分板已经转移到软件中,由英特尔编译器来负责。 迁移到软件计分系统意味着必须由软件预先确定计划(这样会使其变得静态,并有可能导致计划不尽人意),好处就是硬件计分板会由于权力立场和模面积变得相当昂贵。因此,转向软件计分制可以实现更小,更省电的EU,这反过来又体现了英特尔建立大量EU并提高整体能源效率的能力。总体而言,这与NVIDIA在十年前通过开普勒对其体系结构所做的更改相对应。他们在开普勒上同样采用了软件记分板,以提高能效(并同时保持高性能)。
数字决定EU吞吐量
现在我们已经有幸看到在EU层面所做的所有更改,下面我们来谈谈这对于EU的实际吞吐率意味着什么。

从浮点开始都很简单。尽管对ALU进行了重组,但每个EU的FP ALU数量仍为8。因此,与Gen11一样,每个EU的FP吞吐量仍保持在16 FP32 ops / clock和32 FP16 ops / clock。 另一方面,对于整数吞吐量,具有整数功能的ALU的数量相对于Gen11体系结构已从4倍增加到8倍。结果,整数吞吐量也增加了一倍:Xe-LP每个时钟周期可以保存8个INT32运算或32个INT16运算,而Gen11分别为4和16。但是,这的确意味着Xe-LP保留了Gen11的不寻常的INT32故障。INT32速率仅是FP32速率的一半,而INT16速率等于FP16速率。 最后,毫无疑问的是Xe-LP没有等效于张量核心或其他脉动ALU的数组来进行密集的数学运算,这已经成为神经网络训练推理的全部方法。该硬件将以Xe Matrix eXtensions(XMX)的形式出现在Xe系列的后面,但现在Xe-LP必须与常规的EU接轨。
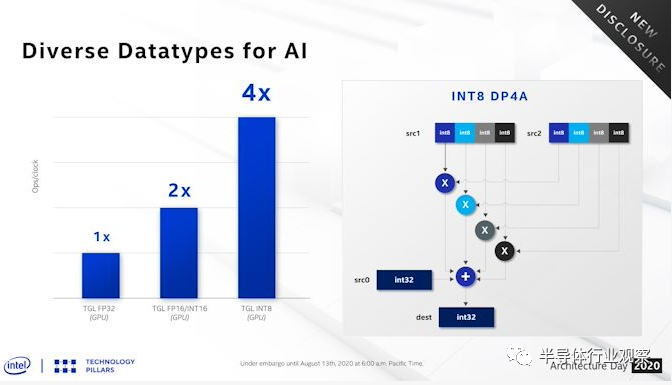
但是出于这个原因,英特尔在其EUSIMD中又增加了一项功能,即对INT8点产品的支持。在过去的几年中,INT8在神经网络推理中变得越来越流行,而点积反过来又是该过程中非常普遍的一种操作。因此,增加对INT8点产品的支持使Xe-LP在这种形式的AI执行中得到了极大的推动。INT8在使用DP4A指令之后,其吞吐率可以高达64 ops / clock,是INT16吞吐率的两倍。
Xe-LP媒体和显示控制器
接下来我们讨论最后一点:Xe-LP架构的GPU的非渲染方面--媒体和显示控制器。此处的更改并不像对核心体系结构的更改那样引人注目,但是在这些功能块中进行的改进通过支持新的媒体格式和新的显示连接协议,有助于使整个GPU保持最新状态。 首先,让我们谈谈媒体引擎。虽说英特尔没有对Xe-LP进行大量修改,英特尔对引擎做了一些明智的添加。此处的选框功能很容易支持AV1解码加速,使Intel成为三巨头中第一个为新编解码器添加硬件解码支持的供应商。
人们普遍期望,即将出现的免版税编解码器将成为H.264 / AVC的真正继任者,因为HEVC进入市场已经有很多年了(并且已经受到最近所有的GPU支持)。编解码器附近的madcap专利使用费情况不利于其采用。相比之下,AV1在分发中的使用应提供与HEVC相似或略好于HEVC的质量,而无需支付版税,这使其对内容供应商的吸引力更大。迄今为止,AV1的一个缺点是CPU占用大量内存。一方面是出于对电池寿命的考虑,而另一方面是确保流畅和无故障的播放,这些都使得硬件解码支持变得更加重要。 同时,类似于英特尔的渲染性能目标,该公司一直致力于提高媒体引擎的编码和解码吞吐量。据英特尔称,更新后的模块现在能够实现高达2倍的编码和解码吞吐量。对于消费类计算机而言这似乎无关紧要,但是对于SG1服务器产品而言,它尤为重要,因为它将专注于批量编码。 最后,在对媒体引擎进行的较小更改中,英特尔增加了对HDR和Dolby Vision播放的官方支持。即使速度很慢,对HDR的支持将继续向PC推广,因此这是确保较新的PC能够处理以这些格式编码的HDR内容的重要一步。同样值得注意的是对英特尔HEVC编码模块的改进。为了在提高具有静态或接近静态图像内容的HEVC压缩率,该模块现在支持HEVC屏幕内容编码(SCC)扩展,
Xe-LP显示控制器:DisplayPort 1.4,HDMI 2.0和8K显示器
最后需要特别提到的一点就是,我们拥有Xe-LP的显示引擎。如同在媒体块方面,这里没有根本性的变化,但是整个过程中都有一些可喜的改进。 也许最大的变化会发生在数年之后,英特尔最终会增加第四条显示管道,这意味着到时候GPU可以驱动四个独立的显示器。在此之前,Gen11和其之前的设计只能处理三个显示器,尽管即使这个数目超出大多数人的使用范围,但四个显示器足以让其他GPU设计难以望其项背。最近对双屏笔记本电脑和其他具有多个显示器的移动设备的推动将会使事情更加复杂化,因为这将吞噬这三个输出中的两个。
值得注意的是,英特尔还添加了第二个嵌入式DisplayPort输出,这对于那些双屏设备非常有用。 否则,其基本显示输出选项会与Gen11相同。Xe-LP支持DisplayPort 1.4和HDMI 2.0。由于HDMI 2.1电视现在已经上市,因此后者有点令人失望,但是对于Intel来说,去花更多的时间来采用更新的HDMI标准并非罕见。这些显示输出还可以馈入USB4 / Thunderbolt 4端口,其中DisplayPort数据是一流的公民,可以复用到信号中,也可以通过alt模式重新配置端口。 虽说在英特尔的框图上并不明显,该公司还是进行了一些重大更改以更好地为显示控制器供电。具体来说,该公司增加了显示引擎可用的带宽,以便处理DisplayPort 1.4设计用于馈送的超高分辨率显示器。因此,该控制器现在具有足够的带宽和内部处理能力,可以驱动8K UHD显示器以及最新一代的360Hz显示器。
性能期望与初衷
英特尔结束了对GPU架构的深入研究,尽管其没有利用今年的架构日来讨论特定的产品和SKU,但公司确实花了一些时间讨论对Xe-LP的性能期望,并在其中提供了一些有关Xe-LP快速图像化的实际行动。遗憾的是,我们不允许录制演示过程(但还是有人泄露了这些演示),但我们将在英特尔向公众发布副本后立即将其发布在此处。
如前所述,无论如何,英特尔的目标是使Ice Lake(Gen11)的图形性能提高一倍,Xe-LP将通过更宽的GPU(更多的硬件),更节能的GPU(允许更高的时钟频率)以及效率更高的GPU(更高的IPC)的组合来实现。考虑到他们没有从全新的工艺节点中受益,这是一个崇高的目标,但是英特尔似乎对其新的10nm SuperFin工艺节点的性能潜力,以及通过向其尝试过的产品中其投入更多硬件获得的回报颇有信心。

通过对Ice Lake和Ryzen 3000“ Renoir”笔记本电脑的评论进行查看,我们可以看到自己的性能数据,如果Intel能够达到其性能目标,那么Tiger Lake应该能够领先于AMD的同类U系列Ryzen APU。一如往常,这将取决于游戏本身,但是在GPU受限的情况下,高端Ice Lake笔记本电脑永远不会落后30%左右。但是,由于我们在谈论移动场景,因此电源和散热始终是可能使笔记本电脑无法使用的潜在威胁。对于超便携式游戏笔记本电脑更是如此,英特尔无疑将希望其合作伙伴制造具有匹配散热功能的笔记本电脑,从而为Tiger Lake提供一切可能的成功机会。 除了帧率,英特尔还希望Xe-LP的性能能够大大提高图像质量的标准。为了提供必要的帧率,集成显卡通常会提高图像质量,因此将iGPU性能提高一倍将使许多游戏可以在更高图像质量设置下运行。这又会因游戏而异,但是至少出于促销目的,英特尔盯上了Tiger Lake / Xe-LP,因为它们能够在Ice Lake只能处理低画质的游戏是以高图像质量运行。
但是Xe-LP不仅是集成的图形解决方案,它还适用于离散图形。尽管我们热切期望获得更多有关DG1的信息,但是鉴于英特尔今天将重点放在产品的架构上,我们所面临的问题多于答案。英特尔针对Xe-LP制定了一个非常有趣且对OEM友好的计划,并且通过为iGPU和可选的离散GPU利用相同的架构。OEM会希望看到,他们将不必验证和加载用于集成和离散GPU的单独GPU驱动程序。 但是,最重要的是,英特尔还拒绝回答与1000万像素的相关问题:Tiger Lake的iGPU是否能够与DG1协同工作?英特尔当然还没有开始抹除这个想法,但是他们也没有证实这一想法。即使这样,如果他们使用多GPU渲染,他们会成功吗?台式机上的多GPU渲染几乎已经消失。这是有原因的:在现代渲染技术下,它往往无法很好地发挥作用,并且可能会增加相当多的输入滞后。有关以上问题的答案,以及英特尔是否能够克服多GPU渲染的传统缺陷,绝对会对DG1 GPU的商业可行性产生巨大影响。因此,我们将热切期望这些问题能够得到回答。

否则,Xe-LP标志着英特尔GPU架构发展的重要一步,不必在意成为自上而下的GPU供应商的计划中的巨大垫脚石。尽管Xe-LP仅面向笔记本电脑,但它是英特尔更大的基础:Xe-LP将成为未来整代GPU的基础。因此,英特尔在功能,架构以及最重要的方面所做的工作,对于从游戏硬件到超级计算机的所有功能,功率效率都会产生巨大的影响。从许多方面来说,这都是英特尔进入新时代的曙光,他们希望这是一个比他们留下的更好的时代。
来源:半导体行业观察
原文标题:企业 | 英特尔GPU架构深度解读
文章出处:【微信公众号:旺材芯片】欢迎添加关注!文章转载请注明出处。
-
芯片
+关注
关注
456文章
50967浏览量
424920 -
英特尔
+关注
关注
61文章
9985浏览量
171971 -
gpu
+关注
关注
28文章
4754浏览量
129081
原文标题:企业 | 英特尔GPU架构深度解读
文章出处:【微信号:wc_ysj,微信公众号:旺材芯片】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
世纪大并购!传高通有意整体收购英特尔,英特尔最新回应

英特尔推出全新英特尔锐炫B系列显卡

英特尔12月或发布Battlemage GPU芯片
Inflection AI转向英特尔Gaudi 3,放弃英伟达GPU
英特尔发布AI创作应用AI Playground,将于今夏正式上线!

英特尔CEO:AI时代英特尔动力不减
在英特尔酷睿Ultra处理器上优化和部署YOLOv8模型
英特尔确认Ponte Vecchio GPU将以云服务形式推出
英特尔逐步停止Ponte Vecchio GPU生产,专注于Gaudi 2/3产品
英伟达、AMD、英特尔GPU产品及优势汇总
X-Silicon发布RISC-V新架构 实现CPU/GPU一体化


英特尔首推面向AI时代的系统级代工—英特尔代工







 工商网监
工商网监
评论