 深度学习将对音频处理产生深远影响 亚马逊团队深度噪声抑制挑战赛中获胜
深度学习将对音频处理产生深远影响 亚马逊团队深度噪声抑制挑战赛中获胜
该团队的非实时系统是性能最好的,而它的实时系统在整个系统中排名第三,在实时系统中排名第二,尽管只使用了4%的CPU核心。
文 / Arvindh Krishnaswamy 原文链接: https://www.amazon.science/blog/amazon-team-takes-first-place-in-interspeech-2020-deep-noise-suppression-challenge
在电子语音通信中,噪音和混响不仅会损害语音清晰度,而且会导致听者在长时间努力理解低质量语音时感到疲劳。在COVID-19大流行期间,我们花在远程会议上的时间越来越多,这一问题比以往任何时候都更加重要。 在今年的Interspeech会议上的深度噪声抑制挑战便是为了帮助解决这个问题的一个尝试,分别在实时语音增强和非实时语音增强上进行比赛。在19个团队中,Amazon取得了最好的结果,在非实时赛道上获得了第一名(阶段1 |阶段2-final),在实时赛道上获得了第二名。
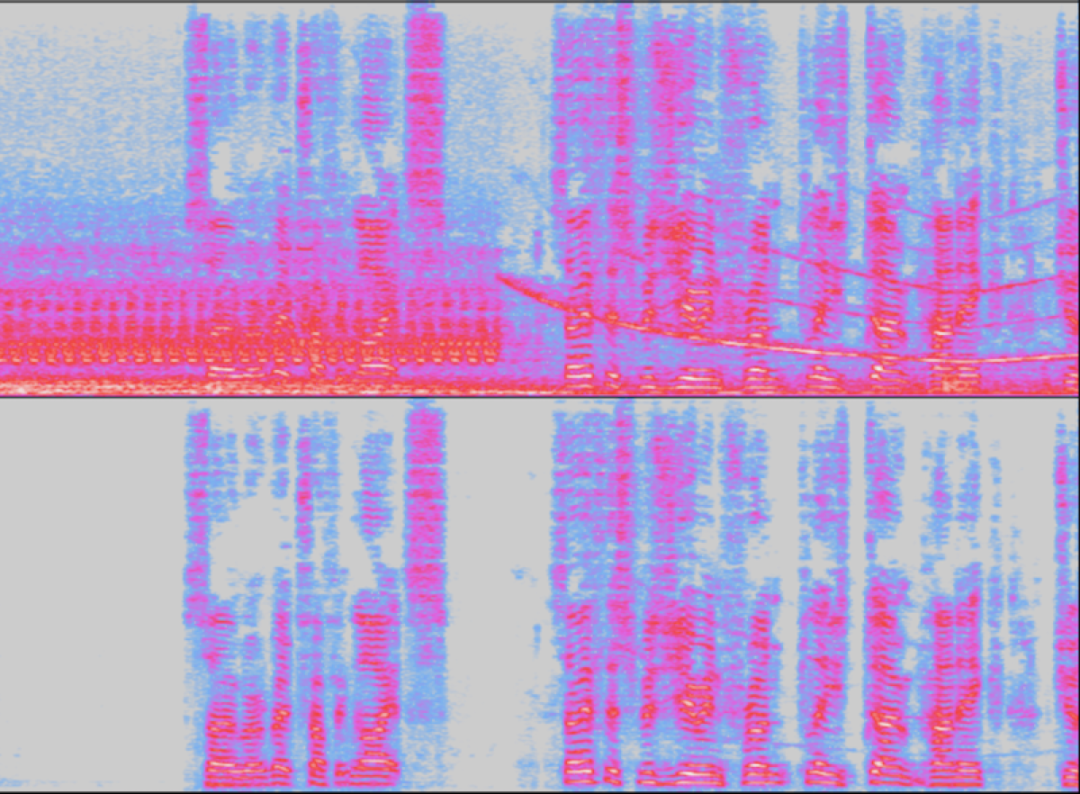
上面是一个有噪声的语音样本(上图) 下面是被研究者的系统抑制了噪声的同一个样本(下图) 为了满足真实世界的需求,我们将实时输入限制在CPU使用量的4%(在i7-8565U内核上测量),这远远低于竞赛所允许的最大限度。 然而,我们的实时输入非常接近(0.03平均意见分数)的第一名,并且击败了其他非实时的输入。 Amazon团队实时和非实时噪声抑制结果的音频示例可以在这里找到。 我们还发表了两篇论文(paper1-offline | paper2-real)来更详细地描述我们的技术方法。 在Interspeech中获胜的技术已经在Alexa通信公告和Drop in Everywhere功能中发布,并且从今天开始,我们的客户也可以通过使用Amazon Chime苹果macOS和微软Windows客户端来进行视频会议和在线会议。
优化的感知 传统的语音增强算法使用人工调整的语音和噪声模型,通常假设噪声是恒定的。 对于某些类型的噪音(例如汽车噪音),在噪音不太大或低混响的环境下,这种方法工作得相当好。不幸的是,它们经常在非平稳噪音上失败,比如键盘噪音和杂音。因此,研究人员转向了深度学习方法。
语音增强不仅需要从噪音和混响中提取原始语音,而且需要以一种人类耳朵感觉自然和愉快的方式进行。这使得自动回归测试变得困难,并使深度学习语音增强系统的设计复杂化。 我们的实时系统实际上通过直接优化了语音的感知特征(spectral envelope and voicing),利用了人类的感知因素同时忽略了与感知无关的方面。由此产生的算法产生了最先进的语音质量,同时保持非常高的计算效率。 对于非实时系统,我们采取了一种不妥协的方法,使用改进的U-Net深度卷积网络从增强的语音压缩每一点可能的质量,从而赢得了输入挑战。
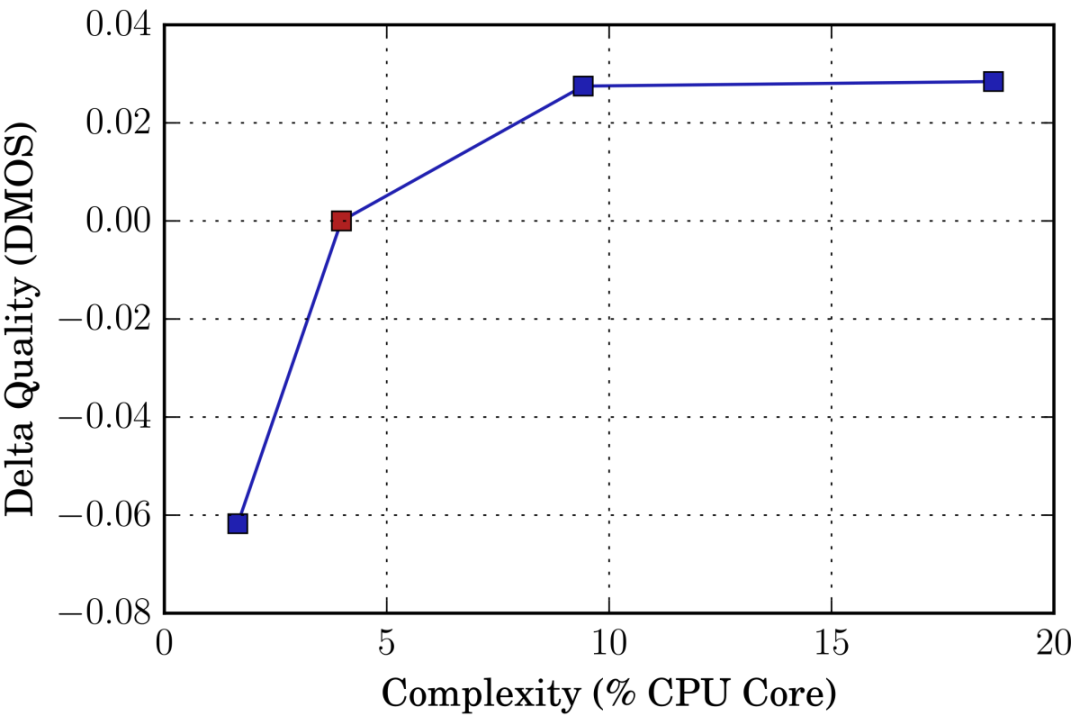
一描绘经被允许使用的研究人员的实时系统的百分比中央处理器核心降噪后的一语音样本的平均意见分数(MOS)的变化的图像 在深度噪声抑制的挑战中,经过处理的音频示例被盲发送给人类听众,由他们对其进行评分,产生平均意见分数(MOS)。 在实时应用程序中,复杂性和质量之间总是需要权衡的。 右边的图显示了我们如何通过增加CPU需求来进一步提高实时提交的质量,或者通过牺牲一些质量来进一步节省CPU的使用。 红点表示提交挑战的实时系统,图像显示了MOS分数相对于不同CPU负载的变化。
人们普遍认为,深度学习最终将对音频处理产生深远影响。 虽然仍有很多挑战,比如数据增强,感知相关的损失函数或者处理看不见的情况,但未来依然非常令人兴奋。
原文标题:亚马逊团队在Interspeech 2020深度噪声抑制挑战赛中获得第一名
文章出处:【微信公众号:LiveVideoStack】欢迎添加关注!文章转载请注明出处。
-
cpu
+关注
关注
68文章
10872浏览量
211999 -
MOS
+关注
关注
32文章
1272浏览量
93855 -
噪音
+关注
关注
1文章
170浏览量
23910 -
亚马逊
+关注
关注
8文章
2668浏览量
83408 -
深度学习
+关注
关注
73文章
5504浏览量
121222
原文标题:亚马逊团队在Interspeech 2020深度噪声抑制挑战赛中获得第一名
文章出处:【微信号:livevideostack,微信公众号:LiveVideoStack】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
EDA精英挑战赛赛果公布!思尔芯“战队”薪火相承斩获“麒麟杯”







 工商网监
工商网监
评论