 KVM并不是想象中那么难
KVM并不是想象中那么难
那些不能铭记过去的人注定要重蹈覆辙。你还记得当年用Windows隐藏文件夹藏片吗?
作为一个屌丝,虚拟化技术确实意义非常重大。这个最显著的作用显然就是藏片,作为一个程序员,如果还用Windows文件隐藏功能来藏片,这实在是污辱自己和女朋友的智商,让广大码农抬不起头来做人。最早可以帮你实质藏片的手段来自VMware。
VMware这个名字就是一种牛逼,VM就是virtual machine,ware是取自Software中的ware,1999年VMware发布了它的第一款产品VMware Workstation,在那个赛扬333和白衣飘飘的时代。
上面一幅图看起来比较嗨皮,但是技术含量确实不低。你想在一个电脑上面,虚拟出来一个“假”电脑,但是一定要“假”到什么程序呢?就是苍老师在跑的时候,她意识不到这是个“假”电脑。造假从来都不是那么容易的事情。会面临来自CPU、内存、I/O的全方位障碍。
先说CPU方面,为了避免应用弄死整个系统,除了一些裸奔的RTOS(实时操作系统)以外,现代操作系统一般借助CPU的不同模式来将操作系统内运行的软件切割为用户态和内核态。用户态只能执行常规的CPU指令如运算,但凡涉及到访问特定的硬件,如MMU、I/O等,用户态的应用就需要陷入内核态,调用内核的系统服务来完成。
比如下面最简单一段程序:
int main(int argc, char **argv)
{
int i;
for(i=0;i<10000;i++);
write(1, “hello ”, 6);
for(i=0;i<10000;i++);
return 0;
}
其中for(i=0;i<10000;i++);这样的语句是在用户态执行的,而write(1, “hello ”, 6);则通过系统调用陷入到内核态。
这个陷入,不仅是软件的一种变化,也是硬件模式的一种跨越。X86的处理器模式也从ring3非特权模式切换到了ring0特权模式了。非特权这样的模式,可以保证用户空间想干坏事也干不了,干了坏事就现场被抓。

那么问题就来了,没有虚拟机guest的情况下,ring0只有主机操作系统一个人玩,这个是丝毫没有什么问题的。有多个guest OS的情况下,guest OS的内核也想在ring0玩(至少它要觉得自己在ring0玩),但是事实上是它不能占据ring0,否则就变成了宋哲,控制了不该控制的资源。这个时候,我们必须给guest OS做“特权解除(De-privileging)”,比如把guest OS的kernel放入权限更低的ring1。但是,我们必须给它模拟出还是在ring3和ring0跑的样子,因为OS原本是这样理解的,全虚拟化的本质让它感知不到被虚拟化了,就是追求这个等价性。既然苍老师喜欢看到guest OS的内核在ring0建设社会主义的样子,我们就要把苍老师给蒙骗过去。
模拟出还是ring0和3的样子,这个事情还真的是不简单。现在guest OS用户态和内核态分别运行在CPU的ring3和ring1,然后苍老师在的Windows的内核想读CPU的一个寄存器知道CPU现在在什么状态,假设这个指令叫做ABC,由于现在虽然苍老师Windows在内核态,但是CPU实际处于ring1,所以她读到的是ring1,这显然不符合应有的期待,虚拟化后苍老师应该读到ring0才对!
ABC这样的指令关乎到系统全局资源的状态读取或者设置,我们一般称呼这样的指令为敏感指令(Sensitive instruction)。假设ABC这条敏感指令同时也是一条特权指令(Privilege instruction,在非特权模式执行的时候会引发硬件陷入特权模式的ring0),那么苍老师读CPU的状态的时候,陷入ring0,我们在ring0的VMM(virtual machine monitor)代码里面伪造一个ring0值给苍老师就万事大吉了,这就是典型的“陷入-模拟”。只要能陷入,咱们就能模拟,就能制造幻觉。
如果所有的敏感指令都是特权指令,我们显然是可以完美通过这种“陷入-模拟”的方法来实现虚拟化的。实际上,大部分敏感指令确实是特权指令。但是,无论是早期的X86,还是ARM,都有些敏感指令不是可以陷入的特权指令,我们称呼它们为临界指令(critical instruction)。不陷入就无法模拟,又关乎系统资源的读取和设置,系统资源就像全局变量,主机看虚拟机也看,这个虚拟机看,那个虚拟机也看,你看我也看,那么显然是无法实现逻辑上的隔离了。我们显然需要把跨机器的全局变量变成虚拟机内的模块级变量才靠谱。

早期为了解决上述问题,人们一般采用2种办法:
半虚拟化(para-virtualization)
直接在guest OS里面把无法虚拟化的部分代码改掉,把ABC指令替换成一个陷入ring0的系统调用,既然你不陷入,哥就强行拉你下水。这显然就不是全部的虚拟化了,这种叫做半虚拟化(para-virtualization)。
二进制翻译( binary translation )
不改代码,比如看到ABC这样的指令,提前插入断点来截获之,交由 VMM 解释执行,我们就把它强行翻译为别的东西。其实这个也有那么一点类似半虚拟化,你可以认为半虚拟化的改代码在编译前,而二进制翻译的改代码在运行时。
通常我们认为运行时候改,会比编译前改,逼格要高那么一点点。
由于半虚拟化需要系统内核的深度修改,在生产环境中,半虚拟化在技术支持和维护上会有很大的问题,早期的Xen就是用的这种方法。而早期的VMware用的手段则是进行二进制翻译( binary translation ),把这些指令翻译执行,不让它的实际指令执行。翻译的意思,就是类似明明我干的就是ABC,它替换为xxxx,yyyy,zzzz,然后欺骗苍老师现在是ring0:

这是虚拟化的诉求,也是历史的痛苦。当然现在已经不是苍老师的时代了,遥想公谨当年,苍天有井独自空,星落天川遥映瞳。小溪流泉映花彩,松江孤岛一叶枫。哎,时代的车轮滚滚向前,碾压着每一个屌丝。房子永远越来越贵,家庭成本越来越高,码农越来越老,外企个个在跑,每每念及此处,心里孤单又寂寞。
现在无论是X86还是ARM,都通过修改CPU架构,解决了上述问题。Intel Virtualization Technology (VT-x) 和AMD’s AMD-V这样的硬件虚拟化技术,在CPU引入一个新的模式VMX Root Mode。
Guest OS运行于non-root下的ring0,Guest OS上面的应用运行于non-root模式下的ring3,而host OS的内核和VMM则运行于root模式下。这样做的一个好处是,对guest OS和app而言,它的软件是透明的,内核感觉自己是ring0, APP感觉自己是ring3,看起来没有执行“特权解除”一样,也不用再去执行前面的实际在ring1,而要假装在ring0的样子。

root模式之下,也分为ring0-ring3。VMM和HOST OS运行在RING0, HOST APPs运行在ring3。当guest OS退出(VMExit)的时候,会进入root;VMM调度guest OS运行的时候,会进入guest OS(VMEntry)。

显然,non-root模式之下的ring 0,不具备root模式下ring0同样的特权。所以root模式下的ring0是fully privileged ring 0,而non-root模式下的ring0是less privileged ring 0。一些non-root下的异常、I/O访问、指令和特定寄存器的访问,将引发从non-root到root的切换事件。比如在non-root下执行INVD — Invalidate Internal Caches指令,就会引发VMExit事件。
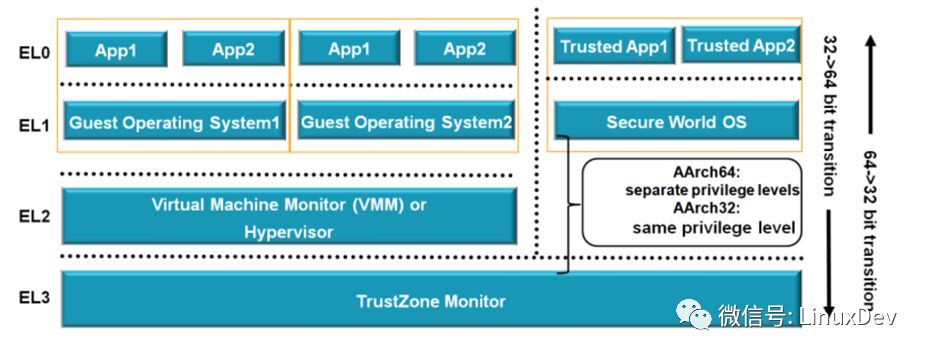
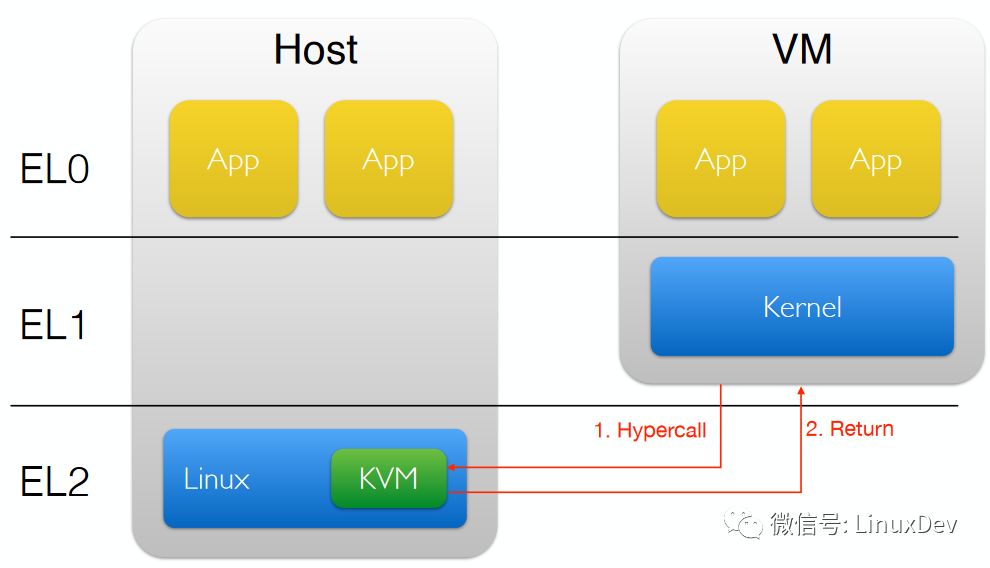
而ARM处理器也引入了类似的技术,在ARM的非安全模式之下,分为EL0这个level跑guest APP,EL1这个level跑GUEST OS,而EL2这个level跑VMM,完成各个guest OS的切换。
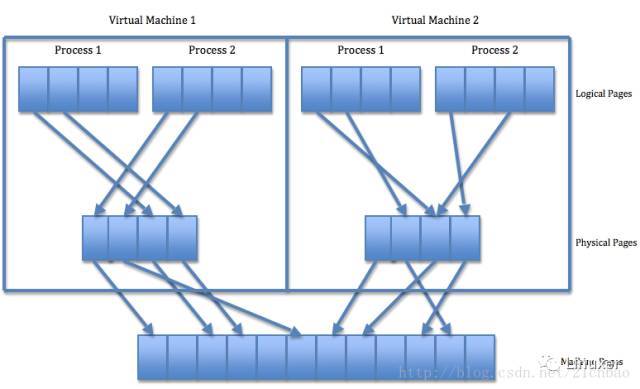
除了CPU以外,内存也是一个大问题,主机OS在跑的时候,它通过CPU的MMU完成虚拟地址到物理地址的转化。对于主机而言,它看到的物理内存是整个内存条。但是对于主机上面运行的虚拟机里面的guest OS而言,它显然不能直接看到物理的内存条。因为虚拟化的核心是把物理的东西逻辑化。所以苍老师看到的物理地址,在她的眼里依然是连续的,但是它显然不能是内存条最终真正的物理地址。现代CPU一般通过提供第2级转换来完成,一级是guest OS里面虚拟地址(VA)到guest OS的物理地址(PA),另外一级是guest OS里面的物理地址到真实内存条的地址(MA)。第2级的PA->MA的转化由VMM来维护。对guest OS里面运行的app而言,VA是连续的,实际上PA是非连续;对于guest OS里面运行的kernel而言,PA是连续的,实际上MA是非连续的。总之,不在乎是否真的连续,只在乎你觉得是连续的就行!前面我已经反复强调,虚拟化本质上是一种幻觉。在没有内存虚拟化支持的时代,VMM一般是通过给guest OS的进程再维护一个guest OS虚拟地址到最终机器物理地址的影子页表来完成地址转换的。
CPU、内存以外,接下来的大问题就是I/O外设的一系列模拟。大家玩过VMware、Virtualbox的话,都知道我们可以在guest OS里面加假硬盘、假光驱、假网卡。
这些假的东西怎么造呢?需要进行硬件的行为模拟。比如虚拟机guest OS里面有一个网卡X,它有如下寄存器序列来发包:
write(reg1, 0xFF)
write(reg2, 0xF0)
write(reg3, 0x1)
为了模拟这个网卡,我们也需要捕获上述的IO操作并进行模拟,由于所有的IO操作都会引发异常,最终陷入VMM,而VMM可以借由host OS之上运行的一个应用进行行为级模拟并最终调用Host OS的系统调用来完成最后的操作。在VMware workstation中,这一步骤就由VMdriver、VMM和VMApp来协同完成。
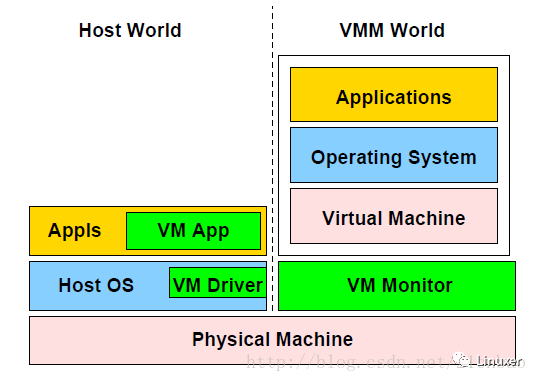
一个典型的guest里面的网络发包流程如下,显然VMM上下文给了VMDriver,之后VMApp获得I/O请求,VMApp弄清楚情况后,最终通过syscall调主机的服务把包通过主机的网卡发出去:
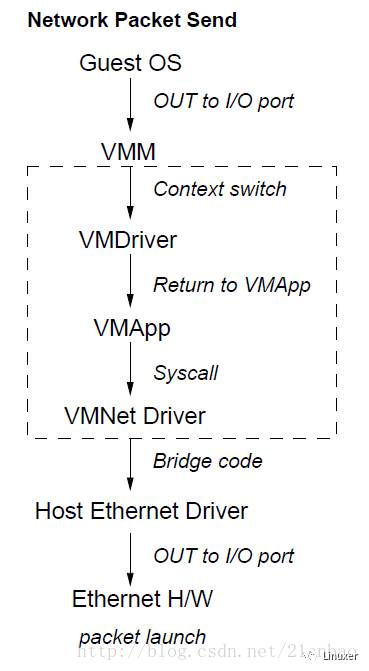
相似的,KVM 在 IO 虚拟化方面,就是使用 QEMU 这个应用软件的方式来模拟 IO 设备。
KVM是个什么鬼?
KVM(Kernel-based Virtual Machine)最初是由一个以色列的创业公司Qumranet开发的,KVM的开发人员并没有选择从底层开始新写一个Hypervisor,而是选择了基于Linux kernel,通过加载新的模块从而使linux Kernel本身变成一个Hypervisor。从Linux kernel 2.6.20开始就包含在Linux内核代码之中,可以重用Linux kernel的生态链和现有基础设施。
KVM运行于带硬件虚拟化支持的处理器,所以我们假定硬件里面的CPU虚拟化扩展、内存虚拟化扩展等都是存在的。
KVM架构中涉及到3个重要组件:
Guest:客户机系统,运行在虚拟的CPU(vCPU)、内存、虚拟的IO设备(Console、网卡、I/O 设备驱动等)。
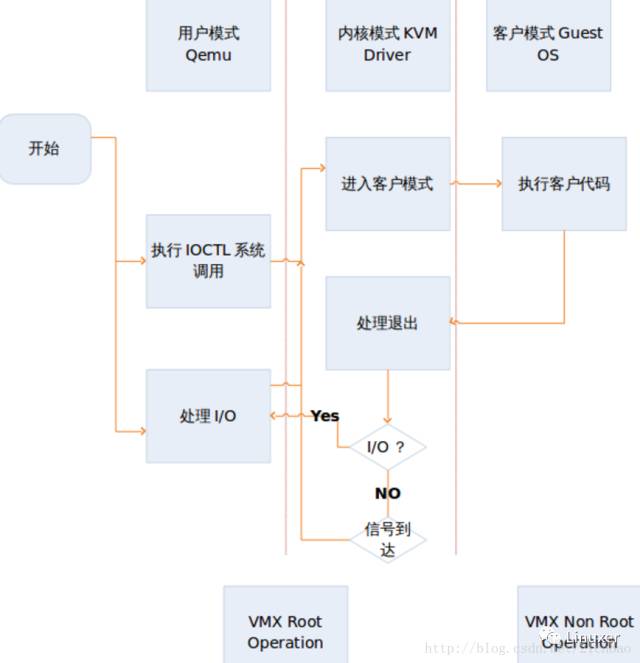
KVM:运行在Linux内核空间,成为内核模块,提供CPU 和内存的虚级化,以及客户机的 I/O 拦截。Guest 的 I/O 被KVM 拦截后,交给 QEMU 处理。KVM驱动给用户空间的QEMU提供了/dev/kvm字符设备。
QEMU:修改过的为 KVM虚拟机使用的 QEMU 代码(称为qemu-kvm),运行在用户空间,除了提供硬件 I/O 设备的模拟,还通过对/dev/kvm设备执行IOCTL来和 KVM 交互执行创建虚拟机、vCPU等对guest的控制操作。
如果要把VMware Workstation与KVM进行一个对比的话,VMdriver、VMM有点类似KVM内核模块,而VMApp有点类似QEMU。
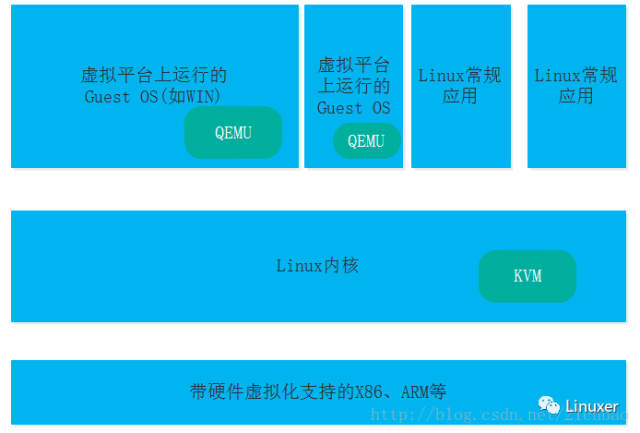
QEMU提供了guest管理的功能、I/O转换的功能。

在ARM处理器上,KVM内核组件的运行情况如下图:
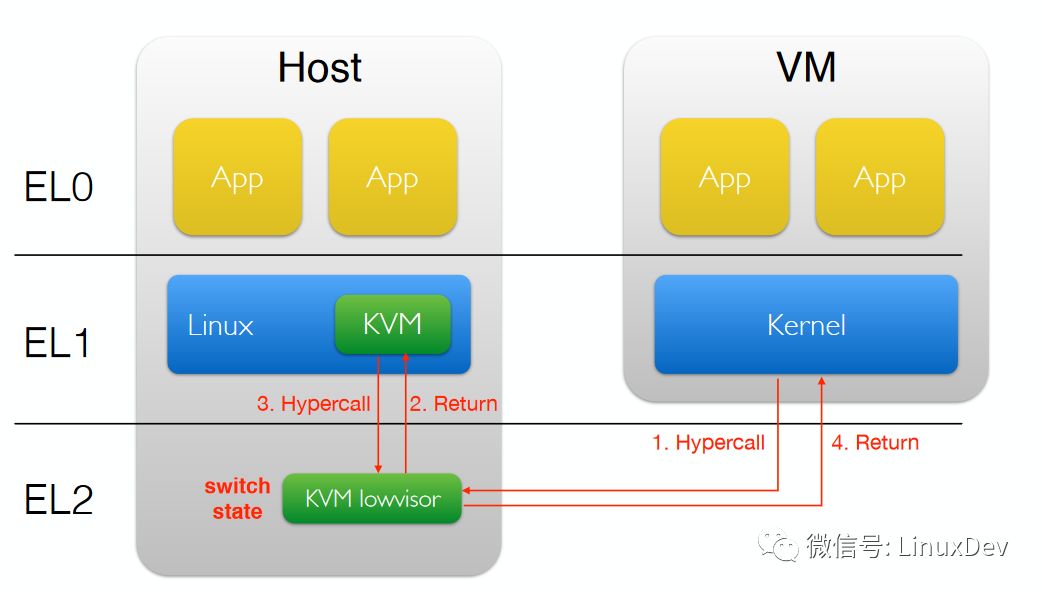
而ARM V8.1 VHE支持后,则可以变成:
QEMU通过ioctl发出KVM_CREATE_VM、KVM_CREATE_VCPU等这种虚拟机、vCPU的创建指令,让guest投入运行。之后QEMU执行KVM_RUN这样的IOCTL,如果这个IOCTL返回,意味着VMexit。qemu根据返回的情况,确定是否是guest OS发生IO的动作,如果是,则进行IO模拟以及执行主机的系统调用来完成IO动作,伪代码类似:
open(“/dev/kvm”)
ioctl(KVM_CREATE_VM)
ioctl(KVM_CREATE_VCPU)
…
for (;;) {
exit _reason = ioctl(KVM_RUN)
switch (exit_reason) {
case KVM_EXIT_IO: /* … */
case KVM_EXIT_HLT: /* … */
}
}
Guest OS对设备寄存器的读写的地址、size和数据都可以传递给QEMU里面的设备驱动,QEMU再进行行为级模拟即可,比如Guest OS想读addr位置的一个寄存器:
static int xche_ioport_read(struct kvm_io_device *this, gpa_t addr, int len, void *data)
{
/根据不同的地址执行不同的操作/
switch (addr) {
case:
break;
…
}
/*将数据拷贝到读取的数据地址/
memcpy(data, (char *)&ret, len);
return 0;
}
第一次的运行
我们把KVM以及一些相关的管理工具都安装了:
sudo apt-get install qemu-kvm qemu-system libvirt-bin bridge-utils virt-manager
然后跑一个最小的Linux- Tinycore。从http://tinycorelinux.net/downloads.html下载这个最小Linux,或者直接在Ubuntu中
wgethttp://tinycorelinux.net/7.x/x86/release/TinyCore-current.iso
运行之:
qemu-system-x86_64 -smp 2 –enable-kvm –cdrom /mnt/hgfs/Downloads/TinyCore-current.iso
这样我们会发现Tinycore Linux跑起来了:
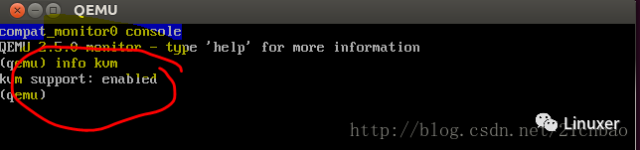
在模拟的qemu窗口中按下ctrl+alt 2,运行info kvm,发现KVM已经启动:
这个时候我们会在host OS里面看到一个qemu的进程:
baohua@ubuntu:~$ ps -ef | grep qemu
baohua 101655 42512 14 10:34 pts/3 0005 qemu-system-x86_64 -smp 2 –enable-kvm –cdrom /mnt/hgfs/Downloads/TinyCore-current.iso
由此可见,每个虚拟机在主机里面就是一个普通的Linux进程。
工具和易用性的解决
用qemu-system-x86_64 -smp 2 –enable-kvm –cdrom /mnt/hgfs/Downloads/TinyCore-current.iso这样的原始命令来运行KVM毕竟有些naive,我们需要一套强大的工具来方便KVM的部署。
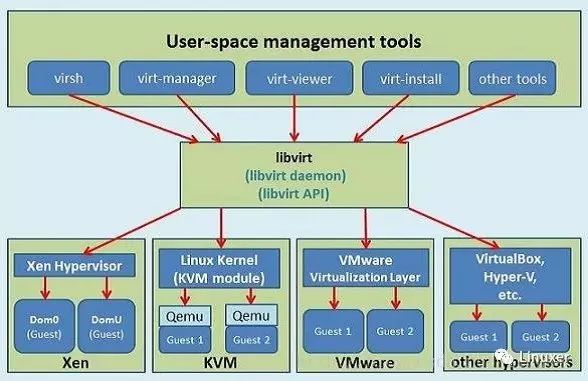
这个时候,我们就不得不提libvirt,libvirt是一套免费、开源的支持Linux下主流虚拟化工具的C函数库。其旨在为包括Xen、KVM、Virtualbox、VMware等在内的各种虚拟化工具提供一套方便、可靠的编程接口。所以libvirt可以认为是管理工具和具体虚拟机之间的一个纽带。
Libvirtd是一个daemon进程,virsh、virt-manager等工具呼叫libvirtd,而Libvirtd则调用qemu-kvm操作虚拟机。
前面的Tinycore Linux,我们同样可以在virt-manager里面进行创建、启动和停止。一路如下:

创建好后,启动Tinycore:
我们用virsh工具来观察一下这个虚拟机:
baohua@ubuntu:~$ virsh list –all
Id Name State
3 linux running
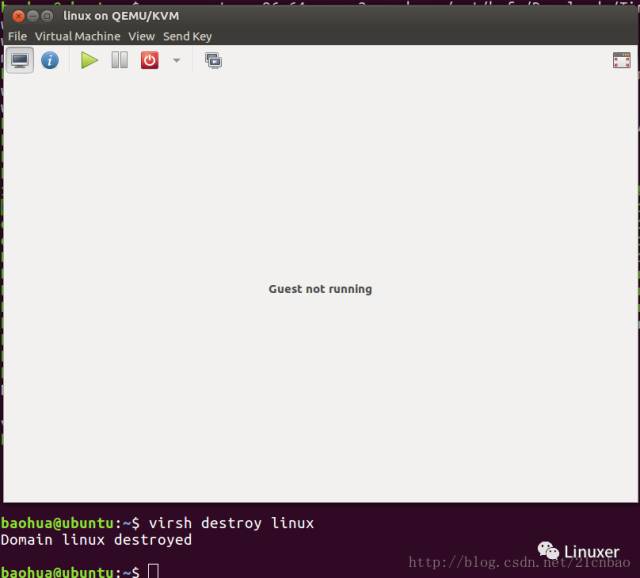
我们现在强行用”virsh destroy linux”这个命令销毁这个虚拟机:
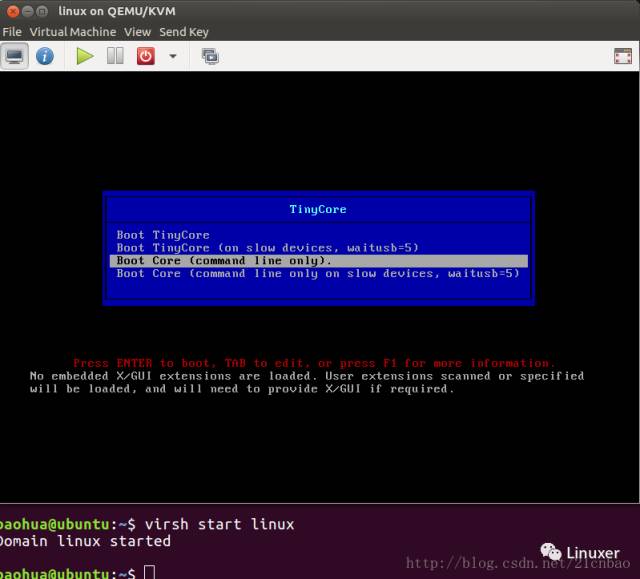
用virsh start再次启动它:
少年不管,流光如箭,因循不觉韶光换。至如今,始惜月满、花满、酒满。扁舟欲解垂杨岸,尚同欢宴。日斜歌阕将分散。倚兰桡,望水远、天远、人远。
想念那个《仙剑奇侠传98柔情》的时代,虚拟化启蒙的年代。
原文标题:KVM最初的2小时——KVM从入门到放弃
文章出处:【微信公众号:Linuxer】欢迎添加关注!文章转载请注明出处。
-
VMware
+关注
关注
1文章
299浏览量
21825 -
KVM
+关注
关注
0文章
188浏览量
12993
原文标题:KVM最初的2小时——KVM从入门到放弃
文章出处:【微信号:LinuxDev,微信公众号:Linux阅码场】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
DLP9500UV是如何控制每个像素实现256个灰度等级的?
不是!让高速先生给个过孔优化方案就那么难吗?
用ADS1299-FE评估版测试时,在测试的时候VREFP是-2.45,并不是设计所说的4.5v,为什么?
LMP90100将寄存器配置为通道扫描模式3的时候,CHO-CH3并不是逐次扫描的,为什么?
在FPGA接收ADC的DCLKP和DCLKM引脚,DCLK信号会出现规律性持续为0,在有DCLK信号时波形并不是恒定的,为什么?
ADS1299将CLKSEL拉为高电平,CONFIG1中的CLK_EN位设置为1,示波器上显示的频率并不是2.048MHz,为什么?
工业相机的帧率是不是越高越好

KVM显示器的使用方法
kvm切换器鼠标键盘怎么设置
kvm切换器怎么实现键盘热键切换
INA333输出为一纹波电压,并不是平滑的电压,为什么?
逆变器交流能耗少吗,不是那么高






 工商网监
工商网监
评论