 一文解读文件系统的作用性(一)index块设计
一文解读文件系统的作用性(一)index块设计
距我将全套盗墓笔记成功保存在8MB空间里已经过去了19天58分钟32秒,我渐渐发觉更高、更快、更强的绝不限于奥运精神,也充分体现了人类贪婪的本质,无尽的需求催生出这光怪陆离的大千世界。
就在今天下午,我得到一个通知,要么继续使用连续的存储空间,但是只能有4MB,要么去使用不连续的存储空间,总量可以仍然是8MB,那一刻,我的内心反而是平静的,因为我知道,这就是现实,一个不够优秀的系统是无法满足各种刁钻的需求的,并且我并不想丢掉一半的盗墓笔记,所以我必须使用不连续的存储空间,一个不算坏的消息是,就算是不连续,但是每块最小也有2048字节,并且连续的存储空间是2048字节对齐的,还有什么好说的,撸起袖子加油干。
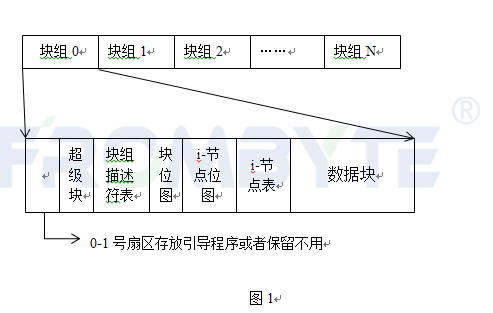
当时我的脑海中,浮现出了星空的图像,天顶中每颗闪烁的星代表的就是一段文字,我要怎么将它们串在一起呢?我想,首先要解决的是识别问题,即眼前的这颗星属于哪本书?是的,我需要星的索引信息,每条索引信息对应着一段可存储的空间,记录空间在硬盘中的偏移,长度,内容是属于哪本书,对应内容在书内的偏移,这样通过索引信息就可以在硬盘中找到存储着的盗墓笔记的片段了,于是有了如下的设计,
book_name用来存储书名,hd_ofs存储这段存储空间在硬盘中的偏移,file_ofs存储这段存储空间存储的内容在书中的偏移,chunk_len存储这段存储空间的长度,看起来是能工作的,那么这样的设计够不够好呢,答案显然是需要拿出工匠精神再来打磨一下了。
book_name,这里看起来很糟糕,如果书名很长则无法存储完整,如果书名很短则浪费了存储空间,这里真的需要存储一个书名吗?按照我的需求,盗墓笔记全套是8本书,那么第一本书,我这里记录1即可,依次则是2,3,4,...,我只需要数字就可以进行区分,于是新的设计出现了
但是,新的问题又出现了,我能够通过一个个的index对象找到数据块,但是我该如何找到这些index对象呢?由于每个index对象占用12字节,那么将index搓堆存在一个只存储index的数据块内,那么一个块能存170个index,就像下面这样
很好,现在有了一个index块,那么170个index最多只能映射(170 * 2048)字节(340KB)的内容,可我要存储的盗墓笔记不止这么点内容,所以还需要更多的index块
很好,现在有了更多的index块,我能通过index找到想要看的内容,但是index块也是不连续的,我要如何找到index块在哪里呢?其实,我对之前每个数据块填充170个index对象已经感觉难受了,因为170个index对象只使用了2040字节,这样一个数据块就有8字节的浪费,如果这8字节用来存储另一个index块在硬盘中的偏移位置,那么index块之间就能串联在一起,而我要做的就是找到那个入口
经过了两顿烧烤的谈判,我终于赢得了硬盘第1024个数据块的永久使用权,于是第1024数据块就成为了串起整部盗墓笔记的那个入口
-
硬盘
+关注
关注
3文章
1315浏览量
57413 -
文件系统
+关注
关注
0文章
287浏览量
19936 -
存储空间
+关注
关注
0文章
55浏览量
10709
发布评论请先 登录
相关推荐
防止根文件系统破坏,OverlayRootfs 让你的设备更安全

华纳云:VFS在提升文件系统性能方面的具体实践
服务器数据恢复——Ext4文件系统umount失败的数据恢复案例
虚拟化数据恢复—UFS2文件系统数据恢复案例
服务器数据恢复—raid5阵列+reiserfs文件系统数据恢复案例
服务器数据恢复—EXT3文件系统下误删除数据的恢复案例
Linux根文件系统的挂载过程
小型文件系统如何选择?FatFs和LittleFs优缺点比较

想提高开发效率,不要忘记文件系统
如何修改buildroot和debian文件系统
linux--sysfs文件系统






 工商网监
工商网监
评论