 分析四种自动化的机器学习工具包,更好地建立网络模型
分析四种自动化的机器学习工具包,更好地建立网络模型
AutoML 是当前深度学习领域的热门话题。只需要很少的工作,AutoML 就能通过快速有效的方式,为你的 ML 任务构建好网络模型,并实现高准确率。简单有效!数据预处理、特征工程、特征提取和特征选择等任务皆可通过 AutoML 自动构建。
自动机器学习(Automated Machine Learning, AutoML)是一个新兴的领域,在这个领域中,建立机器学习模型来建模数据的过程是自动化的。AutoML 使得建模更容易,并且每个人都更容易掌握。
在本文中,作者详细介绍了四种自动化的 ML 工具包,分别是 auto-sklearn、TPOT、HyperOpt 以及 AutoKeras。如果你对 AutoML 感兴趣,这四个 Python 库是最好的选择。作者还在文章结尾文章对这四个工具包进行了比较。
auto-sklearn
auto-sklearn 是一个自动机器学习工具包,它与标准 sklearn 接口无缝集成,因此社区中很多人都很熟悉该工具。通过使用最近的一些方法,比如贝叶斯优化,该库被用来导航模型的可能空间,并学习推理特定配置是否能很好地完成给定任务。
该库由 Matthias Feurer 等人提出,技术细节请查阅论文《Efficient and Robust Machine Learning》。Feurer 在这篇论文中写道:
我们提出了一个新的、基于 scikit-learn 的鲁棒 AutoML 系统,其中使用 15 个分类器、14 种特征预处理方法和 4 种数据预处理方法,生成了一个具有 110 个超参数的结构化假设空间。
auto-sklearn 可能最适合刚接触 AutoML 的用户。除了发现数据集的数据准备和模型选择之外,该库还可以从在类似数据集上表现良好的模型中学习。表现最好的模型聚集在一个集合中。

图源:《Efficient and Robust Automated Machine Learning》
在高效实现方面,auto-sklearn 需要的用户交互最少。使用 pip install auto-sklearn 即可安装库。
该库可以使用的两个主要类是 AutoSklearnClassifier 和 AutoSklearnRegressor,它们分别用来做分类和回归任务。两者具有相同的用户指定参数,其中最重要的是时间约束和集合大小。
更多 AutoSklearn 相关文档请查阅:https://automl.github.io/auto-sklearn/master/。
TPOT
TPOT 是另一种基于 Python 的自动机器学习开发工具,该工具更关注数据准备、建模算法和模型超参数。它通过一种基于进化树的结,即自动设计和优化机器学习 pipelie 的树表示工作流优化(Tree-based Pipeline Optimization Tool, TPOT),从而实现特征选择、预处理和构建的自动化。
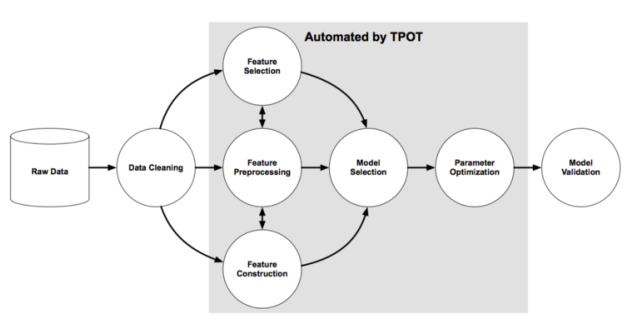
图源:《Evaluation of a Tree-based Pipeline Optimization Tool for Automating Data Science》 。
程序或 pipeline 用树表示。遗传编程(Genetic Program, GP)选择并演化某些程序,以最大化每个自动化机器学习管道的最终结果。
正如 Pedro Domingos 所说,「数据量大的愚蠢算法胜过数据有限的聪明算法」。事实就是这样:TPOT 可以生成复杂的数据预处理 pipeline。
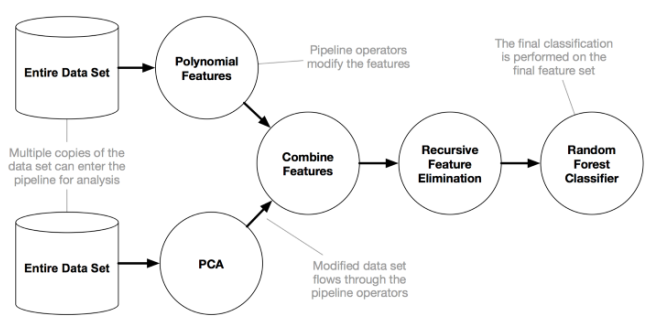
潜在的 pipelie(图源:TPOT 文档)。
TPOT pipeline 优化器可能需要几个小时才能产生很好的结果,就像很多 AutoML 算法一样(除非数据集很小)。用户可以在 Kaggle commits 或 Google Colab 中运行这些耗时的程序。
也许 TPOT 最好的特性是它将模型导出为 Python 代码文件,后续可以使用它。具体文档和教程示例参见以下两个链接:
TPOT 文档地址:https://epistasislab.github.io/tpot/。
TPOT 的教程示例地址:https://epistasislab.github.io/tpot/examples/
HyperOpt
HyperOpt 是一个用于贝叶斯优化的 Python 库,由 James Bergstra 开发。该库专为大规模优化具有数百个参数的模型而设计,显式地用于优化机器学习 pipeline,并可选择在多个核心和机器上扩展优化过程。
但是,HyperOpt 很难直接使用,因为它非常具有技术性,需要仔细指定优化程序和参数。相反,作者建议使用 HyperOpt-sklearn,这是一个融合了 sklearn 库的 HyperOpt 包装器。
具体来说,HyperOpt 虽然支持预处理,但非常关注进入特定模型的几十个超参数。就一次 HyperOpt sklearn 搜索的结果来说,它生成了一个没有预处理的梯度提升分类器:
如何构建 HyperOpt-sklearn 模型可以查看源文档。它比 auto-sklearn 复杂得多,也比 TPOT 复杂一点。但是如果超参数很重要的话,它可能是值得的。
文档地址:http://hyperopt.github.io/hyperopt-sklearn/
AutoKeras
与标准机器学习库相比,神经网络和深度学习功能更强大,因此更难实现自动化。AutoKeras 库有哪些功效呢?具体如下:
通过 AutoKeras,神经框架搜索算法可以找到最佳架构,如单个网络层中的神经元数量、层数量、要合并的层、以及滤波器大小或 Dropout 中丢失神经元百分比等特定于层的参数。一旦搜索完成,用户可以将其作为普通的 TF/Keras 模型使用;
通过 AutoKeras,用户可以构建一个包含嵌入和空间缩减等复杂元素的模型,这些元素对于学习深度学习过程中的人来说是不太容易访问的;
当使用 AutoKeras 创建模型时,向量化或清除文本数据等许多预处理操作都能完成并进行优化;
初始化和训练一次搜索需要两行代码。AutoKeras 拥有一个类似于 keras 的界面,所以它并不难记忆和使用。
AutoKeras 支持文本、图像和结构化数据,为初学者和寻求更多参与技术知识的人提供界面。AutoKeras 使用进化神经网络架构搜索方法来减轻研究人员的繁重和模棱两可的工作。
尽管 AutoKeras 的运行需要很长时间,但用户可以指定参数来控制运行时间、探索模型的数量以及搜索空间大小等。
AutoKeras 的相关内容参阅以下两个链接:
文档地址:https://autokeras.com/
教程地址:https://towardsdatascience.com/automl-creating-top-performing-neural-networks-without-defining-architecture-c7d3b08cddc
四个库各有特色,应该选哪个?
用户可以根据自己的需求选择合适的 Python 库,作者给出了以下几个建议:
如果你的首要任务是获取一个干净、简单的界面和相对快速的结果,选择 auto-sklearn。另外:该库与 sklearn 自然集成,可以使用常用的模型和方法,能很好地控制时间;
如果你的首要任务是实现高准确率,并且不需要考虑长时间的训练,则使用 TPOT。额外收获:为最佳模型输出 Python 代码;
如果你的首要任务是实现高准确率,依然不需要考虑长时间的训练,也可选择使用 HyperOpt-sklearn。该库强调模型的超参数优化,是否富有成效取决于数据集和算法;
如果你需要神经网络(警告:不要高估它们的能力),就使用 AutoKeras,尤其是以文本或图像形式出现时。训练确实需要很长时间,但有很多措施可以控制时间和搜索空间大小。
责编AJX
-
自动化
+关注
关注
29文章
5657浏览量
79822 -
模型
+关注
关注
1文章
3378浏览量
49334 -
机器学习
+关注
关注
66文章
8455浏览量
133186
发布评论请先 登录
相关推荐
基于EasyGo Vs工具包和Nl veristand软件进行的永磁同步电机实时仿真





 工商网监
工商网监
评论