 NLP 2019 Highlights 给NLP从业者的一个参考
NLP 2019 Highlights 给NLP从业者的一个参考
自然语言处理专家elvis在medium博客上发表了关于NLP在2019年的亮点总结。对于自然语言处理(NLP)领域而言,2019年是令人印象深刻的一年。在这篇博客文章中,我想重点介绍一些我在2019年遇到的与机器学习和NLP相关的最重要的故事。我将主要关注NLP,但我还将重点介绍一些与AI相关的有趣故事。标题没有特别的顺序。故事可能包括论文,工程工作,年度报告,教育资源的发布等。
论文刊物
ML / NLP创造力与社会
ML / NLP工具和数据集
文章和博客文章
人工智能伦理
ML / NLP教育
Google AI引入了ALBERT,它是BERT 的精简版本,用于自监督学习上下文语言表示。主要改进是减少冗余并更有效地分配模型的容量。该方法提高了12个NLP任务的最新性能。
Zhenzhong Lan, Mingda Chen, Sebastian Goodman, Kevin Gimpel, Piyush Sharma, Radu Soricut:ALBERT: ALiteBERTforSelf-supervised LearningofLanguageRepresentations.ICLR 2020.
Jacob Devlin, Ming-Wei Chang, Kenton Lee, Kristina Toutanova:BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. NAACL-HLT (1) 2019: 4171-4186
arxiv.org/abs/1810.0480

机器在比赛中的表现(类似sat的阅读理解)。随机猜测的基线得分为25.0。最高分是95.0分。
今年早些时候,NVIDIA的研究人员发表了一篇颇受欢迎的论文(Coined StyleGAN)(arxiv.org/pdf/1812.0494),提出了一种从样式转换中采用的GAN替代生成器架构。这是一项后续工作(arxiv.org/pdf/1912.0495),着重于改进,例如重新设计生成器归一化过程。
Tero Karras, Samuli Laine, Timo Aila:A Style-Based Generator Architecture for Generative Adversarial Networks. CVPR 2019: 4401-4410
Tero Karras, Samuli Laine, Miika Aittala, Janne Hellsten, Jaakko Lehtinen, Timo Aila:Analyzing and Improving the Image Quality of StyleGAN. CoRR abs/1912.04958 (2019)
上排显示目标图像,下排显示合成图像
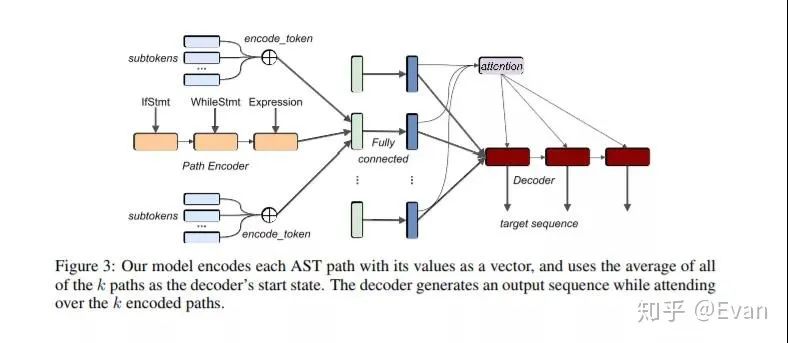
我今年最喜欢的论文之一是code2seq(code2seq.org/),它是一种从结构化代码表示中生成自然语言序列的方法。这样的研究可以让位于诸如自动代码摘要和文档之类的应用程序。
Uri Alon, Shaked Brody, Omer Levy, Eran Yahav:code2seq: Generating Sequences from Structured Representations of Code. ICLR (Poster) 2019
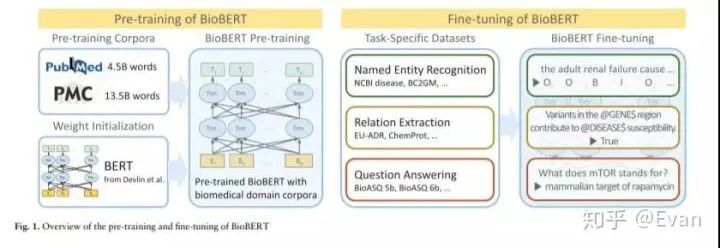
有没有想过是否有可能为生物医学文本挖掘训练生物医学语言模型?答案是BioBERT(arxiv.org/abs/1901.0874),这是一种从生物医学文献中提取重要信息的情境化方法。
Jinhyuk Lee, Wonjin Yoon, Sungdong Kim, Donghyeon Kim, Sunkyu Kim, Chan Ho So, Jaewoo Kang:BioBERT: a pre-trained biomedical language representation model for biomedical text mining. CoRR abs/1901.08746 (2019)
BERT发布后,Facebook研究人员发布了RoBERTa,该版本引入了新的优化方法来改进BERT,并在各种NLP基准上产生了最新的结果。(ai.facebook.com/blog/-t)
Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, Veselin Stoyanov:RoBERTa: A Robustly Optimized BERT Pretraining Approach. CoRR abs/1907.11692 (2019)
来自Facebook AI的研究人员最近还发布了一种基于全注意力关注层的方法,用于提高Transformer语言模型的效率。从这个研究小组更多的工作包括方法来教如何使用自然语言规划的AI系统。
Sainbayar Sukhbaatar, Edouard Grave, Piotr Bojanowski, Armand Joulin:Adaptive Attention Span in Transformers. ACL (1) 2019: 331-335

可解释性仍然是机器学习和NLP中的重要主题。集大成者!可解释人工智能(XAI)研究最新进展万字综述论文: 概念体系机遇和挑战—构建负责任的人工智能
Alejandro Barredo Arrieta, Natalia Díaz Rodríguez, Javier Del Ser, Adrien Bennetot, Siham Tabik, Alberto Barbado, Salvador García, Sergio Gil-Lopez, Daniel Molina, Richard Benjamins, Raja Chatila, Francisco Herrera:Explainable Artificial Intelligence (XAI): Concepts, Taxonomies, Opportunities and Challenges toward Responsible AI.CoRR abs/1910.10045 (2019)
Sebastian Ruder发表了有关自然语言处理的神经迁移学习的论文
(ruder.io/thesis/)。
Ruder2019Neural,Neural Transfer Learning for Natural Language Processing, Ruder, Sebastian,2019,National University of Ireland, Galway
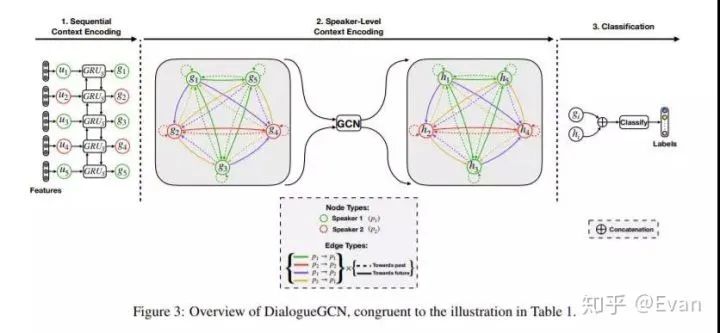
一些研究人员开发了一种在对话中进行情感识别的方法(arxiv.org/abs/1910.0498),可以为情感对话的产生铺平道路。另一个相关的工作涉及一种称为DialogueGCN(aclweb.org/anthology/D1)的GNN方法,以检测对话中的情绪。该研究论文还提供了代码实现。
Devamanyu Hazarika, Soujanya Poria, Roger Zimmermann, Rada Mihalcea:Emotion Recognition in Conversations with Transfer Learning from Generative Conversation Modeling.CoRR abs/1910.04980 (2019)
Deepanway Ghosal, Navonil Majumder, Soujanya Poria, Niyati Chhaya, Alexander F. Gelbukh:DialogueGCN: A Graph Convolutional Neural Network for Emotion Recognition in Conversation. EMNLP/IJCNLP (1) 2019: 154-164
Google AI Quantum团队在《自然》杂志上发表了一篇论文(nature.com/articles/s41),他们声称自己开发了一种量子计算机,其速度比世界上最大的超级计算机还要快。在此处详细了解他们的实验。
Arute, F., Arya, K., Babbush, R. et al.Quantum supremacy using a programmable superconducting processor.Nature 574, 505–510 (2019) doi:10.1038/s41586-019-1666-5
如前所述,神经网络体系结构需要大量改进的领域之一是可解释性。本论文(arxiv.org/abs/1908.0462)探讨了在语言模型的上下文explainability一个可靠的方法关注的局限性。
Sarah Wiegreffe, Yuval Pinter:Attention is not not Explanation. EMNLP/IJCNLP (1) 2019: 11-20
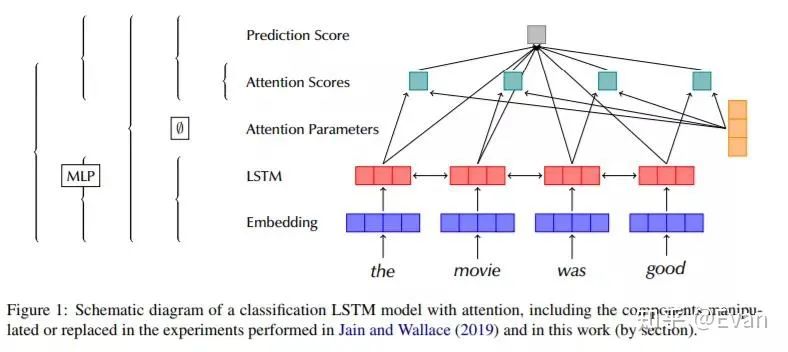
神经逻辑机器是一种神经符号网络体系结构(arxiv.org/abs/1904.1169),能够很好地在归纳学习和逻辑推理方面做得很好。该模型在诸如排序数组和查找最短路径之类的任务上表现出色。
Honghua Dong, Jiayuan Mao, Tian Lin, Chong Wang, Lihong Li, Denny Zhou:Neural Logic Machines. ICLR (Poster) 2019

神经逻辑机器架构
这是一篇将Transformer语言模型应用于提取和抽象神经类文档摘要的论文(arxiv.org/abs/1909.0318)。
Sandeep Subramanian, Raymond Li, Jonathan Pilault, Christopher J. Pal:OnExtractiveandAbstractiveNeuralDocumentSummarizationwithTransformerLanguageModels.CoRRabs/1909.03186 (2019)
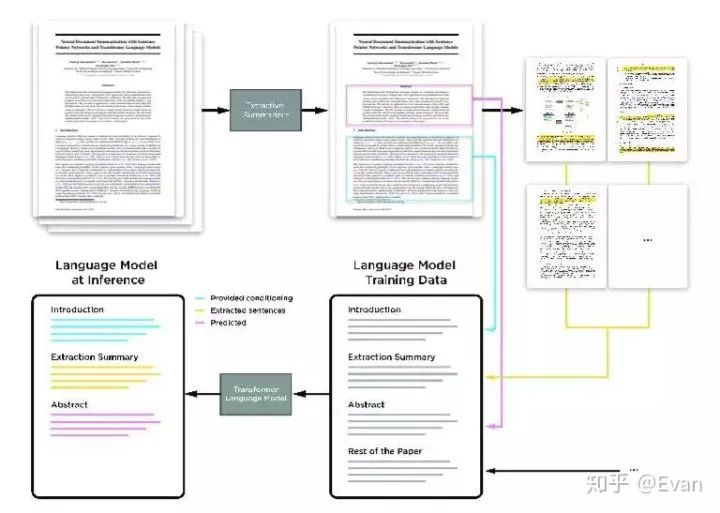
研究人员开发了一种方法,侧重于使用比较来建立和训练ML模型。这种技术不需要大量的特征标签对,而是将图像与以前看到的图像进行比较,以确定图像是否属于某个特定的标签。
blog.ml.cmu.edu/2019/03
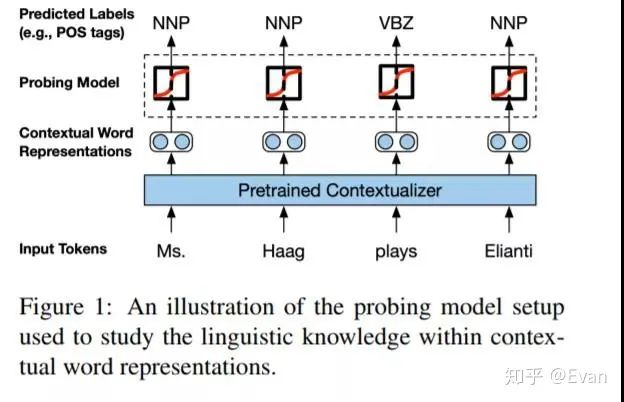
Nelson Liu等人发表了一篇论文,讨论了预先训练的语境设定者(如BERT和ELMo)获取的语言知识的类型。
arxiv.org/abs/1903.0885
Nelson F. Liu, Matt Gardner, Yonatan Belinkov, Matthew E. Peters, Noah A. Smith:Linguistic Knowledge and Transferability of Contextual Representations. NAACL-HLT (1) 2019: 1073-1094
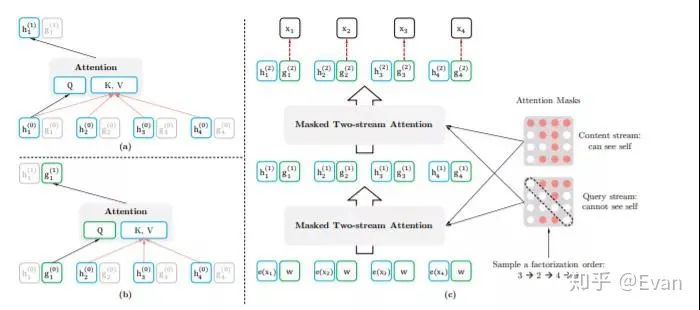
XLNet是NLP的一种前训练方法,它在20个任务上都比BERT有改进。我写了一个总结,这伟大的工作在这里。
arxiv.org/abs/1906.0823
Zhilin Yang, Zihang Dai, Yiming Yang, Jaime G. Carbonell, Ruslan Salakhutdinov, Quoc V. Le:XLNet: Generalized Autoregressive Pretraining for Language Understanding. CoRR abs/1906.08237 (2019)
这项来自DeepMind的工作报告了一项广泛的实证调查的结果,该调查旨在评估应用于各种任务的语言理解模型。这种广泛的分析对于更好地理解语言模型所捕获的内容以提高它们的效率是很重要的。
arxiv.org/abs/1901.1137
Dani Yogatama, Cyprien de Masson d'Autume, Jerome Connor, Tomás Kociský, Mike Chrzanowski, Lingpeng Kong, Angeliki Lazaridou, Wang Ling, Lei Yu, Chris Dyer, Phil Blunsom:Learning and Evaluating General Linguistic Intelligence. CoRR abs/1901.11373 (2019)
VisualBERT是一个简单而健壮的框架,用于建模视觉和语言任务,包括VQA和Flickr30K等。这种方法利用了一组Transformer层,并结合了self-attention来对齐文本中的元素和图像中的区域。
arxiv.org/abs/1908.0355
Liunian Harold Li, Mark Yatskar, Da Yin, Cho-Jui Hsieh, Kai-Wei Chang:VisualBERT: A Simple and Performant Baseline for Vision and Language. CoRR abs/1908.03557 (2019)
这项工作提供了一个详细的分析比较NLP转移学习方法和指导NLP的从业者。
arxiv.org/abs/1903.0598
Matthew E. Peters, Sebastian Ruder, Noah A. Smith:To Tune or Not to Tune? Adapting Pretrained Representations to Diverse Tasks.RepL4NLP@ACL 2019: 7-14
Alex Wang和Kyunghyun提出了BERT的实现,能够产生高质量、流畅的表示。
arxiv.org/abs/1902.0409
Facebook的研究人员发表了XLM的代码(PyTorch实现),这是一个跨语言模型的预培训模型。
github.com/facebookrese
本文全面分析了强化学习算法在神经机器翻译中的应用。
cl.uni-heidelberg.de/st
这篇发表在JAIR上的调查论文对跨语言单词嵌入模型的培训、评估和使用进行了全面的概述。
jair.org/index.php/jair
Gradient发表了一篇优秀的文章,详细阐述了强化学习目前的局限性,并提供了一条潜在的分级强化学习的前进道路。一些人发布了一套优秀的教程来开始强化学习。
thegradient.pub/the-pro
这篇简要介绍了上下文词表示。
arxiv.org/abs/1902.0600
责任编辑:xj
原文标题:【前沿】28篇标志性论文见证「自然语言处理NLP」2019->2020年度亮点进展
文章出处:【微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
-
自然语言处理
+关注
关注
1文章
618浏览量
13556 -
nlp
+关注
关注
1文章
488浏览量
22034
原文标题:【前沿】28篇标志性论文见证「自然语言处理NLP」2019->2020年度亮点进展
文章出处:【微信号:zenRRan,微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
大数据从业者必知必会的Hive SQL调优技巧
nlp逻辑层次模型的特点
nlp神经语言和NLP自然语言的区别和联系
nlp自然语言处理基本概念及关键技术
nlp自然语言处理框架有哪些
nlp自然语言处理的主要任务及技术方法
nlp自然语言处理模型怎么做
nlp自然语言处理模型有哪些
nlp自然语言处理的应用有哪些
深度学习与nlp的区别在哪
NLP技术在机器人中的应用
NLP技术在人工智能领域的重要性
什么是自然语言处理 (NLP)
NLP领域的语言偏置问题分析






 工商网监
工商网监
评论