 情感机器人小冰的外部结构
情感机器人小冰的外部结构

在大学时代参加过一次微软技术大会,没记错的是在2015年吧,当时演讲者(原谅我不记得名字)在台上介绍了两款机器人,所负责日常事务的秘书小娜(Cortana)和具有情感沟通能力的小冰(XiaoIce),前者在现在看来更像是任务型的代表,而小冰,则更像是一个有血有肉的人,在回答中能更明显地透露出人的气息,这在当时已经是神级别的产品了。
19年微软的4位大佬桌子Arxiv上对微软小冰的整体架构进行了详尽的介绍,我们来看一下:论文标题:The design and implement of XiaoIce, an empathetic social chatbot。
按事先说明,这篇文章没有啥复杂的模型,而是把小冰的外部结构讲的很清楚,可以说是智能机器人整个领域一个非常前沿的介绍,大家可以在这里面抽取自己所需放入自己的系统里面。
懒人目录:
小冰的设计原则
小冰的架构
对话引擎
小结
小冰的设计原则
一般系统级介绍的文章,开篇intro结束后会开始讲结构了,但是这篇论文却加了一章专门讨论全文的设计原则,这里面其实有很多有参考价值的东西,我们来看看。
IQ+EQ+Personality
文章认为,一个完整的人,需要拥有完整智商情商和人格,小冰也是这样拆解实现的。
先说智商,文章将小冰的智商理解为知识和记忆的建模,图像和自然语言的理解、推理、生成和预测。这么说起来其实就非常明确了,一方面我们要有存储,一种是长期稳定的知识,另一种是短期变化的聊天记忆;另一方面就是满足基本的交流能力,这个和人的对话类似,理解对方说什么、自己反应提炼信息、产生自己的回复并且对对方的回答产生预期。
然后是情商,情商被拆解为共情能力和社交能力。顾名思义,前者是一种将心比心的能力,理解他人的能力,这里面其实涵盖了query理解、用户画像、情感检测、情绪识别、动态追踪情绪变化等多个能力,可能在细节上每个能力其实都已经有一定的研究,但组合在一起还是有一定难度的;而后者,其实体现在交流上,用户是有不同的文化、性格等的背景的,因此要具备迎合对方兴趣的能力,尽可能避免说一些敏感的话题。
最后是人格,中文叫做personality,让一个人能成为人,必须有他最鲜明的标签,有自己的性格,因为只有明确性格才能让用户有明确的预期,知道他会和你聊什么,当然这点还被做的更加差异化,不同地区、场景的小冰可能会有不同的形象以满足当地用户的需求。
抓手:对话交互次数
要衡量一个机器人好坏,对于小冰所应对的场景,文章使用了平均单次对话交互次数作为评价的抓手。文章认为这是一个非常有效、长期可靠的指标。首先对于对话机器人,更多的对话次数意味着用户愿意与他沟通,获取所需信息;第二是,虽然类似“没听懂”的这种问题可能会短期带来更高的交互次数,但是这种劣质的交互次数多以后用户自然就不愿意再和交流了,所以这个指标在长期来看也是比较有意义的;第三虽然一些技能的快速达成同样会大导致交互次数的下降,但是高效的交互同样会加强用户和机器人的纽带,在长期同样有意义。(作者在这里说了很多有关交互次数的误解,但是个人感觉这个指标还是不能只看次数,还有一些别的指标吧,只看一个指标可能会比较危险)
把社交聊天当做是分层决策
这里的分层决策其实看做是将整个对话内容决策看做两层操作:顶层是技能决策,选择合适的技能应对用户的对话,底层则考虑原始基本的话术执行回复,两者结合完成整体对话操作。
a top-level process manages the overall conversation and selects skills to handle different types of conversation modes (e.g., chatting casually, question answering, ticket booking), and a low- level process, controlled by the selected skill, chooses primitive actions (responses) to generate a conversation segment or complete a task.
小冰的架构
整体架构长这样。
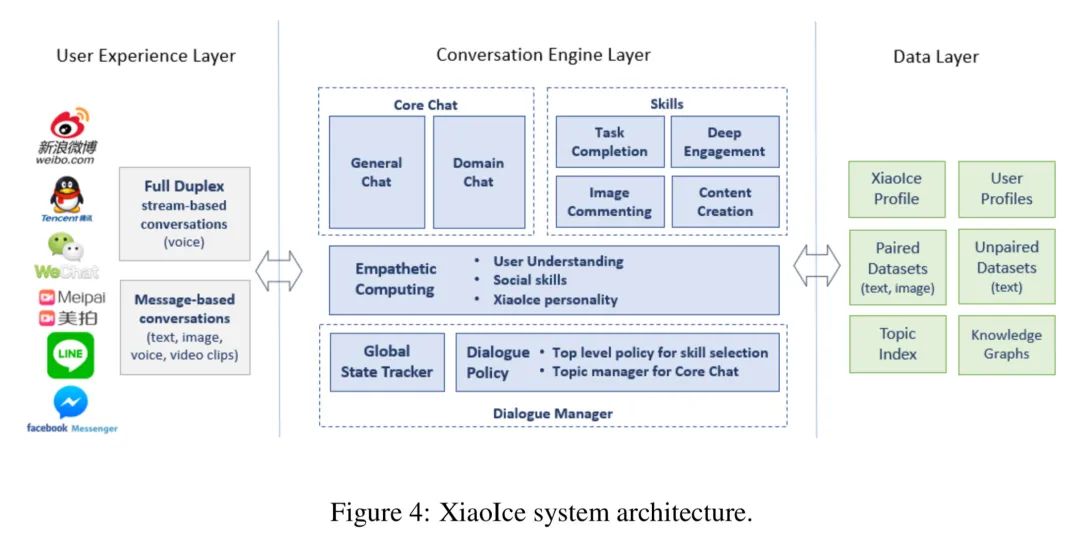
整体架构分了3层。
用户体验层。不同APP下、不同的语音输入场景下,用户都有不同的需求。这里分了两种,说人话就是把语音模式单独抽取出,满足更为实时的对话场景,另一种则涵盖文本、图像、声音、视频的模式。这里面会涉及大量的信息预处理的工作,如文本图像则是归一化、声音的去噪、判全和ASR等等。
对话引擎层。看名字就知道了,主要是用来进行对话交互的处理的,里面涵盖了大量的功能,后面会花点时间展开说,论文也是花了整个章节来讨论这块。
数据层。我们当然知道是需要存储数据的,但是存了什么与怎么用就是用户所关心。这里主要讲了有什么,有小冰画像、用户画像、成对(我们有的时候叫平行)数据、非成对数据、主题索引、知识图谱。
对话引擎
前面的章节讨论了整体架构后,这时候就把最核心的对话引擎拿出来详细品一品了。
对话管理器
Dialogue Manager,对话管理器,可以说是多轮对话最为灵魂的一个模块了,这里作者把它分为了两个子模块,分别是全局状态管理器和对话规则,这里其实把整个对话看成一个类似强化学习问题去看了,根据这个状态和对话规则,可以进行一些动作决策,即,这个动作可以是特定技能,也可以是核心对话的一些规则。
首先聊聊对话状态管理器,它主要维护的是对话过程中出现的需要记忆的信息,从而跟踪对话的状态,举个例子,在对话过程汇总达成的共识就需要被记录下来,如当前的话题、用户的爱好等,这种是短期、对话内有效的记忆。
而对话规则,则如上所示采用了分层的对话策略,高级策略管技能,低级策略管话术。而在其中,高级策略管理的技能也需要记录下来,于是有了话题管理器,它主要用于实现当前话题、管理话题切换等功能,这里有很多有意思的技术,如发现用户觉得无聊的时候主动切换话题、自身知识匮乏聊不下去时的主动切换等等。
说到这个话题的切换,其实内部是按照“召回-排序”的模式去搭建的,这个和推荐搜索非常类似,召回主要就是基于用户信息和当前对话的状态了,而排序其实用的就是多个特征合并到一个提升树上进行机器学习打分排序,文章中列举了一些排序的规则,如下:
上下文信息。
新鲜度。
用户个性化特征。
流行度。可以理解为网络的热门程度。
接受度。可以理解为在小冰场景下的用户愿意去聊的程度。
情感计算
如果说小冰情感机器人的一个代表任务,那么情感计算模块就是整个小冰最为特色的对话模块了。
实质上情感计算模块是把上面提到的状态给构造处后来,这4个东西分别为上下文状态、上下文、用户情感向量和回复的情感向量,这个东西后续就会被放入dialog policy(对话规则)中进行处理,最终表现为小冰形式的回复——一个18岁,可靠,富有同情心,深情,博学多闻,但会自欺欺人,并且幽默感极佳的妹子(心动了没?)。
整合整个计算模块主要有3个任务:上下文query理解、用户理解和用户回复生成。
首先是上下文query理解,这个相信很多做搜索推荐的人应该都会比较熟悉,这里面涉及到这几个计算任务:
命名实体识别。NLU的基本操作。
共指解析。这个在多轮对话非常常见,要把里面你的代词给解析出来。
句子完整性。这个在对话问题里面很常见,需要判断句子是否完整。
用户理解实质上就是基于上面的和,即上下文状态和上下文,处理成用户情感向量。这里面主要有5个核心工作:
话题检测,检测当前的话题状态,看用户有没有自己开新的的话题等。这个要会和话题管理器进行交互(topic manager)
识别对话意图,文中一共提到了11中对话意图,如打招呼、回复、告知等。
情感分析,分析用户情绪,是开心、伤心、愤怒等。
观点分析,分析用户对话题的观点,乐观悲观等。
在用户画像明确的前提下引入用户画像,如性别兴趣等。
在上面基础上就可以生成了,这里作者把它叫做用户共情向量生成,说到生成,说明就要把前面的信息集成起来,这样才能有一个比较综合性的结果,这里就包括了前面的对话内容、用户理解,还需要涵盖小冰的人格特征等。
核心聊天模块
核心聊天模块是处理用户输入最终完成结果回复的重要模块,它主要分为通用域聊天和垂直域聊天。顾名思义通用域就是管常见的闲聊、开放域场景的聊天,对于特定领域、任务的聊天,就交给垂直域聊天负责,一般都会是一些比较有深度知识依赖的领域,例如聊电影演员八卦之类的。这样划分的核心主要是根据下游数据库知识存储的结构有关,这个和搜索非常类似。
无论是开放域聊天还是垂直于聊天,实质上都是一种“召回-排序”模式的实现方式,召回(生成)多个可能的回答,然后排序。召回的方式文章列举了3种:
基于成对文本的数据库检索。
神经网络生成。文中提到了实质上用的是seq2seq的框架,并特地提到了GRU-RNN。
非成对样本。非成对样本的召回来自一些讲座、对话记录等,进行过一些类似非小冰风格的过滤,使用,即对话上下文状态作为索引过滤,并借助知识图谱的方式进行适当的拓展,知识图谱的构建原理源于“共现”。
然后就是排序了,排序同样使用的是提升树类的模型(可见提升树类的机器学习模型仍有很大的使用空间,不要小看)。特征作者也列举出来了:
局部语义相似度特征。保证小冰回复的内容和上一句足够接近,使用的是DSSM模型。
全局语义相似度特征。保证整个聊天会话中内容是比较紧凑的,所以会和全局上下文进行与上述相似的一次语义相似度计算。
情绪匹配度。为了保证小冰的形象及其回复足够有共情力,需要考虑情绪上的匹配度(注意这里叫匹配度,不是相似性,用户伤心你不见得要跟着她伤心,你可以尝试用快乐感染他,大家细品,这也是为什么前两个用户用的是coherence,这一个用的是matching的理由)。
检索相似性。即搜索的相似性,在特定话题下,应该有一些特定的关键词是需要被保留的,所以要有搜索上的相似性,比较突出的当然就是BM25之类的基操了。
图像评论
图像评论稍微会触及到我的知识盲区——CV,我试着讲讲吧。
首先看需求,回想下我们在微信给别人发图都是为了什么,为了聊天分享对吧,哪怕是斗图也有斗图本身的含义,因此图像评论功能有别于一般的图像识别,因为这里除了要识别图像内容,还要分析出用户的目的,然后返回针对性的内容,例如“斗图”,只有能分析出目的并且能给出针对性回复,斗图才能都得起来。
整体的操作流程和文字的处理其实类似,所以作者更多是举例子而没有深入技术细节。
对话技能
对话技能涉及到对话内容中需要完成的任务,这块和上述的图像评论和核心聊天共同组成了IQ模块,对话技能主要分为内容创建,深度参与和任务完成三种能力。
内容创建的主要目标是和人类一起完成一些创作任务,如画画、作曲等,甚至包括一些儿童读物等。这里特别提到了RNN进行创作。
深度参与旨在通过针对特定主题和设置来满足用户的特定情感和智力需求,从而提高用户的长期参与度,类似的一些百科检索、求安慰之类的其实都算是深度参与的部分,他主要涵盖两个维度,从IQ到EQ,以及组内的讨论。上面提到的百科、求安慰其实都算是这个维度里面的,这个能覆盖大量用户需求。组内讨论则倾向于和用户达成一种更加深入的关系,文中提到的“数羊”技能就是其中一个。
任务完成能力让小冰具备了和小娜类似的私人秘书能力,而且更具“人性”,完成度和贴心度都很高,类似一些相关的问答,小冰会考虑到用户的知识背景给出更加通俗的解释,例如美国人问某个国家的面积,回复可能就是“面积是XXX,相当于X个美国”。
小结
文章读完,可能深度技术上没有很明显的提升,文中但凡说了模型,其实都是一些非常经典简单的模型,收获是在于知道了这些架构上、设计思路上的东西,回头想来说实话其实模型反而不是最值钱的东西,他只是一个工具,有了好的设计,出效果的风险就会更低,哪怕是各种飞机大炮模型,其实都是建立在对用户对系统现状足够理解,根据这个现状因地制宜建立起来的,不是谁都适用,试错风险自然就高了,这也是我在本系列第一篇用这个的核心目的所在。
责任编辑:xj
原文标题:【微软小冰】多轮和情感机器人的先行者
文章出处:【微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
-
微软
+关注
关注
4文章
6760浏览量
108144 -
情感机器人
+关注
关注
1文章
6浏览量
3604
原文标题:【微软小冰】多轮和情感机器人的先行者
文章出处:【微信号:zenRRan,微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
商汤善惠烧卖购机器人小店正式落地上海
六维力传感器:当机器人拥有“真实触觉”,未来会发生什么?
荣耀机器人散热系统介绍

为什么说关节扭矩传感器是高端机器人的“触觉神经”?
D13x系列芯片在AI陪伴机器人中的创新应用

复合机器人机械结构设计与创新:智能制造的前沿技术与发展趋势

赋予机器人灵动双眸:匠芯创D13x系列芯片在AI陪伴机器人中的创新应用

探索RISC-V在机器人领域的潜力
RK3576机器人核心:三屏异显+八路摄像头,重塑机器人交互与感知
小萝卜机器人的故事
EtherCAT牵手MODBUS RS485,机器人小队焊出完美火花



评论