 KDD2020知识图谱相关论文分享
KDD2020知识图谱相关论文分享

论文专栏:KDD2020知识图谱相关论文分享
论文解读者:北邮 GAMMA Lab 博士生 闫博
题目:鲁棒的跨语言知识图谱实体对齐
会议:KDD 2020
论文地址:https://dl.acm.org/doi/pdf/10.1145/3394486.3403268
代码地址:https://github.com/scpei/REA
推荐理由:这篇论文首次提出了跨语言实体对齐中的噪音问题,并提出了一种基于迭代训练的除噪算法,从而进行鲁棒的跨语言知识图谱实体对齐。本工作对后续跨语言实体对齐的去噪研究具有重要的开创性意义。
跨语言实体对齐旨在将不同知识图谱中语义相似的实体进行关联,它是知识融合和知识图谱连接必不可少的研究问题,现有方法只在有干净标签数据的前提下,采用有监督或半监督的机器学习方法进行了研究。但是,来自人类注释的标签通常包含错误,这可能在很大程度上影响对齐的效果。因此,本文旨在探索鲁棒的实体对齐问题,提出的REA模型由两个部分组成:噪声检测和基于噪声感知的实体对齐。噪声检测是根据对抗训练原理设计的,基于噪声感知的实体对齐利用图神经网络对知识图谱进行建模。两个部分迭代进行训练,从而让模型去利用干净的实体对来进行节点的表示学习。在现实世界的几个数据集上的实验结果证明了提出的方法的有效性,并且在涉及噪声的情况下,此模型始终优于最新方法,并且在准确度方面有显著提高。
1 引言
现有方法在进行跨语言实体对齐时没有考虑噪音问题,而这些噪音可能会损害模型的效果。如图1所示,(a)中的两个不同语言的知识图谱存在实体对噪音(虚线表示的实体对1-4),(b)是理想状况下节点在特征空间中的表示,可以看出不同语言知识图谱中具有相似语义的实体在特征空间中也相近。(c)是利用含有噪音的训练数据得到的节点特征表示,由于噪音的存在,节点的表示存在了一定的偏差。我们希望跨语言实体对齐是鲁棒性的,即使训练数据中存在噪音,模型也能尽量减少噪音的消极影响,得到如图(b)中的表示。为了克服现有的跨语言实体对齐方法在处理带噪标签实体对时存在的局限性,本文探讨了如何将噪声检测与实体对齐模型结合起来,以及如何共同训练它们以对齐不同语言知识图谱中的实体。
图1噪音对跨语言实体对齐模型效果的影响示意图
问题定义
噪音检测和鲁棒性图表示学习:在一个存在噪音的场景下,代表所有的用于训练的实体对(可能包含噪音),代表中确定的干净的实体对,代表不确定是否含有噪音的实体对。鲁棒性的跨语言实体对齐模型利用给定的和,去对齐知识图谱中的剩余实体,并且能自动发现中的噪音实体对。
这个问题是不平凡的,主要存在两方面的挑战:(1)没有明显的噪音知识加以利用,即我们不知道训练数据中哪些是噪音数据,所以传统的监督学习方法无法使用,提出的模型需要以一种无监督的方式自动检测出训练数据中的噪音实体对。(2)提出一个统一的模型。此模型要既能检测出训练数据中的噪音,还能进行有效的跨语言实体对齐。
2 方法
鲁棒性的跨语言实体对齐模型(REA)包括两个部分。一是基于噪音感知的实体对齐模型,这一部分主要是利用图神经网络来对不同语言的两个知识图谱进行统一建模,学习节点的表示,训练时只使用。二是噪音检测模块,作者采用了基于对抗训练的方式,利用生成对抗网络(GAN)来检测噪音。噪音实体对生成器接受干净实体对输入,然后进行采样生成噪音实体对;噪音判别器以干净实体对和噪音实体对为输入,训练一个能判别噪音的模型,同时对输入的实体对产生一个信任分数,将信任分数大于阈值的实体对加入,用于实体对齐模块节点的表示学习。上述两个模块迭代进行训练,直到收敛。下面详细介绍这两个模块。
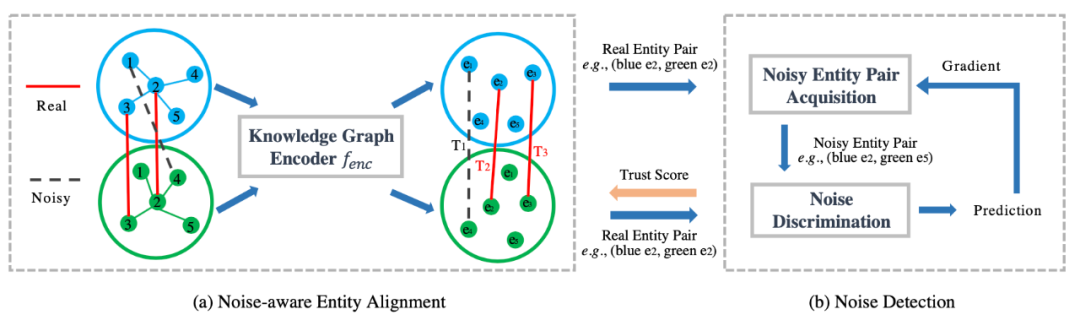
图2REA模型示意图
2.1 基于噪音感知的实体对齐模型
这一部分主要是对知识图谱节点的表示学习。对于知识图谱中任意的三元组,定义从传到的信息为:
具体为:
其中和是节点一阶邻居的个数。最终经过图的信息传播后节点的表示为:
损失函数采用基于间隔的排序损失(margin-based ranking objective):
这里代表信任分数,又噪音检测模块输出,即当实体对的信任分数超过阈值时,此实体对才被认为是正确的,才会被加入训练集。代表margin loss,是一个超参数。是一个衡量实体对相似性的函数,由能量函数定义:
负样本对由随机替换头或尾实体得到。
2.2 噪音检测模块
噪音检测模块分为噪音对生成器和噪音对判别器,由生成对抗网络实现。与传统的生成对抗网络不同的一点是,噪音对生成器不是由模型训练产生噪音对,而是由采样生成。噪音对生成器利用实体对齐模块生成的真实实体对表示作为输入,然后通过替换掉头或尾实体采样得到噪音实体对。噪音实体对的采样概率如下式所示:
其中是一个简单的两层神经网络,衡量了两个实体的语义相似性,两个实体越相似,越不容易被采样到,这是自然的,因为生成器本来就是用来生成噪音的。为了减少采样空间过大带来的计算量代价,采样只在负样本空间的一个子空间进行:
此外,由于采样过程是无法利用传统的基于梯度下降方法求参数,所以本文采用了基于强化学习的参数求解算法,具体来说:
对所有负样本的梯度求解近似为对k个采样的负样本的梯度求解,可以看作当前的状态,可以看作策略,看作是动作,代表奖励。
噪音判别器以实体对作为输入,输出实体对为真实实体对的概率:
越大,实体对越有可能为真实实体对,定义实体对的信任得分为:
信任得分为1的实体对将返回给实体对齐模型,继续训练。
2.3 算法流程
REA模型采用的是一个迭代的算法,在每次迭代中,算法依次进行三部分的参数训练。首先是利用干净的实体对进行节点的表示学习(4-7);然后对噪音实体对判别器进行训练(8-12);最后对噪音实体对生成器进行训练(13-17)。一次迭代完成后,更新中实体对的信任得分,将信任得分等于1的实体对加入。具体算法如下所示。

3 实验
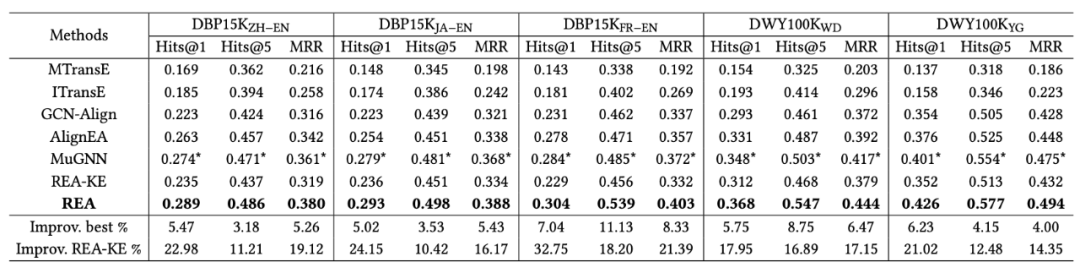
作者在两个数据集DBP15K和DWY100K包含的5个跨语言知识图谱上进行了实验。采用Hits@1,Hits@5,MRR做为评价指标。实验结果如下图所示,其中REA-KE是去掉噪音检测模块得到的结果。
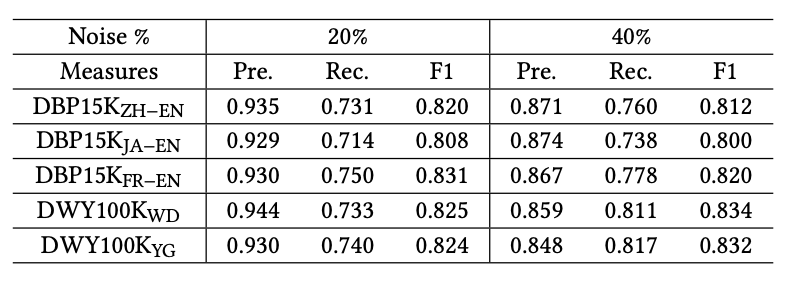
本模型中,噪音实体对判别器的检测能力至关重要,所以作者也测试了噪音判别器对噪音数据的检测能力。如下所示,噪音数据的比例为20%和40%时,判别器都有一个较好的检测噪音的效果。但是由于知识图谱的不完整性,仍有大量真实实体对被检测为噪音。
当干净的实体对数据()增加的时候,模型效果也会变好;而当噪音数据增加的时候,模型效果就会降低。而REA在有噪音的情况下表现是最好的。这也说明了噪音对跨语言实体对齐有很大的影响,REA能有效地处理噪音问题。如图3和图4所示。
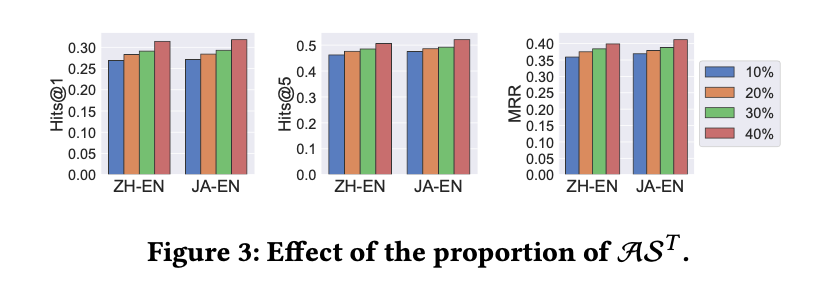
图3干净实体对的数量对实验结果的影响
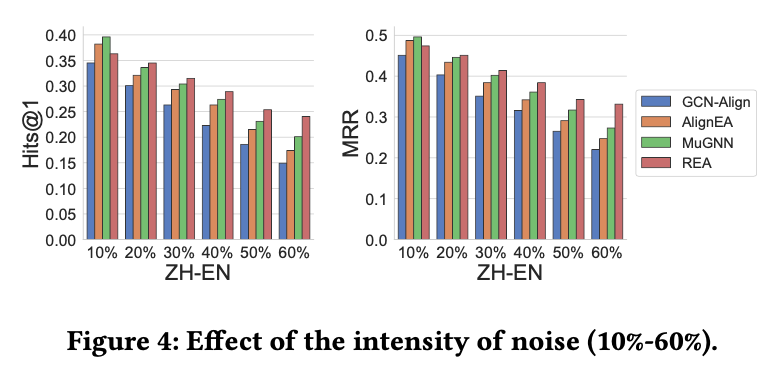
图4噪音实体对的数量对实验结果的影响
最后,作者还测试了不同类型的噪音对实验结果的影响。噪音的不同类型由它们采样时离真实实体的距离所定。图5分别测试了噪音实体离真实实体距离为10,50,100和全局的情形下模型的效果。
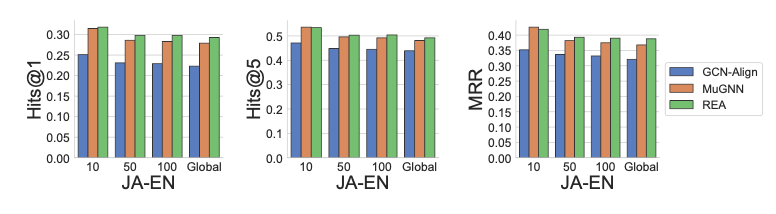
图5噪音类型对实验结果的影响
从图5可以看出,噪音离真实实体越远,即与真实实体的语义差别越大时,模型效果降低越多。当距离大于50后,模型效果几乎不再变化,这也说明了离真实实体大于一定距离时,噪音对模型的负面效果趋于稳定。而当噪音实体离真实数据越近,模型效果越好,这是显而易见的,因为这样越接近干净的标注数据。在所有的4种情况下,REA均取得了最好的效果。
4 总结
在标注跨语言实体对齐语料过程中不可避免地会引入噪音。现有方法没有考虑噪音问题,损害了实体对齐的效果。针对这一问题,本文提出了鲁棒性的跨语言实体对齐模型REA。REA通过一种迭代训练的方式,在每一轮训练过程中,通过图神经网络建模知识图谱中的实体对,得到噪声感知的实体对齐模块,然乎利用生成对抗网络来生成噪音实体对并训练一个噪音判别器,噪音判别器识别出干净的实体对加入训练集继续训练。大量的实验证明了REA在鲁棒性跨语言实体对齐任务上的有效性。
责任编辑:xj
原文标题:【KDD20】鲁棒的跨语言知识图谱实体对齐
文章出处:【微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
-
自然语言
+关注
关注
1文章
293浏览量
14036 -
知识图谱
+关注
关注
2文章
132浏览量
8366
原文标题:【KDD20】鲁棒的跨语言知识图谱实体对齐
文章出处:【微信号:zenRRan,微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
万里红入围嘶吼2026网络安全产业图谱
行业洞察篇__数字孪生IOC的“智能体”时刻:智慧城市公共服务的演进逻辑
在低温环境(-20°C)下应用 P2020 和 DDR3 时,串口没有输出,怎么解决这个问题?
鸿蒙智能体开发知识库---创建知识库
实力认证!行云创新入围《AI 中国生态图谱 2025》大模型开放平台板块

梁文锋署名DeepSeek新论文:突破GPU内存限制的技术革命
润和软件入选大模型一体机产业图谱

华为联合发布宜兴“天机镜”大模型知识图谱
Nullmax端到端轨迹规划论文入选AAAI 2026
光伏组件IV曲线测试仪:解锁光伏组件性能的“能量图谱仪”

中软国际入选中国信通院AI Agent智能体产业图谱1.0
芯片相关知识交流分享
云知声四篇论文入选自然语言处理顶会ACL 2025




评论