 基于caffe和Lasagne CNN分类器的FPGA上实现
基于caffe和Lasagne CNN分类器的FPGA上实现
近来卷积神经网络(CNN)的研究十分热门。CNN发展的一个瓶颈就是它需要非常庞大的运算量,在实时性上有一定问题。而FPGA具有灵活、可配置和适合高并行度计算的优点,十分适合部署CNN。
快速开始
环境需求PYNQ v2.4,Python 3.6.5。
需要安装caffe和Lasagne这两个计算平台。我们将使用caffe中预训练的参数并利用Lasagne来搭建网络
具体安装过程参见github项目文件中的 PYNQ案例-分类器.docx这个文档,其包含了本项目的详细操作步骤。
Overlay介绍
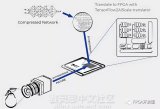
PYNQ-Classifcation是一个软件上基于caffe和Lasagne,硬件加速的CNN分类器项目,它使用python语言在PYNQ框架下进行软件编程和硬件驱动。
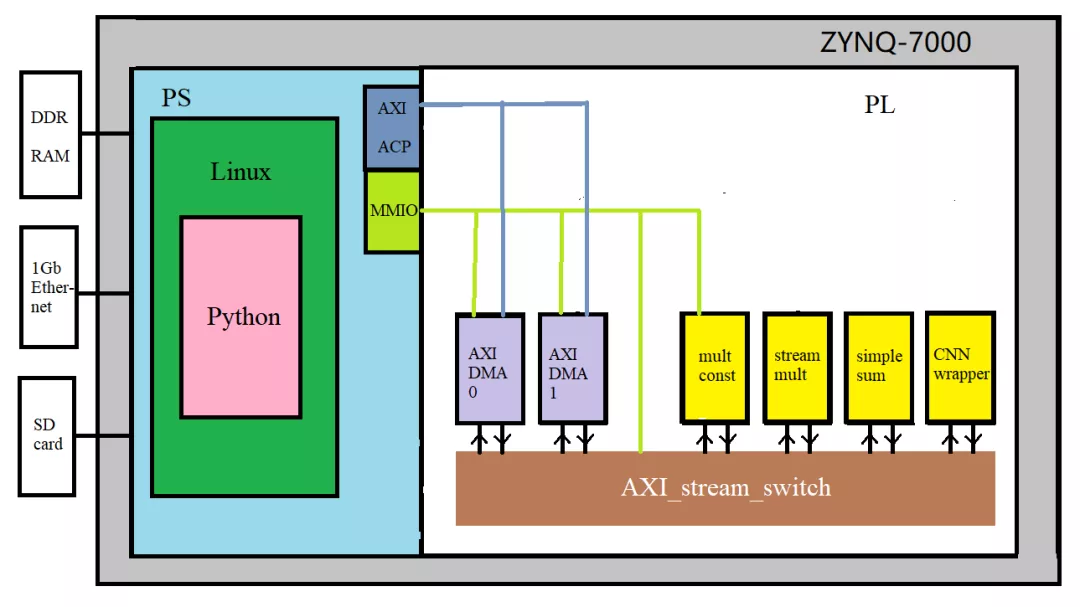
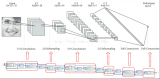
上图为工程项目示意图。通过软硬件划分,在PS端中负责Linux和通信,而PL端负责运算加速。在PYNQ中加载bit时,PL端的控制部分将以IP核形式呈现。通过Python,对IP核的参数配置来实现控制。
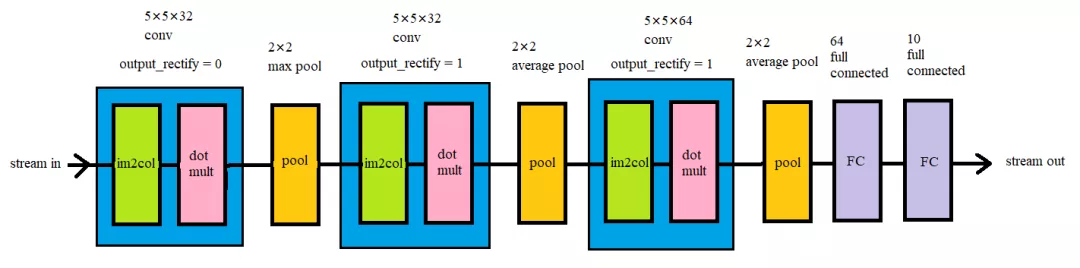
此项目中采用的CNN结构示意图(以CIFAR_10为例子),本项目中的卷积层由两个子层构成,一个是im2col子层,它的作用是将输入矩阵中的卷积窗口展开乘一维向量,另一个是点乘子层,它的作用是将im2col子层输出的向量和展开成一维的卷积核相乘加。卷积层有一个参数是output_rectify,这对应的是当前卷积层是否应用Relu非线性层,0为否,1为是。池化层(pool)有两种选项,一是最大值池化,二是平均值池化。
项目演示(CIFAR-10为例)
运行
/PYNQ-Classification/python_notebooks/Theano/CIFAR_10/Using a Caffe Pretrained Network - CIFAR10.ipynb
-- 如果想尝试Lenet5则运行
/PYNQ-Classification/python_notebooks/Theano/Lenet/Using a Caffe Pretrained Network - LeNet5.ipynb
它们的notebook类似,只不过硬件上部署的网络不一样
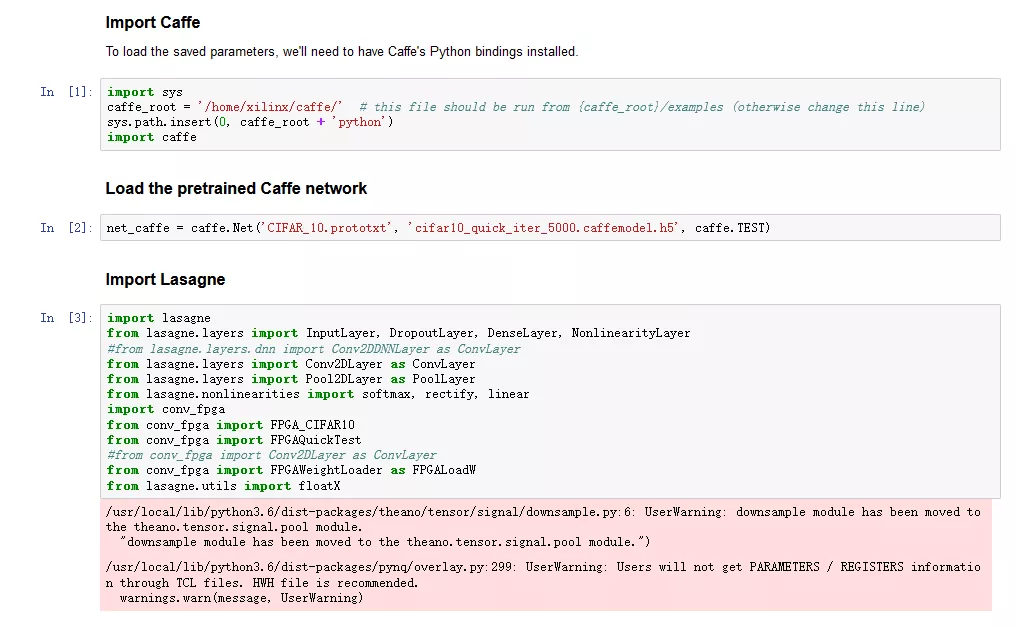
开始
将库都包含进工程,并且读取caffe中预先训练好的CIFAR_10模型。
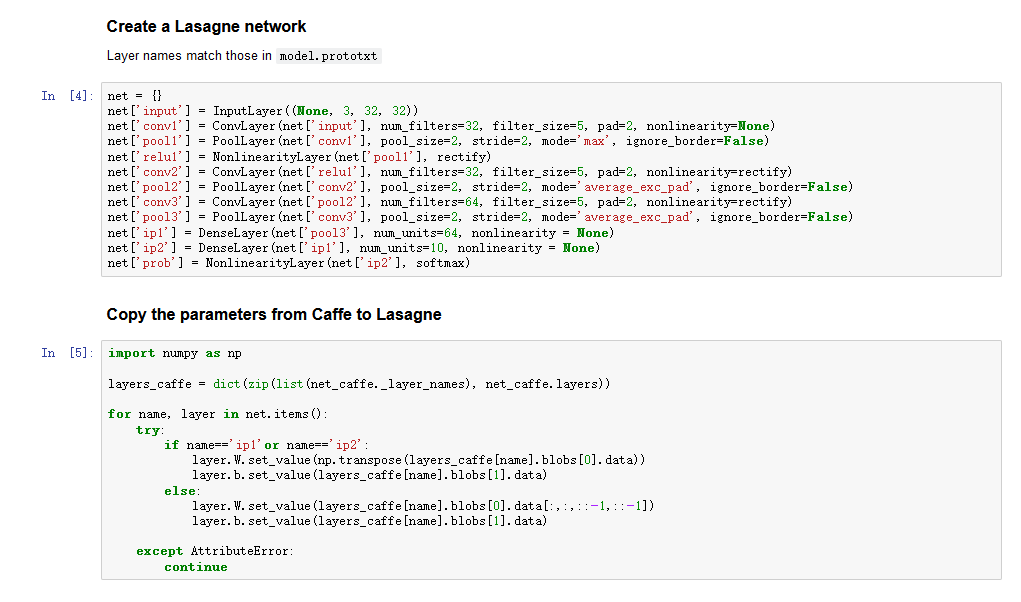
然后
建立一个Lasagne的网络结构,这个网络结构和硬件中的结构类似,硬件中去掉了第一个ReLU层。将训练好的模型参数导入到这个网络中。
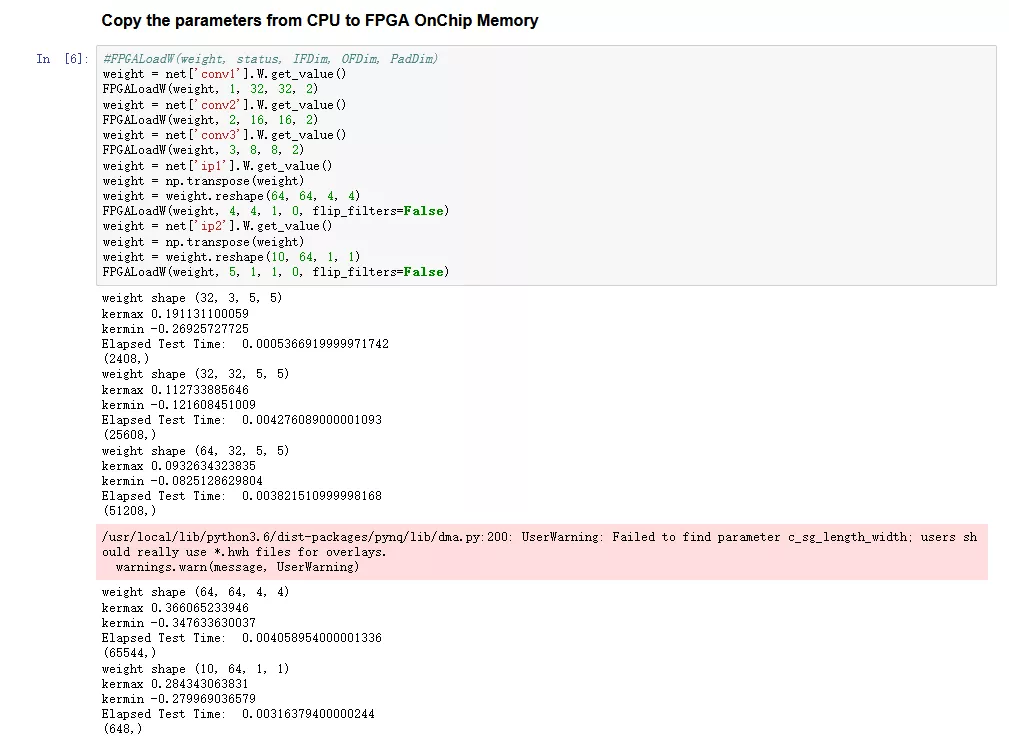
接下来
导入CIFAR_10数据集
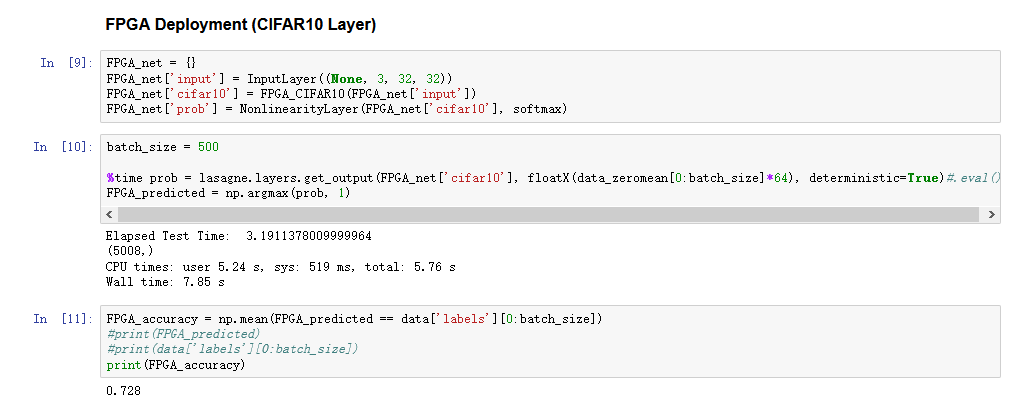
这里我们构建一张新的网络,把原来的中间层换成我们自定义的FPGA_CIFAR10层,这一层把原来的中间层全部包含了进去,并在FPGA上实现。然后输入数据集,得到结果,结果保存在FPGA_predicted中。最后显示了准确度,达到72.8%。这里也会显示一些耗时。
这里我们可以看到这个网络的部分识别结果。
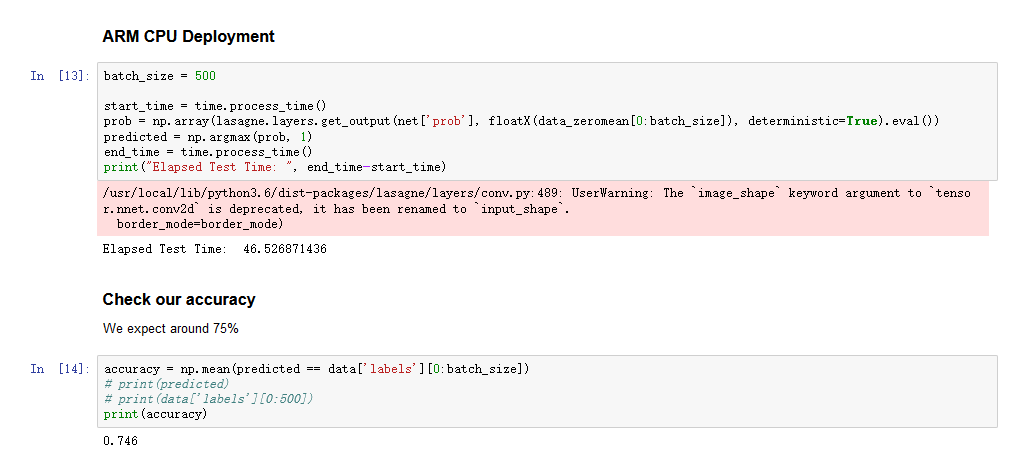
这里再用CPU运行一遍这个网络,可以看到它用时46.5秒,比使用FPGA完成卷积慢了很多。
-
FPGA
+关注
关注
1629文章
21729浏览量
602962 -
cpu
+关注
关注
68文章
10854浏览量
211568 -
卷积神经网络
+关注
关注
4文章
367浏览量
11863
发布评论请先 登录
相关推荐
TF之CNN:CNN实现mnist数据集预测
如何移植一个CNN神经网络到FPGA中?
如何将DS_CNN_S.pb转换为ds_cnn_s.tflite?
基于FPGA的通用CNN加速设计

简单快捷地用小型Xiliinx FPGA加速卷积神经网络CNN
KORTIQ公司推出了一款Xilinx FPGA的CNN加速器IP——AIScale
商汤联合提出基于FPGA的Winograd算法:改善FPGA上的CNN性能 降低算法复杂度

自己动手写CNN Inference框架之 (一) 开篇

基于FPGA的深度学习CNN加速器设计方案
为什么传统CNN在纹理分类数据集上的效果不好?






 工商网监
工商网监
评论