 深度解析FPGA时序的进位链
深度解析FPGA时序的进位链
在FPGA中我们写的最大的逻辑是什么?相信对大部分朋友来说应该是计数器,从最初板卡的测试时我们会闪烁LED,到复杂的AXI总线中产生地址或者last等信号,都会用到计数器,使用计数器那必然会用到进位链。
可能很多刚开始接触FPGA的同学没听过进位链,也就是Carry Chain,我们这里再回顾一下。FPGA的三个主要资源为:
1. 最低逻辑单元
可配置逻辑单元(CLB)
存储单元
运算单元(DSP48)
2. 一流的I / O资源
3. 布线资源
其中,CLB在FPGA中最丰富,在7系列的FPGA中,一个CLB中有两个Slice,Slice中包含4个LUT6、3个数据选择器MUX,两个独立进位链(Carry4,Ultrascale是CARRY8)和8个主轴。
首先,我们来看下Carry Chain的结构原理,其输入输出接口如下:
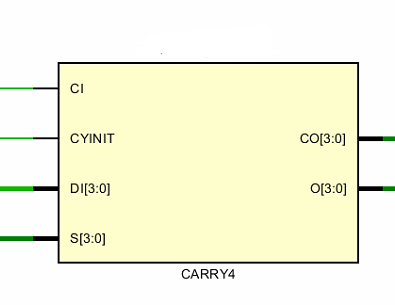
其中,
CI是上一个CARRY4的进位输出,位宽为1;
CYINT是进位的初始化值,位宽为1;
DI是数据的输入(两个加数的任意一个),位宽为4;
SI是两个加数的异或,位宽为4;
O是加法结果输出,位宽为4;
CO是进位输出,位宽为4;(为什么进位输出是4bit?后面有解释)
Carry4的内部结构如下图所示:
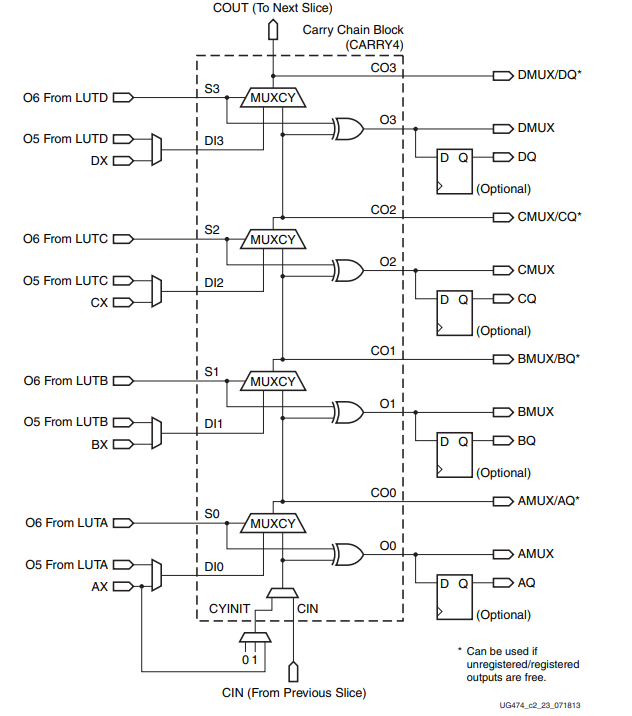
这里我们要先解释一下FPGA中利用卡里链(Carry Chain)实现加法的原理,比如两个加数分别为a = 4'b1000和b=4'b1100,其结果应该是8+12=20。
a = 4'b1000; b = 4'b1100; S = a ^ b = 4'b0100; D = b = 4'b1100; //D取a也可以 CIN = 0; //没有上一级的进位输入 CYINIT = 0; //初始值为0 // 下面为CARRY4的计算过程,具体的算法跟上图中过程一样 S0 = 0; //S的第0位 O0 = S0 ^ 0 = 0 ^ 0 = 0; CO0 = DI0 = 0; //上图中的MUXCY,S0为0时,选择1,也就是DI0,S0为1是选择2 S1 = 0; O1 = S1 ^ CO0 = 0 ^ 0 = 0; CO1 = DI1 = 0; S2 = 1; O2 = S2 ^ CO1 = 0 ^ 1 = 1; CO2 = CO1 = 0; S3 = 0; O3 = S3 ^ CO2 = 0 ^ 0 = 0; CO3 = DI3 = 1;
加法最终的输出结果为:{CO3,O3,O2,O1,O0} = 5'b10100 =20。进位输出在CARRY4的内部也使用到了,因此有4个位的进位输出CO,但输出给下一级的只是CO [3]。
再来看完下面的例子就更清晰了。Example的代码如下:
module top(
input clk,
input [7:0] din_a,
input [7:0] din_b,
output reg[7:0] dout
);
always @ ( posedge clk )
begin
dout <= din_a + din_b;
end
endmodule
综合之后的电路如下:
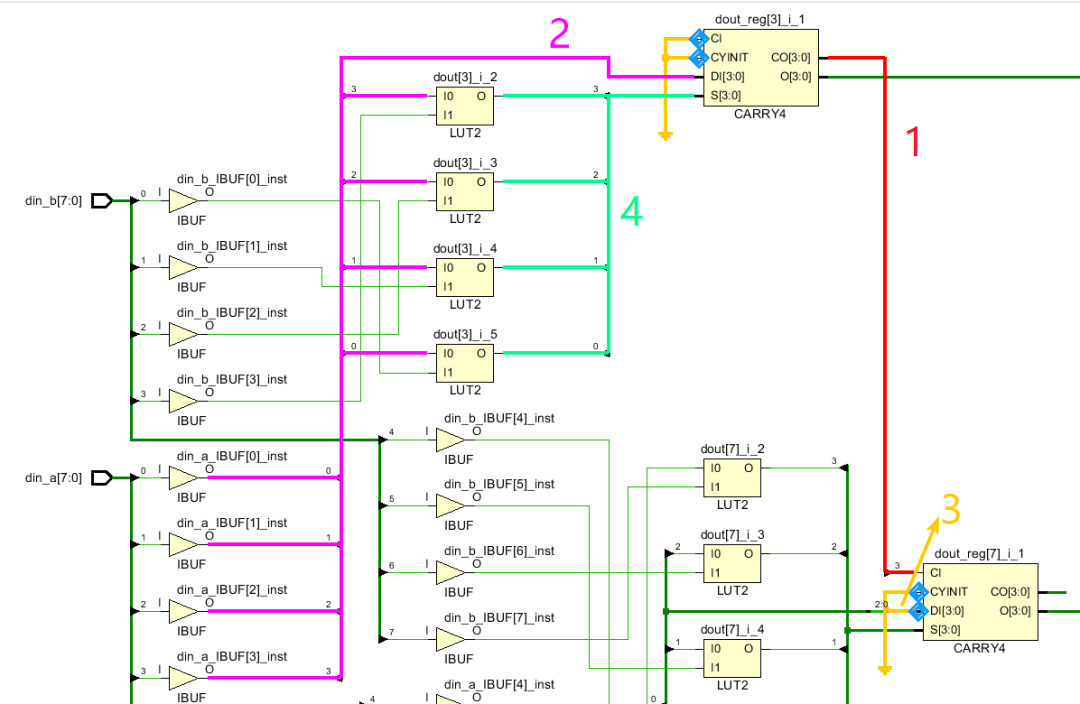
在本程序中,加数为din_a和din_b,图中
1 表示CARRY4的进位输出到下一级的进入输入;
2 表示输入的一个加数din_a(换成din_b也是可以的);
3 表示第二级输入的DI端口,因为第二级CARRY是通过第一级的进位输出进行累加,因此该接口为0;
4 表示输入两个加数的异或结果。
可以抛光,当进行两个两个bit的数据进行加法操作时,会使用两个CARRY4级联,那如果是对48位的数据进行相加,那就会用到12个的CARRY4的级联,这样(此处需要注意的是,在Vivado的设置下,如果进行的是12bit以下的数据加1'b1的操作,那么Vivado综合的结果并不会使用CARYY4,或者使用LUT来实现加法器)。
那如何解决这种问题呢?我们可以把加法操作进行拆解,比如拆解成3个16bit的计数器,那这样就会只有4个CARRY4的级联,时序情况就好了很多。
对比程序如下:
module top(
input clk,
input [47:0] din1,
input [47:0] din2,
output reg[47:0] dout1,
output [47:0] dout2
);
always @ ( posedge clk )
begin
dout1 <= din1 + 1'b1;
end
genvar i;
generate
for(i = 0;i < 3;i=i+1) begin:LOOP
wire carry_co;
reg [15:0] carry_o=0;
wire ci;
if(i==0) begin
always @ ( posedge clk )
begin
carry_o <= din2[i*16+:16] + 1'b1;
end
end //if
else begin
always @ (posedge clk) begin
if(LOOP[i-1].carry_co == 1)
carry_o <= carry_o + 1'b1;
end
end //else
assign LOOP[i].carry_co = (LOOP[i].carry_o==16'hffff)?1'b1:1'b0;
assign dout2[i*16+:16] = LOOP[i].carry_o;
end //for
endgenerate
endmodule
:综合后的schematic后可以发现,在dout2的输出中,每4个CARRY4后都会有一级的触发,这样时序就会好很多,但造成的代价是LUT会增加。
编辑:hfy
-
FPGA
+关注
关注
1629文章
21750浏览量
604102 -
计数器
+关注
关注
32文章
2256浏览量
94682
发布评论请先 登录
相关推荐
FPGA驱动AD芯片之实现与芯片通信
FPGA加速深度学习模型的案例
高速ADC与FPGA的LVDS数据接口中避免时序误差的设计考虑

FPGA做深度学习能走多远?
FPGA 高级设计:时序分析和收敛
加法进位链的手动约束
FPGA工程的时序约束实践案例





 工商网监
工商网监
评论