 基于赛灵思FPGA的广告推荐算法Wide and deep硬件加速案例
基于赛灵思FPGA的广告推荐算法Wide and deep硬件加速案例
作者:雪湖科技 梅碧峰
在这篇文章里你可以了解到广告推荐算法Wide and deep模型的相关知识和搭建方法,还能了解到模型优化和评估的方式。我还为你准备了将模型部署到赛灵思 FPGA上做硬件加速的方法,希望对你有帮助。阅读这篇文章你可能需要20分钟的时间。
早上起床打开音乐APP,会有今日歌单为你推荐一些歌曲。地铁上闲来无事,刷一刷抖音等短视频,让枯燥的时光变得有趣。睡前打开购物APP,看一看今天是不是有新品上架。不知不觉大家已经习惯了这些APP,不知道大家有没有留意到为什么这些APP这么懂你,知道你喜欢听什么音乐,喜欢看什么类型的短视频,喜欢什么样的商品?
这些APP都会有类似“猜你喜欢”这类栏目。在使用时会惊叹“它怎么知道我喜欢这个?!”,当然,也会有“我怎么可能喜欢这个?”的吐槽。其实这些推送都是由机器学习搭建的推荐系统预测的结果。今天就介绍一下推荐系统中的重要成员CTR预估模型,下面先让大家对CTR预估模型有一个初步认识。
两个名词
CTR(Click-Through-Rate)点击率:它是在一定时间内点击量/曝光量*100%,意味着投放了A条广告有 A*CTR 条被点击了。
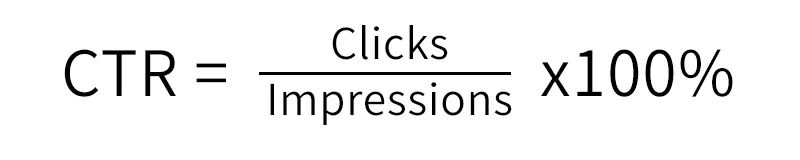
ECPM(earning cost per mille):每1000次曝光带来收入。ECPM=1000*CTR*单条广告点击价格。
举个“栗”子
广告A:点击率4%,每个曝光1元钱,广告B:点击率1%,每个曝光5元钱。假如你要投放1000条广告,你会选择广告A,还是广告B?
直观上来看,广告A的点击率高,当然选择投放广告A。
那么:ECPM=1000*CTR*点击出价
ECPM(A)=1000*4%*1=40
ECPM(B)=1000*1%*5=50
但是从ECPM指标来看的话广告B带来的收益会更高,这就是广告竞拍的关键计算规则。
我们可以看到CTR是为广告排序用的,对于计算ECPM来说,只有CTR是未知的,只要准确得出CTR值就可以了。因此CTR预估也是广告竞拍系统的关键指标。广告系统的CTR预估在具体的数值上比推荐系统要求更高,比如推荐系统可能只需要知道A的CTR比B大就可以排序了,而广告由于不是直接用CTR进行排序,还加上了出价,因此广告系统不仅要知道A的CTR比B大,而且还需要知道A的CTR比B的CTR大多少。
再举个“栗”子
如果广告A:点击率是5%,广告B:点击率也是5%,点击价格也相同,该选择广告A还是广告B?
点击率相同,点击价格也相同 ,得出ECPM也相同,该怎么选择投放广告A还是B呢?
此时就可以根据广告属性做针对性推荐,针对不同的人群,做合适的推荐。例如:广告A是包,广告B是游戏,可做针对性推荐。即:针对女人这一群体投放广告A、针对男人这一群体投放广告B,这样则会提高总广告收益率。
CTR模型是怎么得出结果的呢?
我们可以根据经验判断决定广告点击率的属性:广告行业、用户年龄、用户性别等。由此可分为三类属性:
User:年龄、性别、收入、兴趣、工作等。
Others:时间、投放位置、投放频率、当前热点等。
这些决定属性在CTR预估模型中都叫做特征,而CTR预估模型中有一重要过程“特征工程”,将能影响点击率的特征找到并进行处理,比如把特征变成0和1的二值化、把连续的特征离散化、把特征平滑化、向量化。这样CTR模型相当于是无数特征(x)的一个函数,CTR=f(x1,x2,x3,x4,x5...),输入历史数据训练,不断调整参数(超参数),模型根据输入的数据不断更新参数(权重),最终到迭代很多次,参数(权重)几乎不变化。当输入新的数据,就会预测该数据的结果,也就是点击率了。
那么有没有很好奇如何搭建并训练出一个好的CTR预估模型呢?
No.1、模型迭代过程
推荐系统这一场景常用的两大分类:
CF-Based(协同过滤)、Content-Based(基于内容的推荐)
协同过滤(collaborative filtering)就是指基于用户的推荐,用户A和B比较相似,那么A喜欢的B也可能喜欢。
基于内容推荐是指物品item1和item2比较相似,那么喜欢item1的用户多半也喜欢item2。
对于接下来的模型无论是传统的机器学习还是结合现今火热的深度学习模型都会针对场景需求构建特征建模。
LR(Logistics Regression)==> MLR(Mixed Logistic Regression)==> LR+GBDT(Gradient Boost Decision Tree)==> LR+DNN(Deep Neural Networks)即Wide&Deep==>
1.1、LR
所谓推荐也就离不开Rank这一问题,如何讲不同的特征组通过一个表达式计算出分数的高低并排序是推荐的核心问题。通过线性回归的方式找到一组满足这一规律的参数,公式如下:
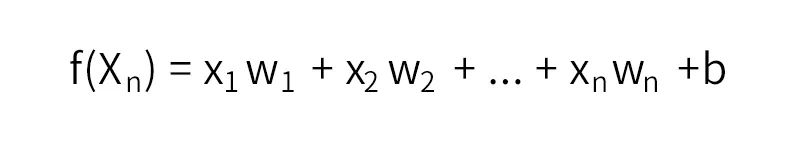
再通过sigmoid函数将输出映射到(0,1)之间,得出二分类概率值。
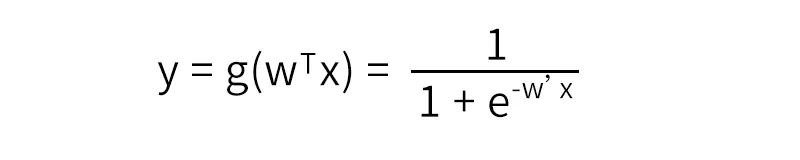
LR模型一直是CTR预估的benchmark模型,原理通俗易懂、可解释性强。但是当特征与特征之间、特征与目标之间存在非线性关系时,模型效果就会大打折扣。因此模型十分依赖人们根据经验提取、构建特征。另外,LR模型不能处理组合特征,例如:年龄和性别的组合,不同年龄段不同性别对目标的偏爱程度会不相同,但是模型无法自动挖掘这一隐含信息,依赖人工根据经验组合特征。这也直接使得它表达能力受限,基本上只能处理线性可分或近似线性可分的问题。
为了让线性模型能够学习到原始特征与拟合目标之间的非线性关系,通常需要对原始特征做一些非线性转换。常用的转换方法包括:连续特征离散化、向量化、特征之间的交叉等。稍后会介绍为什么这样处理。
1.2、MLR
它相当于聚类+LR的形式。将X聚成m类,之后把每个类单独训练一个LR。MLR相较于LR有更好的非线性表达能力,是LR的一种拓展。
我们知道softmax的公式:
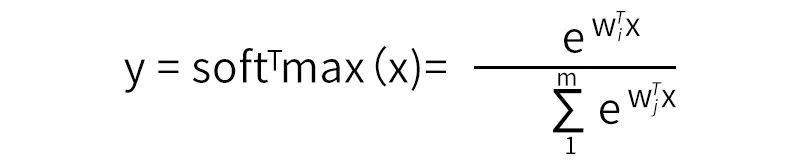
将x进行聚类,即得拓展之后的模型公式:
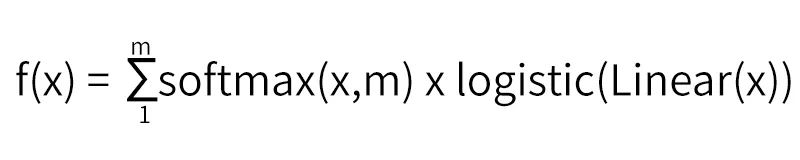
当聚类数目m=1时,退化为LR。m越大,模型的拟合能力越强,m根据具体训练数据分布来设置。
图1:MLR 模型结构
但是MLR与LR一样,同样需要人工特征工程处理,由于目标函数是非凸函数(易陷入局部最优解),需要预训练,不然可能会不收敛,得不到好的模型。
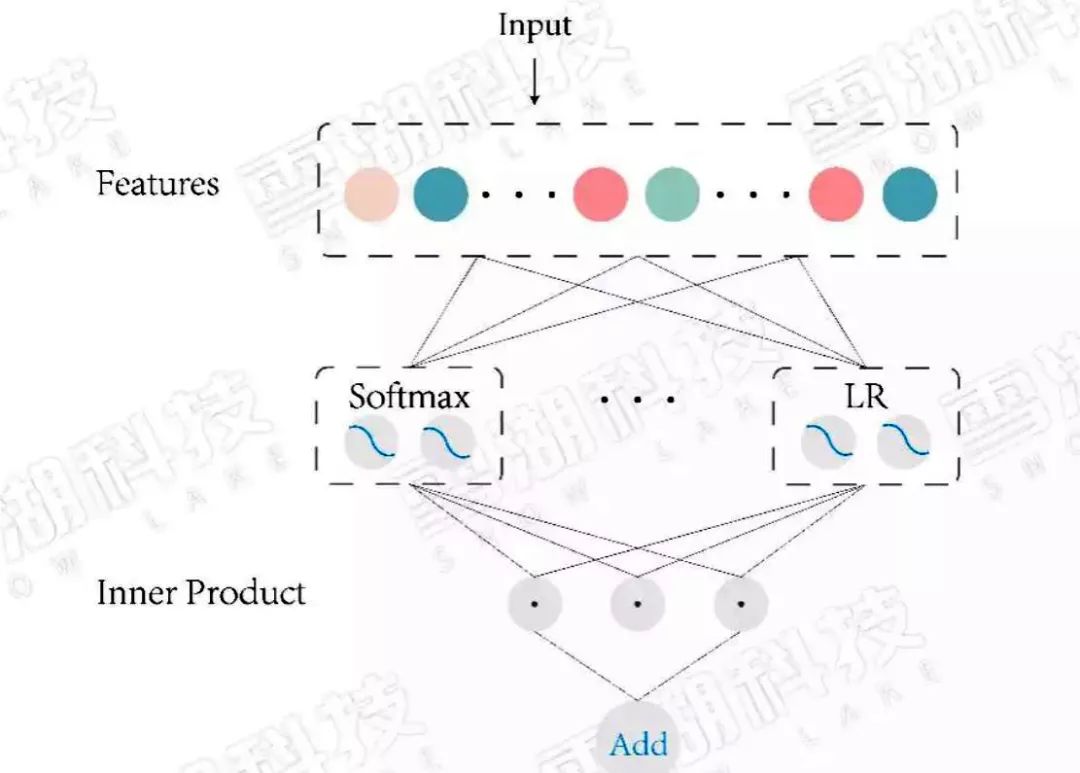
1.3、LR+GBDT
顾名思义LR模型和GBDT模型组合。GBDT可做回归与分类,这个看自己的需求。在CTR预估这一任务中要使用的是回归树而非决策树。梯度提升也就是朝着梯度下降的方向上建树,通过不断更新弱分类器,得到强分类器的过程。 每一子树都是学习之前树的结论和的残差,通过最小化 log 损失函数找到最准确的分支,直到所有叶子节点的值唯一 ,或者达到树的深度达到预设值。如果某叶子节点上的值不唯一,计算平均值作为预测值输出。
LR+GBDT:
Facebook 率先提出用GBDT模型解决LR模型的组合特征问题。特征工程分为两部分,一部分特征通过GBDT模型训练,把每颗树的叶子节点作为新特征,加入原始特征中,再用LR得到最终的模型。
GBDT模型能够学习高阶非线性特征组合,对应树的一条路径(用叶子节点来表示)。通常用GBDT模型训练连续值特征、值空间不大(value种类较少)的特征,空间很大的特征在LR模型中训练。这样就能把高阶特征进行组合,同时又能利用线性模型处理大规模稀疏特征。
图2:LR+GBDT 模型结构图
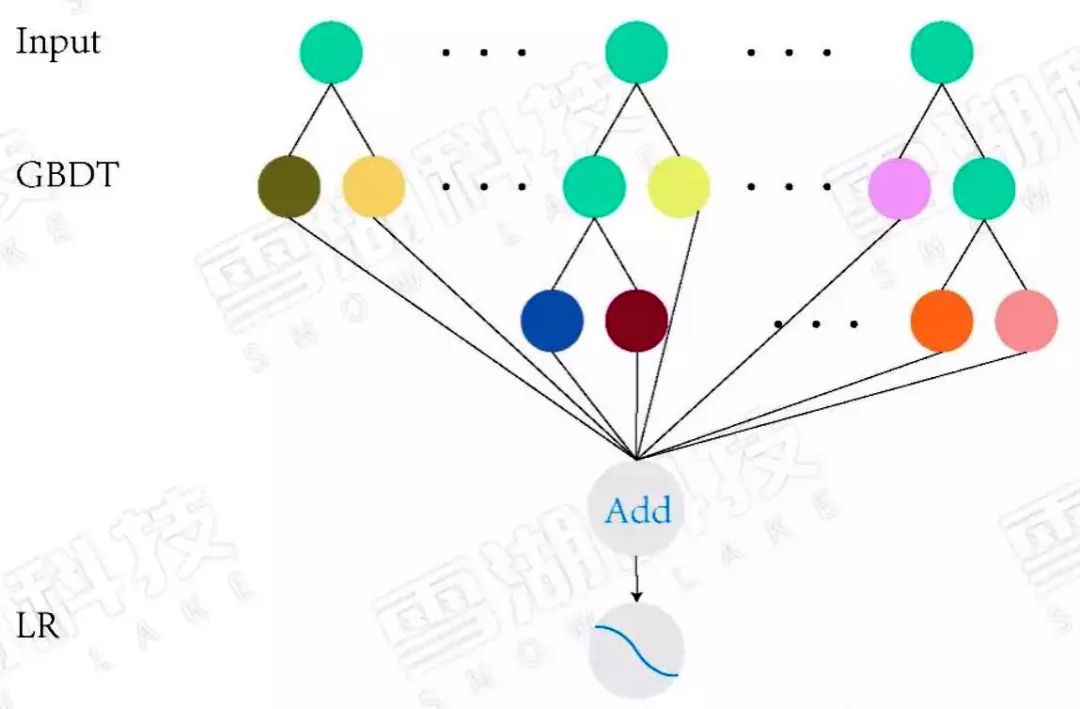
1.4、LR+DNN(Wide&Deep)
先回想一下我们学习的过程。从出生时代,不断学习历史知识,通过记忆达到见多识广的效果。然后通过历史知识泛化(generalize)到之前没见过的。但是泛化的结果不一定都准确。记忆(memorization)又可以修正泛化的规则(generalized rules),作为特殊去处理。这就是通过Memorization和Generalization的学习方式。
推荐系统需要解决两个问题:
记忆能力: 比如通过历史数据知道“喜欢吃水煮鱼”的人也“喜欢吃回锅肉”,当输入为“喜欢吃水煮鱼”,推出“喜欢吃回锅肉”。
泛化能力: 推断在历史数据中从未见过的情形,“喜欢吃水煮鱼”,“喜欢吃回锅肉”,推出喜欢吃川菜,进而推荐出其他川菜。
但是,模型普遍都存在两个问题:
a) 偏向于提取低阶或者高阶的组合特征,不能同时提取这两种类型的特征。
b) 需要专业的领域知识来做特征工程。
线性模型结合深度神经网络为什么叫做wide and deep呢?
无论是线性模型、梯度下降树、因子分解机模型,都是通过不断学习历史数据特征,来适应新的数据,预测出新数据的表现。这说明模型要具备一个基本特征记忆能力,也就是wide 部分。
但是当输入一些之前没有学习过的数据,此时模型表现却不优秀,不能根据历史数据,有机组合,推出新的正确结论。此时单单依赖记忆能力是不够的。深度学习却可以构建多层隐层通过FC(全连接)的方式挖掘到特征与特征之间的深度隐藏的信息,来提高模型的泛化能力,也就是deep部分。将这两部分的输出通过逻辑回归,得出预测类别。
图3:Wide & Deep 模型结构图
它混合了一个线性模型(Wide part)和Deep模型(Deep part)。这两部分模型需要不同的输入,而Wide part部分的输入,依旧依赖人工特征工程。本质上是线性模型(左边部分, Wide model)和DNN的融合(右边部分,Deep Model)。
对于历史数据特征保证一定的记忆能力,对于新的数据特征拥有推理泛化能力。较大地提高了预测的准确率,这也是一次大胆的尝试,在推荐系统中引入深度学习,在之后的CTR模型发展中大多也都是按照此设计思路进行的。
1.5、数据处理
CTR预估数据特点:
a) 输入中包含类别型和连续型数据。类别型数据需要one-hot(独热编码),连续型数据可以先离散化再one-hot,也可以直接保留原值。
b) 维度非常高,特征值特别多。
c) 数据非常稀疏。如:city包含各种不同的地方。
d) 特征按照Field分组。如:city、brand、category等都属于一个Field,或者将这些Field拆分为多个Fidld。
e) 正负样本不均衡。点击率一般都比较小,大量负样本存在。
如何高效的提取这些组合特征?CTR预估重点在于学习组合特征。注意,组合特征包括二阶、三阶甚至更高阶的,复杂的特征,网络不太容易学习、表达。一般做法是人工设置相关知识,进行特征工程。但是这样做会非常耗费人力,另外人工引入知识也不能做到全面。
1.6、模型搭建
以Wide and Deep为例,介绍网络的搭建。在tensorflow.estimator下有构建好的API,使用方法如下:
Wide中不断提到这样一种变换用来生成组合特征:
tf.feature_column.categorical_column_with_vocabulary_list(file)()。知道所有的不同取值,而且取值不多。可以通过list或者file的形式,列出需要训练的value。
tf.feature_column.categorical_column_with_hash_bucket(),不知道所有不同取值,或者取值多。
通过hash的方式,生成对应的hash_size个值,但是可能会出现哈希冲突的问题,一般不会产生什么影响。
tf.feature_column.numeric_column(),对number类型的数据进行直接映射。一般会对number类型feature做归一化,标准化。
tf.feature_column.bucketized_column(),分桶离散化构造为sparse特征。这种做法的优点是模型可解释高,实现快速高效,特征重要度易于分析。特征分区间之后,每个区间上目标(y)的分布可能是不同的,从而每个区间对应的新特征在模型训练结束后都能拥有独立的权重系数。特征离散化相当于把线性函数变成了分段线性函数,从而引入了非线性结构。比如不同年龄段的用户的行为模式可能是不同的,但是并不意味着年龄越大就对拟合目标(比如,点击率)的贡献越大,因此直接把年龄作为特征值训练就不合适。而把年龄分段(分桶处理)后,模型就能够学习到不同年龄段的用户的不同偏好模式。
tf.feature_column.indicator_column(),离散类型数据转换查找,将类别型数据进行one-hot,稀疏变量转换为稠密变量。
tf.feature_column.embedding_column(),(加深feature维度,将特征向量化,可使模型学到深层次信息),对于RNN中有tf.nn.embedding_lookup(),将文字信息转为向量,具体算法可以自行查一下。
离散化的其他好处还包括对数据中的噪音有更好的鲁棒性(异常值也落在一个划分区间,异常值本身的大小不会过度影响模型预测结果);离散化还使得模型更加稳定,特征值本身的微小变化(只有还落在原来的划分区间)不会引起模型预测值的变化。
tf.feature_column.crossed_column(),构建交叉类别,将两个或者两个以上的features根据hash值拼接,对hash_key(交叉类别数)取余。特征交叉是另一种常用的引入非线性性的特征工程方法。通常CTR预估涉及到用户、物品、上下文等几方面的特征,有时某个单个feature对目标判定的影响会较小,而多种类型的features组合在一起就能够对目标的判定产生较大的影响。比如user的性别和item的类别交叉就能够刻画例如“女性偏爱女装”,“男性喜欢男装”的知识。交叉类别可以把领域知识(先验知识)融入模型。
Deep部分,通过build_columns(),得到可分别得到wide 和deep部分,通过tf.estimator.DNNLinearCombinedClassifier(),可设置隐藏层层数,节点数,优化方法(dnn中Adagrad,linear中Ftrl),dropout ,BN,激活函数等。将linear和dnn连接起来。将点击率设置为lebel1,从经验实测效果上说,理论原因这里就不赘述了。
将训练数据序列化为protobuf格式,加快io时间,设置batch_size、epoch等参数就可以训练模型了。
No.2、模型优化
对于不同数据,选用不同的features,不同的数据清理方式,模型效果也会有不同,通过测试集验证模型评价指标,对于CTR预估模型来说,AUC是关键指标(稍后介绍)。同时监测查准(precision),查全率(recall),确定模型需要优化的方向,对于正负不均衡情况还可以加大小样本的权重系数。
一般来说,AUC指标可以达到0.7-0.8。当AUC在这个范围时,如果准确率较低,说明模型效果还有待提高,可以调整隐藏层数目(3-5)层和节点数(2**n,具体看自己的features输出维度),构建组合特征,构建交叉特征。学习率可设置一个稍微大点的初始值,然后设置逐渐衰减的学习率,加快收敛。优化手段千变万化,掌握其本质,在尽可能学习到更多的特征性避免过拟合。具体优化优化方法由模型的表现来决定。
No.3、模型评估
AUC(Area under Curve):Roc曲线下的面积,介于0.5和1之间。AUC作为数值可以直观的评价分类器的好坏,值越大越好。
直观理解就是:AUC是一个概率值,当你随机挑选一个正样本以及负样本,当前的分类算法根据计算得到的Score值将这个正样本排在负样本前面的概率就是AUC值,AUC值越大,当前分类算法越有可能将正样本排在负样本前面,从而能够更好地分类。
下表是经过调整后,不同算法实现的模型效果对比表:
图4:模型效果对比表
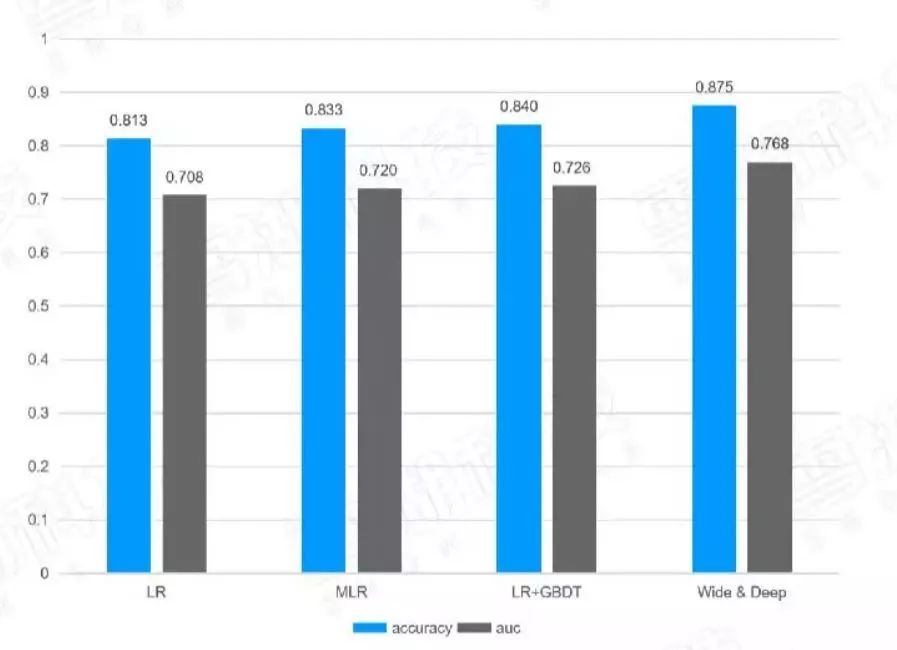
不断优化后得出几个模型的不同效果,将每一次广告曝光按照预测的CTR从小到大排序,可以根据预测的CTR值根据ECPM公式,按照单位曝光量统计出预估的ECPM和真实的ECMP进行比较,就可以知道预估的CTR值是否可靠了。正确预估CTR是为了把真正高CTR的广告挑出并展示出来么,错误地预估——把高的CTR低估或把低的CTR高估都会让高的ECPM不会排在最前面。在实际的实践过程中,CTR预测正确通常ECPM、CTR、收入这些指标通常都会涨。
No.4、模型部署
通常对于AI算法模型都是通过GPU服务器部署模型,但是对于推荐系统类算法逻辑计算较多,在速度上反而没有优势,部署成本也比较高,经济性很差。所以大都通过CPU云服务器部署,但是速度又不够理想。那么有没有另外一种可能?
答案是肯定的,可以通过FPGA+CPU的方式,大型推荐系统的上线都是通过云端部署,同时用在线和离线方式更新模型。雪湖科技FPGA开发团队把以Wide and Deep为基础网络的模型移植到阿里云FPGA服务器F3(FPGA:赛灵思 VU9P)上,用户可以通过镜像文件部署。根据最近的更新数据显示,模型精度损失可控制在十万分之二。相较于CPU服务器,FPGA服务器的吞吐量提高了3~5倍。当模型更新时,通过雪湖科技提供的工具可直接载入模型参数,可做到一键式更新模型参数。
No.5、CTR模型发展
Wide&Deep 虽然效果很好,但是随着算法的不断迭代基于Wide&Deep 模型思想,有很多新的模型被开发出来,基本思想是用FM、FFM代替LR部分,通过串联或者并联的方式与DNN部分组合成新的模型,例如FNN,PNN,DeepFM,DeepFFM,AFM,DeepCross等等,雪湖科技公司也致力于将所有CTR预估模型都完美兼容,在保证精度的前提下,增大吞吐量。
作者介绍:
本文作者为雪湖科技算法工程师 梅碧峰,现负责人工智能算法开发。在AI算法领域工作超过5年,喜欢戴着Sony降噪耳机埋头研究各类算法模型。理想主义的现实工作者,致力于用算法解放人工,实现1+1>2的问题。
-
FPGA
+关注
关注
1628文章
21724浏览量
602900 -
赛灵思
+关注
关注
32文章
1794浏览量
131242 -
机器学习
+关注
关注
66文章
8402浏览量
132539 -
硬件加速
+关注
关注
0文章
29浏览量
11126
发布评论请先 登录
相关推荐
易灵思FPGA产品的主要特点

FPGA加速深度学习模型的案例

思尔芯赛题正式发布,邀你共战EDA精英挑战赛!

PSoC 6 MCUBoot和mbedTLS是否支持加密硬件加速?
新思科技硬件加速解决方案技术日在成都和西安站成功举办

【国产FPGA+OMAPL138开发板体验】(原创)7.硬件加速Sora文生视频源代码
音视频解码器硬件加速:实现更流畅的播放效果

解析FPGA竞争格局背后的驱动因素






 工商网监
工商网监
评论