 深度学习中的YOLOv2-Tiny目标检测算法详细设计
深度学习中的YOLOv2-Tiny目标检测算法详细设计
近年来,以卷积神经网络(Convolutional Neural Network,DNN)为代表的深度学习算法在许多计算机视觉任务上取得了巨大突破,如图像分类、目标检测、画质增强等[1-2]。然而,随着识别率的提高,深度学习算法的计算复杂度和内存需求也急剧增加,当前的通用处理器无法满足其计算需求。主流的解决方法是采用图形处理器(Graphics Processing Unit,GPU)、专用集成电路(Application Specific Integrated Circuit,ASIC)芯片或现场可编程门阵列(Field-Programmable Gate Array,FPGA)来提升计算性能。GPU采用单指令流多数据流架构,想要充分发挥计算性能,需要大批量数据,并且由于高并行度导致的高功耗,很难应用于对功耗有严格限制的场合[3]。ASIC对于具体应用可以获得最佳性能和能效,但是研发周期长,需要对市场有长久的预见性。FPGA作为一种高性能、低功耗的可编程芯片,可以使用硬件描述语言来设计数字电路,以形成对应算法的加速电路结构。与GPU相比,FPGA低功耗、低延时,适用于小批量流式应用[4]。与ASIC相比,FPGA可以通过配置重新改变硬件结构,对具体应用定制硬件,适用于深度学习这种日新月异、不断改变的场景。
本文首先介绍深度学习中的YOLOv2-Tiny目标检测算法[5],然后设计对应的,并且就加速器中各模块的处理时延进行简单建模,给出卷积模块的详细设计,最后,在Xilinx公司的Zedboard开发板上进行评估。
1 YOLOv2-Tiny模型简介
YOLOv2-Tiny目标检测算法由以下3步组成:
(1)对任意分辨率的RGB图像,将各像素除以255转化到[0,1]区间,按原图长宽比缩放至416×416,不足处填充0.5。
(2)将步骤(1)得到的416×416×3大小的数组输入YOLOv2-Tiny网络检测,检测后输出13×13×425大小的数组。对于13×13×425数组的理解:将416×416的图像划分为13×13的网格。针对每个网格,预测5个边框,每个边框包含85维特征(共5×85=425维)。85维特征由3部分组成:对应边框中包含的80类物体的概率(80维),边框中心的相对偏移以及相对长宽比的预测(4维),边框是否包含物体的可信度(1维)。
(3)处理步骤(2)中得到的13×13×425大小的数组,得到边框的中心和长宽。根据各边框覆盖度、可信度和物体的预测概率等,对13×13×5个边框进行处理,得到最有可能包含某物体的边框。根据原图的长宽比,将得到的边框调整到原图尺度,即得到物体的位置与类别信息。
YOLOv2-Tiny由16层组成,涉及3种层:卷积层(9层)、最大池化层(6层)以及最后的检测层(最后1层)。其中,卷积层起到特征提取的作用,池化层用于抽样和缩小特征图规模。将步骤(1)称为图像的预处理,步骤(3)称为图像的后处理(后处理包含检测层的处理)。
1.1 卷积层
对输入特征图以对应的卷积核进行卷积来实现特征提取,伪代码如下:
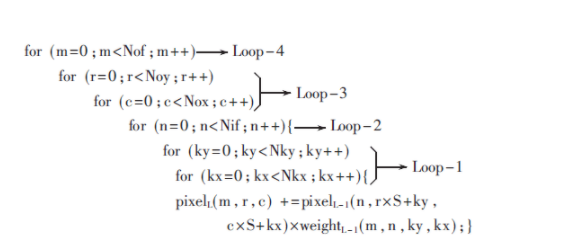
其中(Noy,Nox)、Nof、Nif、(Nky,Nkx)、S分别代表输出特征图、输出特征图数、输入特征图数、卷积核大小和步长。pixelL(m,r,c)代表输出特征图m中r行c列的像素。
1.2 池化层
对输入特征图降采样,缩小特征图的规模,一般跟在卷积层后。YOLOv2-Tiny采用最大池化层,最大池化层伪代码如下所示:
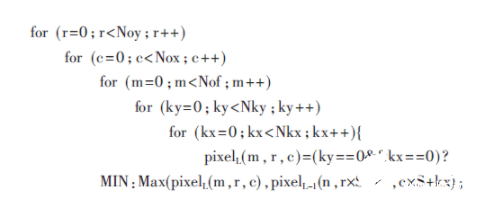
其中Max函数表示返回两者中较大的值,MIN表示某最小值常量,其他参数含义与卷积层类似。由于池化层与卷积层类似,只是将卷积层的乘加运算替换为比较运算;同时,考虑到卷积层往往在网络中占据90%以上的计算量,因此下文主要讨论卷积模块的设计。
2 基于FPGA的YOLOv2-Tiny加速器设计
2.1 加速器架构介绍
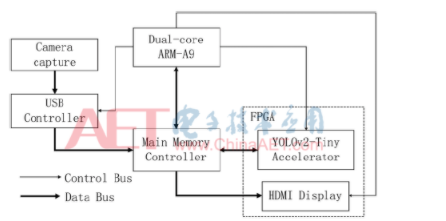
如图1所示,加速器采用三层存储架构:片外存储、片上缓存和处理单元内的局部寄存器。加速器从片外存储中读取卷积核权重参数与输入特征图像素到FPGA的片上缓存,通过多次复用片上缓存中的数据来减少访存次数和数据量。同时,计算得到的中间结果都保留在片上输出缓存或者局部寄存器中,直至计算出最终的结果才写回片外存储。同时,也可以看出,加速器的时延主要由三部分组成:访存时延、片上传输时延和计算时延。对应于该加速器架构,实际可以分为4个模块:输入读取模块、权重读取模块、计算模块与输出写回模块。
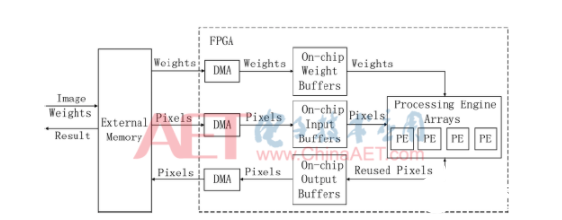
对应的加速器数据流伪代码如下:

2.2 卷积模块
对卷积循环中输出特征图数和输入特征图数两维展开,形成Tof×Tif个并行乘法单元和Tof个深度的加法树,流水地处理乘加计算。以Tof=2,Tif=3为例,如图2所示。
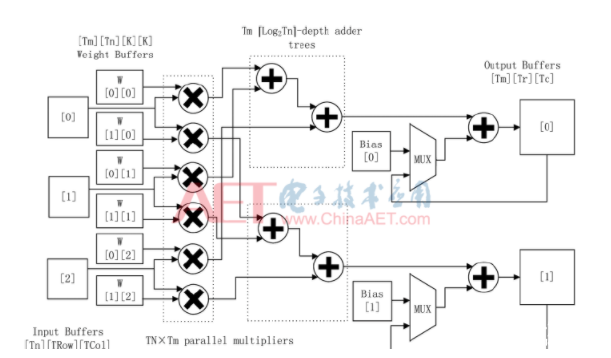
充满流水线后,每个时钟从Tif个输入缓存中读入Tif个像素,从Tof×Tif个权重缓存中读入相同位置的参数,Tof×Tif个并行乘法单元复用Tif个输入像素进行乘法计算。Tof个加法树将乘积两两相加,得到的结果和中间结果累加后,写回对应输出缓存。卷积模块对应的处理时延为:
其中Const表示流水线初始化等其他操作所需时钟,Freq表示加速器的工作时钟频率。
2.3 各模块的时延建模
本节介绍除卷积计算模块外,另外三个模块(输入读取模块、权重读取模块、输出写回模块)的处理时延。在此约定,MM(Data Length, Burst Lengthmax)表示以最大突发长度Burst Lengthmax访存读取或写入Data Length长度的连续数据所需的访存时延。
2.3.1 输入读取模块
输入读取模块的时延LatencyLoad IFM由两部分组成:
(1)通过DMA从片外读取Tif张输入特征图像Tiy×Tix大小的像素块到片上的访存时延:
(2)将输入特征图像素块传输到片上缓存的传输时延:
一般对两个过程乒乓,输入读取时模块的处理时延为:
2.3.2 权重读取模块
权重读取模块的时延LatencyLoad W由两部分组成:
(1)通过DMA从片外读取Tof个卷积核中对应Tif张输入特征图的Nky×Nkx个权重到片上的访存时延:
(2)将权重参数传输到片上缓存的传输时延:

2.3.3 输出写回模块
输出写回模块的时延LatencyStore由两部分组成:
(1)将输出特征图像素块传输到DMA的传输时延:
(2)通过DMA将Tof张输出特征图Toy×Tox大小的像素块写回片外的访存时延:

通过乒乓缓冲设计,将输入读取模块的时延LatencyLoad、卷积模块的计算时延LatencyCompute和输出写回模块的时延LatencyStore相互掩盖,以减少总时延。
3 实验评估
3.1 实验环境
基于Xilinx公司的Zedboard开发板(Dual-core ARM-A9+FPGA),其中FPGA的BRAM_18Kb、DSP48E、FF和LUT资源数分别为280、220、106 400和53 200。双核 ARM-A9,时钟频率667 MHz,内存512 MB。采用Logitech C210摄像头,最大分辨率为640×480,最高可达到30 f/s。当前目标检测系统的FPGA资源耗费如表1所示。
对比的其他CPU平台:服务器CPU Intel E5-2620 v4(8 cores)工作频率为2.1 GHz,内存为256 GB。
3.2 总体架构
如图3所示,从USB摄像头处得到采集图像,存储在内存中,由ARM进行预处理后交由FPGA端的YOLOv2-Tiny加速器进行目标检测,检测后的相关数据仍存放在内存中。经ARM后处理后,将带有检测类别与位置的图像写回内存中某地址,并交由FPGA端的HDMI控制器显示在显示屏上。
对应的显示屏上的检测结果如图4所示。COCO数据集中图片进行验证的检测结果如图5所示。
3.3 性能评估
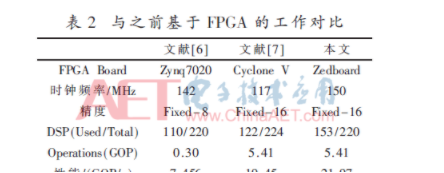
当前的设计在性能上超过了之前的工作,如表2所示。文献[6]中的设计虽然通过缩小模型以及减小数据精度等方式将简化后的整个YOLOv2-Tiny网络按层全部映射到FPGA上,但是各层间由于没有使用乒乓缓冲,导致访存与数据传输时延无法与计算时延重叠。文献[7]中的设计将卷积运算转化为通用矩阵乘法运算,并通过矩阵分块的方式并行计算多个矩阵分块,但是将卷积转化为通用矩阵乘法需要在每次计算前对卷积核参数复制与重排序,增加了额外的时延与复杂度。
矩阵分块的方式,并行计算多个矩阵分块,但是将卷积转化为通用矩阵乘法需要在每次计算前对卷积核参数复制与重排序,增加了额外的时延与复杂度。
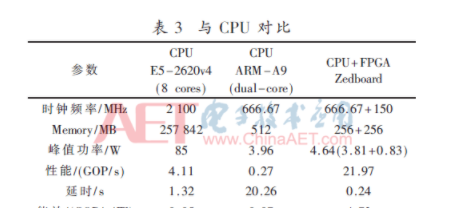
如表3所示,与CPU相比,CPU+FPGA的异构系统是双核ARM-A9能效的67.5倍,Xeon的94.6倍;速度是双核ARM-A9的84.4倍,Xeon的5.5倍左右。
4 结论
基于深度学习的目标检测算法在准确度上已超过了传统方法,然而随着准确度的提高,计算复杂度和内存需求也急剧增加,当前的通用处理器无法满足其计算需求。本文设计并实现了一种基于FPGA的深度学习目标检测系统,设计了YOLOv2-Tiny硬件加速器,就加速器中各模块的处理时延进行简单建模,给出卷积模块的详细设计,最终实现的设计性能超过了当前的工作。
参考文献
[1] RUSSAKOVSKY O,DENG J,SU H,et al.Imagenet large scale visual recognition challenge[J].International Journal of Computer Vision,2015,115(3):211-252.
[2] LIN T Y,MAIRE M,BELONGIE S,et al.Microsoft coco:common objects in context[C].European Conference on Computer Vision. Springer,Cham,2014:740-755.
[3] YU J,GUO K,HU Y,et al.Real-time object detection towards high power efficiency[C].2018 Design,Automation & Test in Europe Conference & Exhibition(DATE).IEEE,2018:704-708.
[4] CONG J,FANG Z,LO M,et al.Understanding performance differences of FPGAs and GPUs[C].2018 IEEE 26th Annual International Symposium on Field-Programmable Custom Computing Machines(FCCM).IEEE,2018.
[5] REDMON J, FARHADI A.YOLO9000:better,faster,stronger[C].Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition,2017:7263-7271.
[6] 张雲轲,刘丹。基于小型Zynq SoC硬件加速的改进TINYYOLO实时车辆检测算法实现[J]。计算机应用,2019,39(1):192-198.
[7] WAI Y J,YUSSOF Z B M,SALIM S I B,et al.Fixed point implementation of Tiny-Yolo-v2 using OpenCL on FPGA[J].International Journal of Advanced Computer Science and Applications,2018,9(10)。
作者信息:
陈 辰1,严 伟2,夏 珺1,柴志雷1
-
深度学习
+关注
关注
73文章
5527浏览量
121833 -
卷积神经网络
+关注
关注
4文章
368浏览量
11977
发布评论请先 登录
相关推荐
采用华为云 Flexus 云服务器 X 实例部署 YOLOv3 算法完成目标检测

在树莓派上部署YOLOv5进行动物目标检测的完整流程
基于迅为RK3588【RKNPU2项目实战1】:YOLOV5实时目标分类
慧视小目标识别算法 解决目标检测中的老大难问题

深度学习算法在集成电路测试中的应用
YOLOv5的原理、结构、特点和应用
口罩佩戴检测算法

人员跌倒识别检测算法

安全帽佩戴检测算法

基于Tiny AI技术的玻璃敲碎声事件离线检测方案

深度解析深度学习下的语义SLAM

OpenVINO™ C# API部署YOLOv9目标检测和实例分割模型






 工商网监
工商网监
评论