 不同应用程序的存储IO类型解析
不同应用程序的存储IO类型解析
存储系统作为数据的载体,为前端的服务器和应用程序提供读写服务。存储阵列某种意义上来说,是对应用服务器提供数据服务的后端“服务器”。应用服务器对存储系统发送数据的“读”和“写”的请求。然而,不同的应用程序对存储的数据访问类型有所不同。
本文描述典型的不同应用程序的存储IO类型。帮助读者了解不同应用程序存储IO类型的同时,提供的数据也可以为存储模拟和压力测试的数据参考。
IO类型描述:
描述不同应用的存储IO类型之前,先要描述存储中的定义IO的几个术语:
IO大小(IO Size):IO Size是应用程序发起,经过操作系统的磁盘子系统,向存储系统发送的读写请求的单位大小。不同的应用程序所发送的IO大小都不相同,例如对于数据库应用,它在数据读写的时候IO Size是8KB,而在事务日志的写入的时候可能是512Bytes-64KB不等。所以,通常所说的IO Size都是一个平均的概念。即某一款应用在一段时间内的平均IO大小。
读写比例(Read/Write):读写比例比较容易理解,就是应用程序读数据和写数据分布。这个在规划存储的时候也至关重要,因为存储系统中的保护级别(RAID)的不同,对写有损失。例如RAID-5单次写入需要分别对数据位和校验位进行2次读和2次写。所以说,如果用RAID-5作为写入比例较高的应用,显然会对性能有很大影响。
顺序与随机读写比例(Random/Sequential):顺序和随机读写取决与应用的获取数据的方式。通常情况下,如果数据的读取和写入是在连续的磁盘空间上,可以认为是顺序读写。如果应用读取的数据分布在不同磁盘空间,且无固定的顺序,则视为随机读写。由于传统的机械磁盘(闪存盘不再讨论之列)读写数据需要盘面的转动和磁头的移动,这使得随机读写的效率在物理磁盘层面要远小于顺序读写。通常存储系统都都会利用缓存来减少这部分的延迟,减缓因为磁头的移动而带来的性能损失。随机读写的代表的是OLTP的数据库文件,顺序读写的代表则是数据的事务日志。
应用程序存储IO类型:
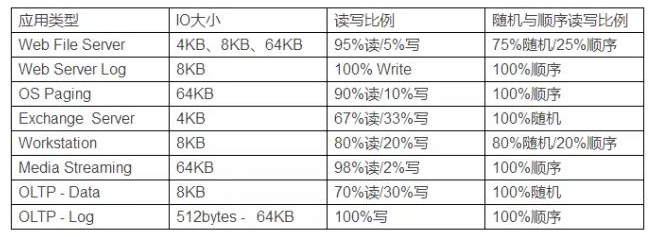
下面的表中描述的不同的应用程序对应的IO大小、读写比例、随机和顺序比例。表中的比例为一个通用的参考值,比例接近真实各种应用的IO类型。当然不能包含全部的应用类型因为根据不同生产环境,数值也会有很大的差异。这里的数据提供一个参考,可以用于使用压力测试工具,例如IOMeter,模拟不同应用的IO负载。
IOmeter是一款用于单系统和集群系统的I/O子系统度量(Measurement)和特征化(Characterization)工具,它是一个负载生成器(Workload Generator),也是一个度量工具(Measurement tool),可用于模拟任何程序或benchmark的磁盘或网络I/O操作,在单个或多个(联网)系统上生成并度量负载。
IOmeter由两个程序组成,Iometer和Dynamo。Iomter是控制程序/GUI,它告诉Dynamo需要做什么,收集数据结果并总结到一个输出文件。一次只应该运行一个Iometer,通常运行在服务器上。
Dynamo是一个负载生成器,它没有GUI,在Iometer的命令下执行I/O操作并记录性能信息,然后返回数据给Iometer。一次可以运行多个Dynamo,通常是一个副本运行在服务器上,另一个副本运行在每一台客户端上。Dynamo是多线程的,每一个副本可以模拟多个客户端程序的工作(Workload),每一个正在运行的Dynamo副本被称为是一个Manager,Dynamo中的每一个线程被称为worker。
不同应用通常具有不同的I/O类型,了解应用的I/O类型是为其设计解决方案、排错性能问题的首要工作。那I/O类型通常包括哪些需要考虑的因素?我们今天就来谈一谈I/O类型的几个重要方面。
读 vs. 写
应用程序的读写请求必须量化,了解他们之间的比列,因为读写对存储系统的资源消耗是不通的。了解读写比率直接关系到如何应用缓存、RAID类型等子系统的最佳实践。写通常需要比读更多的资源,SSD的写操作相对读更是慢得多。
顺序 vs. 随机
传统存储系统通常都是机械硬盘,因此整个系统设计为尽可能顺序化I/O,减少由于磁盘寻道所带来的延迟。所以,顺序I/O相对随机I/O的性能会好很多。随机小I/O消耗比顺序大I/O更多的处理资源。随机小I/O更在意系统处理I/O的数量,即IOPS;而顺序大I/O则更在意带宽,即MB/s。因此,如果系统承载了多种不同的应用,必须了解它们各自的需求,是对IOPS有要求,还是对带宽有要求。这往往需要在两种之间进行折衷考虑。闪盘是一个例外,它没有机械寻道操作,因此对随机小I/O的处理是非常迅速的,由此是读操作。
大I/O vs. 小I/O
我们通常把<=16KB的I/O认为是小I/O,而>=32KB的I/O认为是大I/O。就单个I/O来讲,大I/O从微观的角度相比小I/O会需要更多处理资源,不过对于智能存储系统来说,会尽可能把I/O整理为顺序的,以单个操作执行,如此依赖,将多个小I/O整理成单个大I/O处理后,反而会更快。I/O的大小依然取决于应用程序本身,了解I/O的大小,影响到后期对缓存、RAID类型、LUN的一些属性的调优。
位置引用
数据的位置分布影响到后期对二级缓存或存储分层技术的应用,因为这些技术都会根据I/O的位置分布来判断是否将I/O放置到缓存或快速的层级。位置引用是指那些被频繁的存储位置,我们通常认为最新创建的数据以及最近被访问过的数据,它们周围的数据也同时被访问的可能性会比较大。因此,了解应用程序的I/O位置特性,有助于应用正确的性能优化技术。
稳定 vs. 爆发
I/O数量在一天中的不同时段会有不同的表现。例如,早高峰时段的I/O数量相比下班后的I/O会多出许多。如果能准确预测和估计应用的I/O在不同时间段的稳定性和爆发性,可以正确分配资源,提高资源利用率。在前期的设计阶段,就应该考虑系统是否能够处理I/O高峰期。
多线程 vs. 单线程
多线程是实现并发操作的一种方式,同时也意味着对存储系统的资源消耗更多。这种高IOPS的请求方式,在有些情况下会造成磁盘繁忙,进而导致I/O排队,增加了响应时间。因此,适度的调整线程数量,不仅可以实现并发,而且能在不拖累整个存储系统的情况下,达到最优的响应时间。
编辑:hfy
-
存储技术
+关注
关注
5文章
746浏览量
45883 -
存储系统
+关注
关注
2文章
414浏览量
40921
发布评论请先 登录
相关推荐
【教程】DNS域名解析服务systemd-resolved使用指南


AWTK-WEB 快速入门(2) - JS 应用程序

λ-IO:存储计算下的IO栈设计

AWTK-WEB 快速入门(1) - C 语言应用程序
华纳云监视Linux磁盘IO性能命令:iotop,iostat,vmstat,atop,dstat,ioping
存储单元是指什么
Linux磁盘IO详细解析
存储芯片有哪些类型
初识IO-Link及IO-Link设备软件协议栈





 工商网监
工商网监
评论