 在FPGA上如何使用non-blocking cache设计框架
在FPGA上如何使用non-blocking cache设计框架
带宽是影响FPGA加速器的重要因素,因为大量的并行计算对数据量要求很大。如果加速器对数据的访问是不规则的,那么cache miss就会大大影响加速器性能。这篇来自FPGA2019会议的报告,向我们展示了如何来更好的处理cache miss问题,提高对缓存的利用率以及提高加速器效率。
1. Cache miss的问题
假设DDR可以提供12.8GB/s的带宽,FPGA上的并行加速器的数据输入带宽为0.8GB/s,可以并列16个这种加速器。这些加速器通过arbiter来直接访问DDR。如果它们访问的数据是连续规则的,那么DDR的带宽可以被充分利用。但是这些加速器需要的数据在DDR中并不是规则排列的,如图1.1。这样就会造成频繁的访问DDR,这样DDR的带宽就不够用,造成的结果就是加速器会受到延迟,效率无法得到提升。就如同图1.1所示,实际上有效利用的DDR带宽只有0.8GB/s。
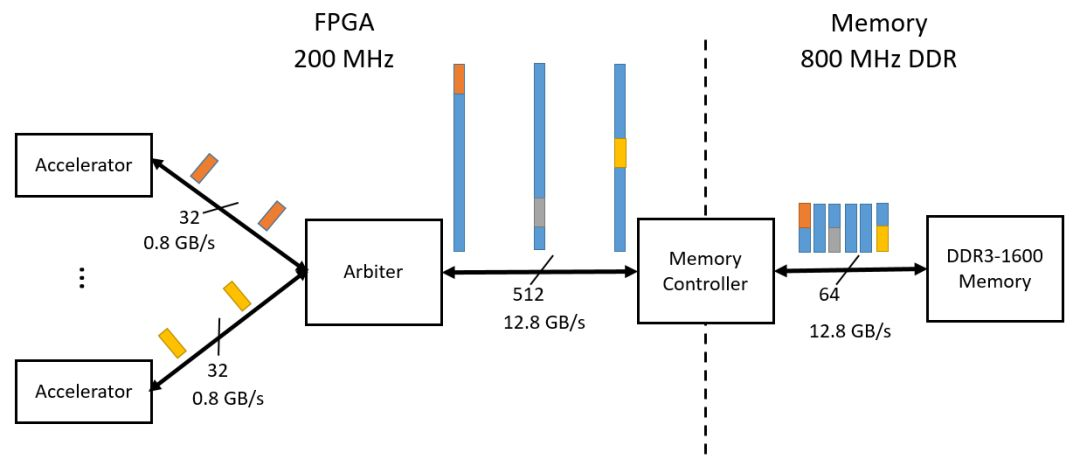
图1.1 不规则数据需要造成频繁访问DDR
一种解决问题的方法是使用blocking cache,将还没有用到的数据缓存起来以便之后使用。然而这样存在两个问题:一个是如果缓存中没有需要的数据,那么就需要从DDR中获取数据,这就会有很大延迟,因为对DDR的数据进行随机访问是非常耗时的;另一个是缓存的使用效率很低,内部大部分数据都不能被及时消耗,以便等待被利用到。
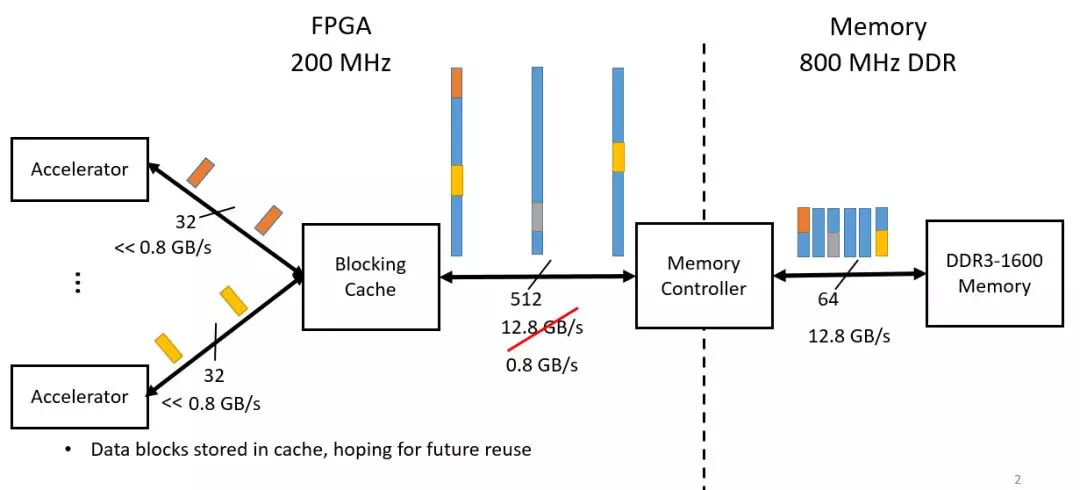
图1.2 blocking cache的使用
另外一种解决的办法是non-blocking cache,这正是本文提出的方法。这种方法的关键是加速器可以允许一定数量的cache miss。Cache miss不会阻塞对后面数据的获取。这就要求前后的数据没有依赖关系,而且允许的cache miss数量足够多,能够允许在这些时间可以从DDR中获取miss的数据,否则一样会造成加速器等待喂数。
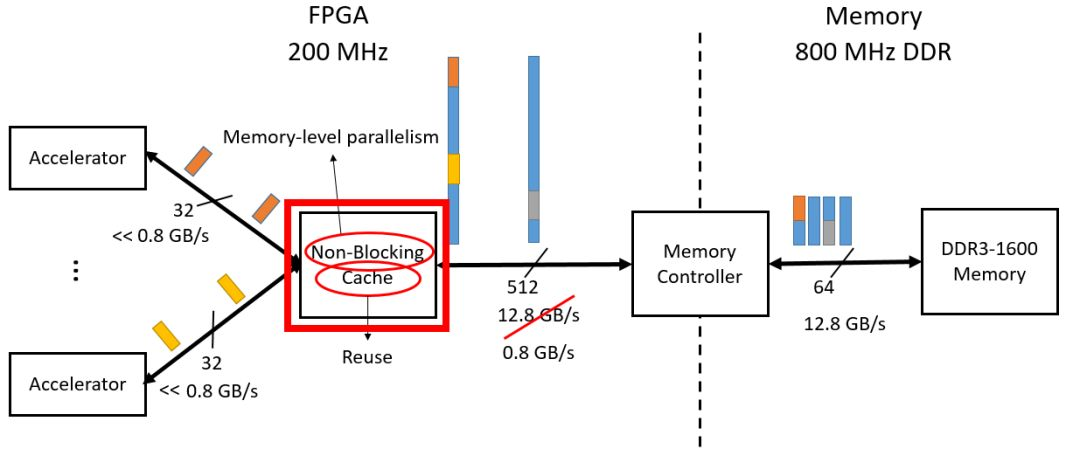
图1.3 non-blocking cache
2. 传统的Non-blocking cache结构
图2.1是一个基本的non-blocking cache结构,它主要由cache array以及MSHR组成。Cache array中含有tag和数据,tag用来表示加速器请求的数据的在外存中的地址。通过tag可以判定请求的数据在cache中是否存在。MSHR首先被Kroft使用,它含有数据未被命中需要去外存获取的具体信息:包括外存地址,用于判定加速器是否会再次命中相同的数据。还有cache的地址,用于决定从外存获取的数据存储到cache的位置,给哪个加速器使用。还有输入请求确认标志,表示这个缺失的数据是否从外存读取到。基本操作是:当加速器第一次从cache中获取数据没有命中,那么就在MSHR中记录下相应的信息和状态,当第二次相同数据miss发生,除了在MSHR中记录信息外,则启动从外部存储器获取数据,并更新到cache中。取回来的数据会根据MSHR中的信息将需要的数据发送给加速器。所以一个包含n个表项的MSHR有n个比较器用于比较数据地址,是否属于同一个miss的数据等。使用non-blocking cache能够提高运算效率,减少等待时间,提高带宽利用率。但是这种传统的MSHR消耗很多逻辑资源,不利于规模扩展。
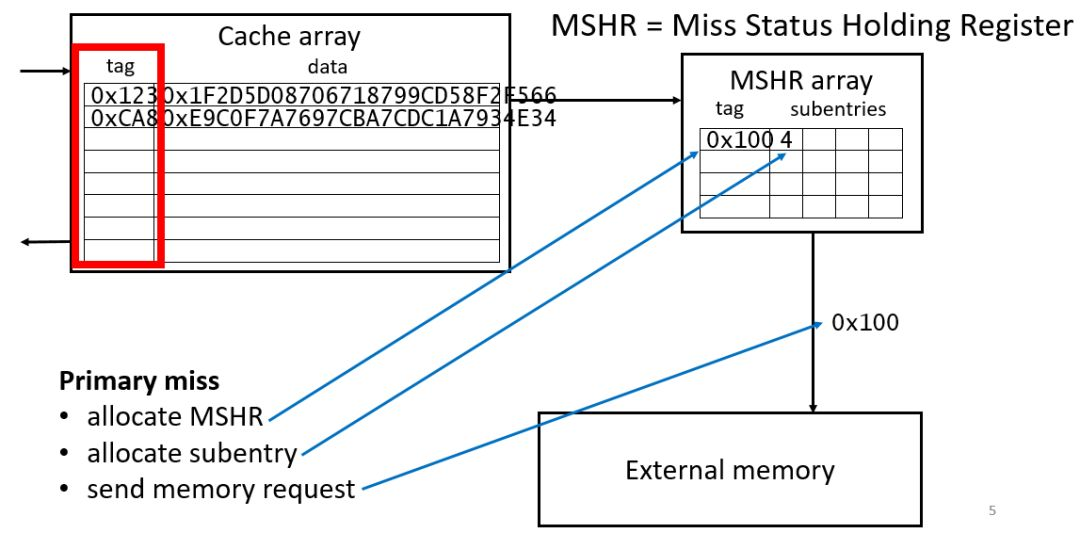
图2.1 non-blocking cache的基本结构和操作
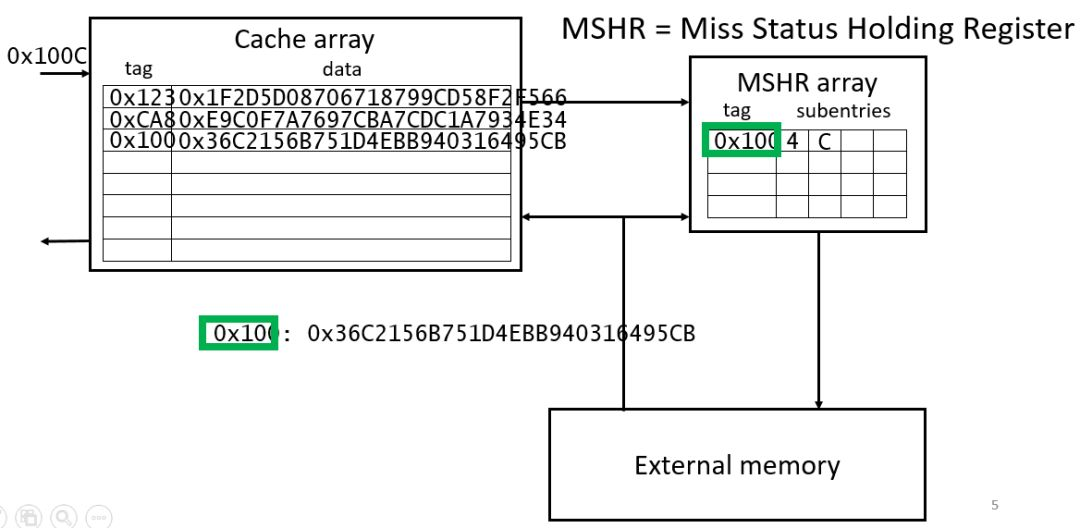
图2.2 更新cache
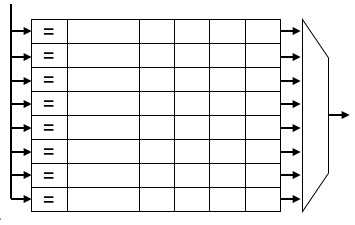
图2.3 MSHR逻辑结构
3. 对non-blocking cache的改进
为了能够有效扩展MSHR,可以使用多个MSHR,每个MSHR有n个表项,这样相比于使用一个MSHR能节省逻辑资源。但是这涉及到一个问题,如果一个配置MSHR的请求在多个MSHR表都有冲突,那么就造成配置MSHR表的等待。这样就导致了加速器运算的等待,不能够执行下一条指令。
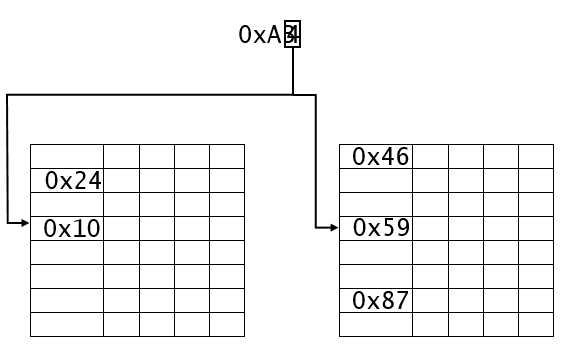
图3.1 两个MSHR被请求表项都被占用
解决办法就是Cuckoo hashing算法。假设有两个MSHR表,T1和T2。每个r个表项。每个元素通过函数h1和h2来确定表项位置,即:T1[h1(x)],T2[h2(x)]。为了插入表项内容x,检查T1对应位置是否空,如果空,就插入。如果非空就检查T2,如果T2也非空,这就是冲突的情况,那么就插入到T2中,将原来的内容z替换。然后z再去查询T1表,如此循环进行。这样就不会造成阻塞。

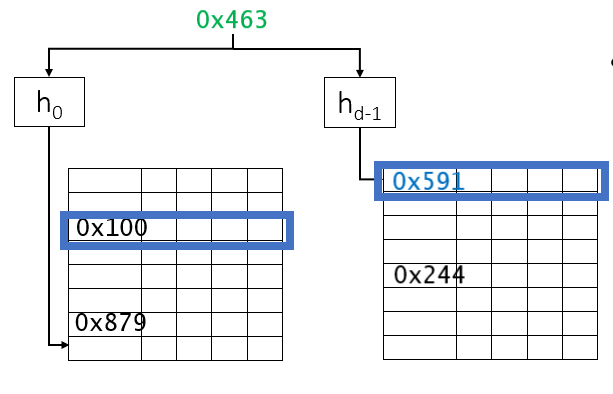

图3.2 Cuckoo hashing
还有一个问题是,MSHR中的表项subentries大小是固定的,如果要扩展表项的subentries,那么所有的内容都是同等扩展,这样可能有一些内容并不需要那么大。所以为了能够有效利用存储资源,论文作者提出了动态可扩展subentries内容的方法。将tag和subentries分隔开分别存储,这样如果有更多加速器miss相同的数据,那么就可以在一个subentries表后再扩展需要的subentries。这样就是在需要级联的subentries中增加指针来级联到下一个subentries表。

图3.3 可扩展subentries

图3.4 表项扩展
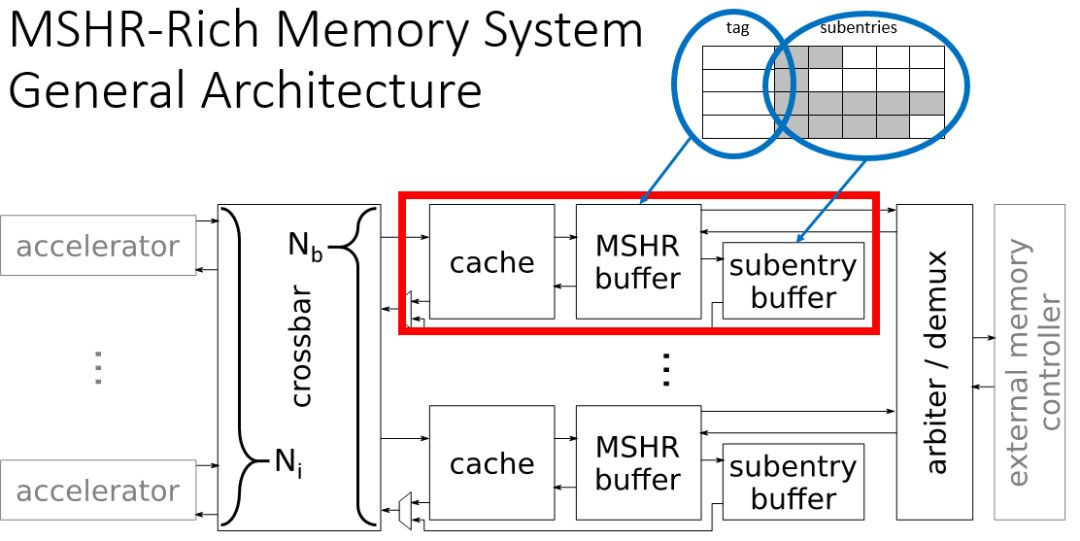
图3.5 整体结构
4. 结论
本文主要总结了non-blocking cache的设计框架,以及在FPGA上如何使用。介绍比较简略,更详细的资料还需要了解CPU体系中non-blocking cache的具体结构。作者也处于学习之中,欢迎讨论。
文献
1 Stop Crying Over Your Cache Miss Rate:
Handling Efficiently Thousands of Outstanding Misses in FPGAs, Mikhail Asiatici and Paolo Ienne, February 26, 2019
-
FPGA
+关注
关注
1634文章
21832浏览量
608111 -
cpu
+关注
关注
68文章
10943浏览量
213811 -
加速器
+关注
关注
2文章
813浏览量
38340 -
DDR
+关注
关注
11文章
717浏览量
65737
发布评论请先 登录
相关推荐
dm6467t使用ti的codec怎么才能实现8路d1 h264编码?
Verilog函数中function里的过程语句该怎么写
UCOSIII内建消息,使用OS_OPT_PEND_NON_BLOCKING任务不能切换
介绍一种多级cache的包含策略(Cache inclusion policy)
AX88783 pdf datasheet(双端口以太网交换
LMH6580/LMH6581,pdf datasheet
LMH6583,pdf datasheet (16x8 55
Cache中Tag电路的设计
SN65LVCP204,pdf(2.5Gbps 4x4 Cr
如何正确保护共享数据编写并行程序





 工商网监
工商网监
评论