 基于Xilinx 7系列GTX高速收发器的初步调试方案
基于Xilinx 7系列GTX高速收发器的初步调试方案
本来写了一篇关于高速收发器的初步调试方案的介绍,给出一些遇到问题时初步的调试建议。但是发现其中涉及到很多概念。逐一解释会导致文章过于冗长。所以单独写一篇基本概念的介绍,基于Xilinx 7系列的GTX。
需要说明,文本只是初步介绍基本概念,会尽量使用通俗浅显的描述而避免使用专业词汇,也只会描述一些基本的、常用的内容,不能保证全面型。所以从专业角度看,可能部分用词和原厂文档有出入,同时覆盖面不够,请见谅。
GTP、GTX、GTH和GTZ:
这四个是Xilinx 7系列FPGA全系所支持的GT,GT的意思是Gigabyte Transceiver,G比特收发器。通常称呼为Serdes、高速收发器,GT,或者用具体型号(例如GTX)来称呼。
7系列中,按支持的最高线速率排序,GTP是最低的,GTZ是最高的。GTP被用于A7系列,GTZ被用于少数V7系列。从K7到V7,最常见的是GTX和GTH。GTH的最高线速率比GTX稍微高一点点。
GTX和GTH的文档都是UG476。从这里就能看出来,这两个GT的基本结构大同小异。所以掌握一个,另一个基本也就熟悉了。
UG476文档链接:http://link.zhihu.com/?target=https%3A//www.xilinx.com/support/documenta...
TX和RX:
严格说TX应该是Transmitter,表示发送部分。GTX的TX部分结构图如下:
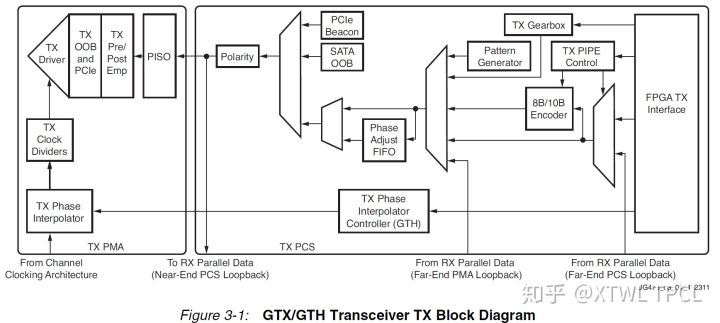
图片来自UG476
RX的全称是Receiver,结构图如下
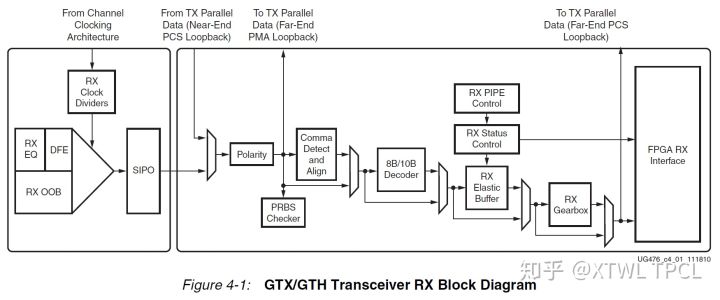
图片来自UG476
后面的内容会用到这两张图,可以翻看一下。
PMA,PCS
从TX和RX的结构图可以看到一个共同点:结构图主体分为两个部分,左边一个小框图,右边一个大框图。
左边小框图的部分就是PMA,右边大框图的部分是PCS。
为了便于理解,PMA的功能可以简单描述为:
1.串并转换(图中的SIPO和PISO);
2.模拟部分;
由此可以反推出来,PCS中的功能,都是并行的数字电路处理。
理论上说GTX的最小必要单元就是PMA,其主要原因就是核心的模拟部分。而PCS理论上可以全部由FPGA普通逻辑来实现。当然作为硬核提供的PCS功能更多、性能更好、使用更方便。
Elastic Buffer
一般称为弹性buffer,基本结构是一个FIFO,常用于处理buffer两边的跨时钟问题。不过其实有更多的用途,比如Clock Correction或者Channel Bonding。
另外还有一种不用Elastic Buffer的模式,一般称为buffer bypass模式,算是一种高级应用。有兴趣的童鞋可以参考文档研究一下。
8b10b
通常说8b10b是一个编码方式。在这里还指GTX PCS中的一个模块。
作为编码,8b10b有平衡电平,防止连续1/0的功能。编码分为正负码和特殊K码。最常用的K码应该是k28.5。8b10b最大的优势在于自带错误检测。当出现8b10b错误的时候,大概率是链路质量有问题。8b10b最大的劣势是效率比较低,有20%的额外开销,所以常用于低于8G的场景,最常见的、使用8b10b、同时又高于8G线速率的似乎是CPRI Rate7,线速率9.8G左右。
作为GTX的一个模块,发送端提供了方便使用的编码接口,接收端提供了方便使用的输出指示,直接使用即可。
另外,GTX还提供了Gearbox。除了8b10b之外,还有其他很多编码方式,比如64b66b,Gearbox就是为这一类编码做准备的。
PRBS
PRBS是伪随机序列码,GTX自带了PRBS的生成器(在TX内部)和PRBS接收/检查模块(在RX内部)。ibert中的误码率检查就是基于内置的PRBS模块。
从结构图可以看到,PRBS和8b10b没有项目连接的直接关系,所以ibert的测试中没有使用8b10b编码(也没有使用其他编码)。同时内部的PRBS也不支持使用其他编码。所以如果想在GTX外部使用PRBS信号源,可以另外单独做PRBS的生成器和校验模块。Xilinx似乎是有相关参考设计的。
ibert
ibert是Xilinx提供的一个用于GT辅助调试的IP。
首先明确一下,这是一个IP。所以ibert有两种用法:
1.直接使用example design进行独立使用;
2.集成到某个工程中进行使用;
ibert最常用的两个用途是:
1.基于PRBS模块的误码率检查;
2.基于眼图扫描模块的测量近端眼图;
另外,ibert中可以方便的设置GTX的所有参数。是个不错的参数测试平台。
通常可以尝试几个参数的调整来查看对GTX的误码率/眼图是否有帮助,这几个参数是TX部分的预加重。而接收端的设置是均衡模式,由于均衡的原理较为复杂,而且多为自动调整,所以不会有简单的几个参数就能看出变化。
GTX的分布
7系列FPGA通常按照bank来分,对于GTX的bank,一般称为一个Quad,原因是一个bank中有4个独立的GTX通道。每个通道称呼为Channel。所以在GTX的代码中可以看到Channel这个底层原语。
每个Quad拥有两个参考时钟Pin,也可以从上下两个Quad中获取参考时钟(如果上下有GTX Quad的话)。
QPLL和CPLL
已经知道四个GTX为一组,称呼为Quad,每个GTX称呼为Channel,就很容易理解QPLL和CPLL了。QPLL是一个Quad共用的PLL,GTX一个Quad只有一个QPLL。CPLL是每个Channel独有的PLL。
从底层角度看,由于CPLL是每个Channel独有的,所以CPLL的所有接口都在Channel这个底层模块中。而QPLL是另外使用了一个叫common的底层模块。
GTX中QPLL和CPLL,除了数目(一个Quad一个QPLL四个CPLL)和归属(QPLL属于common,CPLL属于Channel)不同之外,最大的不同在于支持的最高线速率频率不同。CPLL最高只有6.xG,而QPLL可以超过10G(具体数值要根据器件的速度等级来查询DataSheet)。
即使QPLL工作在很高的线速率下,Channel也可以工作在较低的线速率下。具体的实现方案就是1.使用Channel自带的CPLL而不用QPLL;2.Channel可以将QPLL的速率按2的倍数进行降低;这样同一个参考时钟下,一个Quad的不同GTX有机会跑在不同的线速率下。当然这一需求需要更多的操作,IP本身无法实现。
Clock Correction
这个功能必须使用Elastic Buffer。
原理是指定一个关键字段(类似于k28.5的二进制数),发送端定期发送这个关键字段,接收端收到这个关键字段时,会检查这个字段在FIFO中的位置,并通过插入 无效数据/删除数据 的方法来调整,使这个字段尽可能保持在FIFO的中心部分,防止FIFO溢出。
这个功能的作用是来解决不同时钟会导致FIFO溢出的问题。
Channel Bonding
这个功能必须使用Elastic Buffer。
原理是指定一个关键字段(类似于k28.5的数字)。当多个GTX都收到这一字段时,会按照配置进行相互校准,来保证并行数据同步输出。
这个功能的作用是在多个GTX之间进行同步化处理。
GTX IP及Example Design
GTX的IP是7 Series FPGAs Transceivers Wizard。是一个 非常有用的工具。
关于具体的配置,需要依据具体应用来设置。这里主要说两点
1.Protocol
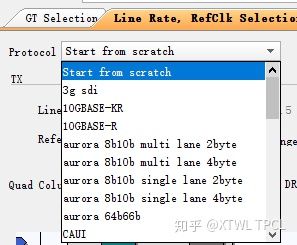
图片来自GT IP GUI
在IP配置界面的第二个标签页下有一个Protocol的选项,通常默认是Start from scratch,代表没有任何预设值。当熟悉GTX并熟悉应用的需求后,可以用这个设置进行逐项调整。其他选择都多少加入了一些预设值。在不熟悉GTX或者应用需求时,可以先使用预设配置进行学习/测试。
2.Shared Logic
单独的GTX通常是无法直接工作的,而最主要的原因就是GTX的复位流程。GTX有严格的复位流程。如果自行设计,费时费力。万幸,Xilinx提供了参考设计——Shared Logic。
通常使用Example Design来作为最终系统集成的GTX IP。这样做的原因就是包含了需要的复位控制等辅助设计,并且接口变得更加简单易用。默认这部分是包含在Example Design中,而IP可以选择将这部分重新打包,放入IP Core中。这样最终的IP不仅仅有GTX的硬核,也有大量Shared Logic这样用普通可编程逻辑实现的功能模块。

图片来自GT IP GUI
配置好GTX IP之后,另一个非常有用的功能就是Example Design。Vivado的一个优点就是几乎所有的IP都可以非常便捷的生成独立完整的Example Design(比如需要独立使用ibert的时候)。
GTX IP是提供源代码的,最底层就是GTX的Channel和common模块。用户可以通过代码来查看相关的参数值和端口连接。
GTX的DRP端口
通常一个内部模块要进行重配置,使用的是两种做法:端口控制和配置参数控制。
端口控制就是提供一个控制端口作为开关。比如BRAM端口中的EN和WE,提供高低电平就可以进行功能的改变(EN控制是否使用,WE控制读写)。
配置参数控制,就是有一个配置参数表,每一个参数拥有一个唯一地址和对应的数据内容。通过改写对应地址的数据内容来进行功能的改变。
GTX同时使用了这两种方式。所以GTX Channel和Common不仅有大量的端口(当然大部分端口都是功能端口而不是仅仅作为配置功能),还拥有一张地址表(参考UG476的附录)。通过DRP端口可以读写地址表中的相关地址,达到获取数据/改变配置的功能。
一个常见的应用就是线速率切换。这时候就需要利用DRP端口来调整部分参数的值,然后复位GTX,来使GTX工作在不同的线速率下。
另一个用到DRP的应用就是眼图扫描。希望扫描出GTX的眼图,除了使用ibert,还可以在设计中加入眼图扫描模块来进行实时扫描,这时候就需要使用DRP端口。
使用DRP端口的时候,有一个地方需要注意,就是DRP端口的时序。UG476似乎没有提供接口时序。这部分请参考XADC的文档手册——UG480。
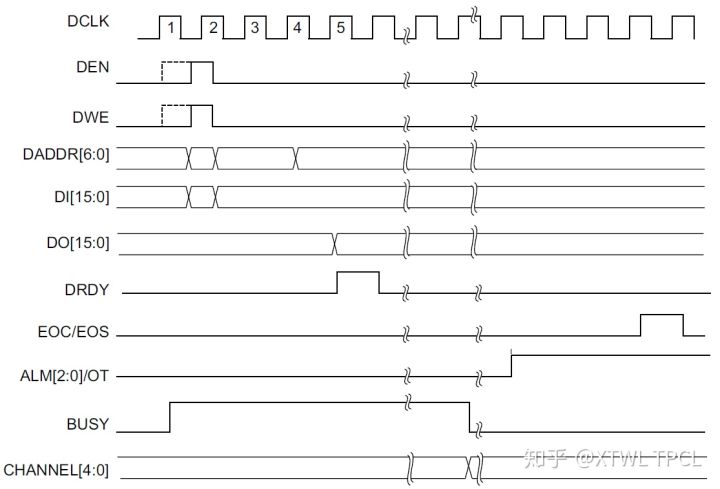
图片来自UG480
环回
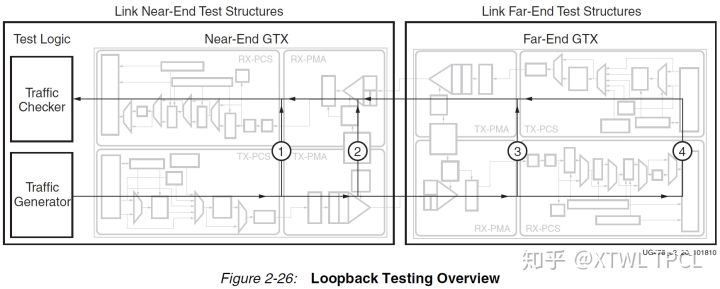
图片来自UG476,左边为接收端,右边为发送端
GTX提供了四种环回模式,结合上图可以看到,环回路径分别是1、2、3、4。
1,2是近端环回,用于测试GTX本身。3,4是远端环回,用于辅助测试对端GTX。
具体的细节请参考UG476。这里需要说明的是,用的比较多的是2,近端PMA环回;用的最少的大概是1,近端PCS环回,基本没有什么实际作用(可以想想为什么)。远端环回需要修改部分参数才能使用,具体参考文档。
关于GTX的一些基础概念就介绍完毕,更多细节,还请参考UG476文档。
编辑:hfy
-
收发器
+关注
关注
10文章
3431浏览量
106043 -
Xilinx
+关注
关注
71文章
2167浏览量
121568
发布评论请先 登录
相关推荐
影响光纤收发器性能的三大因素
Xilinx 7系列收发器GTX入门讲解
801系列光纤收发器:打造全能型数据传输解决方案
【米尔-Xilinx XC7A100T FPGA开发板试用】+04.SFP之Aurora测试(zmj)
射频收发器就是基带吗
光纤收发器pwr是什么意思
光纤收发器的作用、使用方法及应用
光纤收发器怎么区分发射端和接收端
FPGA高速收发器的特点和应用
收发器的主要作用与种类详解
高速串行收发器原理及芯片设计
思瑞浦推出高速CAN收发器TPT133X系列
思瑞浦发布高速CAN收发器TPT133X系列






 工商网监
工商网监
评论