 解决Python解释器读取的字符集识别问题
解决Python解释器读取的字符集识别问题
Python初学者编码实践中经常遇到encode error,decode error,如下:
例1:
UnicodeEncodeError: 'ascii' codec can't encode character u'/u5728' in position 1
例2:
UnicodeDecodeError: 'utf-8' codec can't decode bytes in position 0-1: invalid continuation byte
1、百度的时候,大家都建议在代码文件头加上字符集定义:
# -*- coding: utf-8 -*-
这种方法大部分情况下可以解决大部分的问题。那么它解决的是什么问题呢?
我们需要理解两个概念:
1)、# -*- coding: utf-8 -*- 的作用是声明 python源代码文件的编码格式。 谁会读取Python的源代码呢? 一个是IDE编辑工具,比如pycharm,nodpad++,editpluss等,我们在写代码的时候使用。
2)、另一个是Python解释器,是执行Python程序的时候使用。
当我们使用IDE编辑器打开Python代码的时候,如果出现乱码,我们都知道是编辑器的解码方式和代码文件的编码方式不一致导致的。需要修改编辑器的解码方式。
那么Python解释执行Python程序的时候使用的是设么解码方式呢?可以用下面的方式查看:
sys.getdefaultencoding()
可以用下面的方式修改:
reload(sys)
sys.setdefaultencoding('utf-8')
sys.getdefaultencoding()
所以,代码文件第一行加 字符集定义,解决Python解释器读取Python代码文件时的字符集识别问题
2、在print的时候出现异常,或者写文件,或者解析网络报文,或者做str对象处理的时候出现乱码。
这个时候我们需要理解:
1)、文件读写、网络报文读写都可以理解为IO读写。是byte处理,所以读写前后需要使用同样的字符编码方式。
2)、print、str对象的处理涉及到终端的编码格式。print之后,在pycharm的输出窗口,或者windows的CMD命令行窗口,或者Linux的shell窗口,需要适配终端的编码方式
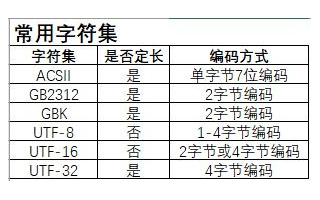
3)、字符编码基本可分为三大类:起源于美国的ASCII,支持英文字符、数字、标点符号、键盘上的特殊字符;国际编码unicode,支持ascII的字符集外,又支持中文,韩语,日语等。因为unicode占用空间大,所以又出现了utf-8。需要强调的一点是:
unicode:简单粗暴,所有字符都是2Bytes,优点是字符->数字的转换速度快,缺点是占用空间大
utf-8:精准,对不同的字符用不同的长度表示,优点是节省空间,缺点是:字符->数字的转换速度慢,因为每次都需要计算出字符需要多长的Bytes才能够准确表示
1.内存中使用的编码是unicode,用空间换时间(程序都需要加载到内存才能运行,因而内存应该是尽可能的保证快)
2.硬盘中或者网络传输用utf-8,网络I/O延迟或磁盘I/O延迟要远大与utf-8的转换延迟,而且I/O应该是尽可能地节省带宽,保证数据传输的稳定性。
下面详细介绍了unicode和utf-8的使用场景:
在程序执行之前,内存中确实都是unicode编码的二进制,比如从文件中读取了一行x="egon",其中的x,等号,引号,地位都一样,都是普通字符而已,都是以unicode编码的二进制形式存放与内存中的
但是程序在执行过程中,会申请内存(与程序代码所存在的内存是俩个空间),可以存放任意编码格式的数据,比如x="egon",会被python解释器识别为字符串,会申请内存空间来存放"egon",然后让x指向该内存地址,此时新申请的该内存地址保存也是unicode编码的egon,如果代码换成x="egon".encode('utf-8'),那么新申请的内存空间里存放的就是utf-8编码的字符串egon了
针对python3如下图
浏览网页的时候,服务器会把动态生成的Unicode内容转换为UTF-8再传输到浏览器
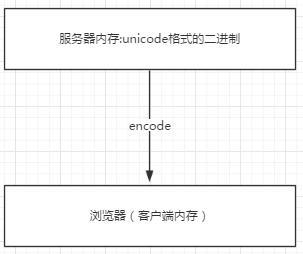
如果服务端encode的编码格式是utf-8, 客户端内存中收到的也是utf-8编码的二进制。
从上面的说明,我们知道了unicode和utf-8的应用场景,就需要用下面的方式进行转换:
字符串通过编码转换为字节码,字节码通过解码转换为字符串
str--->(encode)--->bytes,bytes--->(decode)--->str
编辑:hfy
-
python
+关注
关注
56文章
4795浏览量
84647 -
UTF-8
+关注
关注
0文章
13浏览量
7850
发布评论请先 登录
相关推荐
RISC-V MCU IDE MRS(MounRiver Studio)开发之:设置工程编码字符集
python正则表达式字符集
SVM在小字符集手写体汉字识别中的应用研究
信息交换用藏文编码字符集标准 GB16959-1997

MySQL字符集的设置修改和排序规则





 工商网监
工商网监
评论