 从M1芯片探讨苹果如何在技术上碾压Intel和高通
从M1芯片探讨苹果如何在技术上碾压Intel和高通
苹果Mac开始换用自家芯片,对Intel而言无疑是个打击。苹果在去年的MacBook系列产品发布会上,提到自家M1芯片时,不忘大谈相比前代MacBook产品,其CPU性能提升2.8倍;GPU性能提升5倍;比较的就是Intel处理器了。设备续航还提升到了20小时。
这些数字,就半导体行业摩尔定律停滞的现状来看简直不可思议。当然其对比内容、对比对象是值得商榷的。不过这样的对比数字,苹果并不是头一回用了。在Mac还在用PowerPC处理器的年代(1999年),苹果在宣传中曾提过,PowerPC G3比当时的Intel奔腾II快2倍。如此似曾相识。
这个所谓快“2倍”的说法,大致可窥见苹果在处理器理念上的一脉相承,即便当时的苹果还没有自己的芯片设计团队。事实上,当时所谓的快2倍,是苹果在发布会上对比Mac和Windows PC,分别采用PowerPC G3处理器和Intel奔腾II处理器,对比内容是双方自动执行一组Photoshop任务。
演示中的那台Mac能够用Windows PC一半的时间,完成这些任务。这其中的关键在于,PowerPC G3多加了个AltiVec加速单元,这是个128bit矢量处理单元,可单周期内执行4路单精度浮点数学运算。Photoshop能够充分利用这个单元,AltiVec效率比那时Intel的MMX扩展指令更高。
用简单的话来说,就是依靠专用单元来实现性能和效率的碾压。虽说PowerPC早就被x86打趴,但这个理念很大程度延续到了如今的苹果芯片(包括A系列和M系列SoC),下面将从技术角度详述,M1身上体现的这一点。
事实上,M1芯片的出现不仅让x86阵营感到了白色恐怖,而且也对高通这样的Arm阵营参与者构成了极大威胁。高通已经与微软合作过两代芯片(SQ1与SQ2)产品,且开推Surface Pro X(及其Windows 10 on Arm)两年,却在M1面前显得不值一提。
本文是《Intel换了CEO能做苹果M1那样的芯片吗?PC处理器大小核反击战》一文的姊妹篇,本文将从M1芯片的角度谈谈,苹果是如何在技术上达成对Intel、高通,以及其他竞争对手的威慑的;并尝试探讨,苹果为什么能做到这一点,以及Intel、高通这样的竞争对手又能否做到这一点。本文除前两部分之外,剩余部分皆可根据兴趣选择性阅读。
碾压Intel和高通
有关苹果为什么要给MacBook换用自家芯片的问题,可能答案有很多,包括苹果生态的全面掌控,以及出于对成本预算进一步的控制等。如果仅从处理器本身的性能和效率来看,AnandTech的一张图基本上很好地回答了这个问题:
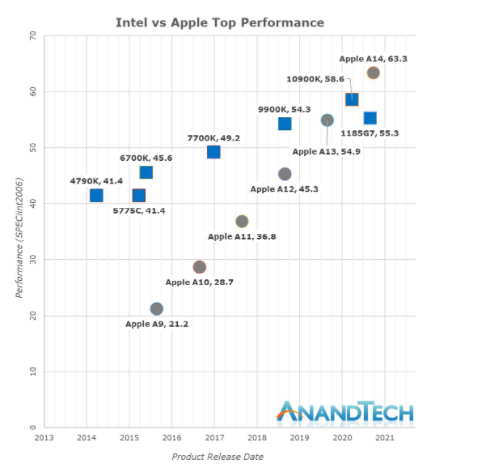
这张图对比的是Intel与苹果芯片,从2013年以来处理器的单线程性能变化趋势(具体测试项为SPECint2006)。在过去5年里,Intel处理器产品的单线程性能提升了大约28%,而苹果CPU则实现了198%的性能提升。或者说A14处理器单线程性能是A9的将近3倍。
M1与A14芯片共享了Firestorm大核,大致上可认为两者有着接近的单线程性能(M1频率高于A14,L2 cache也更大等)。2020年苹果芯片性能,因此刚好形成了相较Intel处理器的剪刀叉趋势。所以最新的MacBook开始采用自家芯片,就性能来看显得顺理成章。
事实上,苹果在A7芯片(iPhone 5s)时期就宣称,自家的Cyclone核心是“桌面级架构”。不过当时并没有多少人在意。而且在M1出现之前,更多人还是坚定地认为,Arm处理器相较x86,只能做低功耗,而无法实现如同x86那样的高性能。苹果却以实际行动证明了这个观点的错误性。
不少对比测试提到,M1比Intel酷睿i9还彪悍,这话是否夸张了?我们来大致梳理一下,M1芯片相较x86和Arm面向PC的主流处理器,性能处在哪个水平上。
苹果M1芯片本身的配置如下:

官方并未公布M1芯片的TDP(或大致功耗)。AnandTech测试认为M1的CPU TDP在20-24W。极客湾的测试也基本印证了其CPU TDP在25W左右(峰值功耗24W,日常峰值功耗在15W左右)。这个值未必是准确的,包括其中可能包含DRAM功耗,不过也八九不离十。
极客湾数据,GPU部分全速运转峰值功耗在10W左右;整个M1芯片可达成的峰值功耗大约为34W。AnandTech则在测试中提到,GFXBench Aztec High测试出现过17.3W的功耗,这个测试应该很难反映GPU单独占到了多少。整体上,这样的功耗与TDP水平,大约与Intel、AMD的低压处理器差不多。
AnandTech执行的测试项目比较多,这里仅选取SPEC2006/SPEC2017来阐明其实际性能。其SPECint2006整数性能测试,苹果M1与AMD Zen 3接近;SPECfp2006浮点性能测试,M1有显著更大的优势。综合下来,其性能综合表现如下:
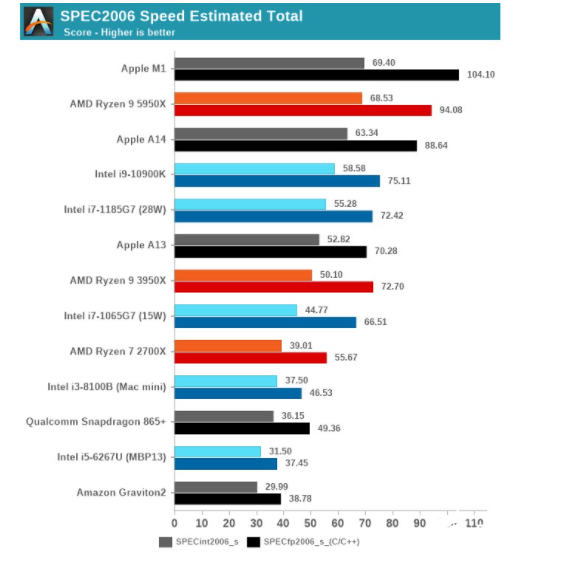
来源:AnandTech
需要注意,这是单线程性能成绩。M1的这个成绩显著强于Intel十一代酷睿(同等TDP水平的酷睿i7-1185G7),以及酷睿i9-10900K(十代酷睿,Comet Lake-S),甚至比AMD Zen 3(Ryzen 9 5950X)还要强。
苹果所说相比前代MacBook几倍几倍的提升,似乎完全没在吹牛。SPEC2017测试结果与SPEC2006也差不多,不过M1和AMD Zen 3(Ryzen 9 5950X)互有胜负,M1整数性能整体不及Zen 3,浮点性能则反超。
这个对比还基于一个事实:M1大核的最高频率仅为3.2GHz,而Intel十一代酷睿(i7-1185G7)的睿频为4.8GHz,酷睿i9-10900K的睿频更是能够达到5.3GHz;AMD Zen 3(Ryzen 9 5950X)睿频为4.9GHz。与M1相比,对比对象的功耗会明显更高。
换句话说,苹果M1事实上成为了如今CPU的IPC之王。IPC也就是每周期指令执行能力,或者说每Hz能干多少事。可见M1是能够甩开目前最彪悍的x86处理器的。
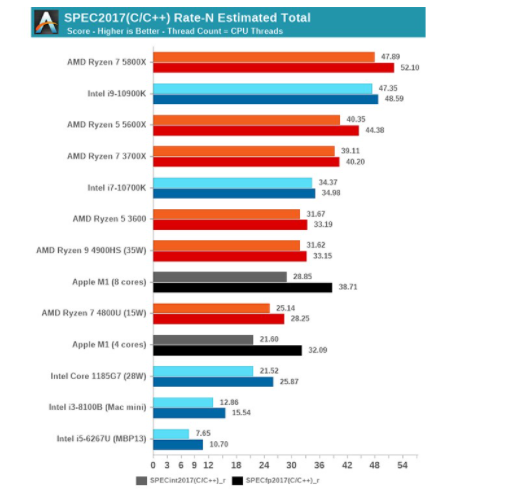
来源:AnandTech
多核性能测试方面,受限于M1本身仅有4个大核与4个小核,与堆了8核心、10核心还支持超线程的那群大家伙自然无法相比。不过M1在性能方面仍然能够碾压Intel低压版的十一代酷睿(i7-1185G7,4核8线程,睿频4.8GHz,TDP 28W)。M1如果扩大核心数量和处理器规模,则要实现多线程性能夺冠,应该也不是难事。
其他测试结果大致相似,包括Geekbench 5单线程测试,M1轻松夺冠,超AMD Zen 3(Ryzen 9 5950X)和Intel酷睿i9-10900K;CineBench R23单线程性能略弱于AMD Zen 3,多线程性能比AMD Ryzen 4800U(Zen 2,8核16线程)弱大约15.6%,比Intel十一代酷睿(i7-1165G7,4核8线程)强60%。
苹果为了实现M1芯片与x86软件的兼容性,做了Rosetta 2中间转译层。如此一来,以前的x86软件不需要改动,也能跑在M1芯片上。这种方案会令程序执行效率变低。即便有Rosetta 2转译,M1芯片跑传统x86程序,其性能也可达到Intel八代酷睿的水平(对于AVX指令依赖较低的程序,M1+Rosetta 2性能与十代酷睿相似)。
因为篇幅关系,测试项细节无法展开分析。不过总结一句话就是:在同等核心规模的CPU中,苹果M1芯片在跑常规性能测试时,能够以低很多的功耗达成相比x86处理器更强的性能。同等规模下,全面干翻Intel完全不是问题,即便和AMD打得有来有回,也是AMD牺牲功耗换来的(在单核性能测试中,AMD Zen 3能到49W功耗水平,而苹果M1为7-8W的整机功耗)。
前面这些都是与x86处理器相比,那么和同为Arm阵营的对手相比呢?微软2019年发布了Surface Pro X,这台设备搭载的是一枚叫做Microsoft SQ1的芯片,它实际上是高通骁龙8cx的马甲;2020年更新了Surface Pro X二代,Microsoft SQ2芯片,也就是二代骁龙8cx。
微软在Windows 10 on Arm的规划上,比苹果更早。高通骁龙8cx也成为M1芯片在Arm阵营的绝佳对比对象。Linus Tech Tips对骁龙8cx(二代)与M1芯片,做了性能测试对比。

来源:Linus Tech Tips,其中SQ2即为高通骁龙8cx二代
从Geekbench 5和CineBench R23的测试结果就很容易发现,M1可将骁龙8cx(Microsoft SQ2)按在地上摩擦。这两者根本就不在一个性能水平线上,不过骁龙8cx的功耗水平应该也更低(虽然好像Surface Pro X的续航也没比M1版MacBook Air优秀)。
比较具有讽刺意义的是,Linus Tech Tips尝试用一些虚拟机的奇技淫巧,给M1版MacBook Air装上了Windows 10 on Arm。然后用虚拟机里面的Windows来跑Geekbench 5,结果发现,其性能水平也遥遥领先于Surface Pro X,算是狠狠打了高通和微软的耳光:
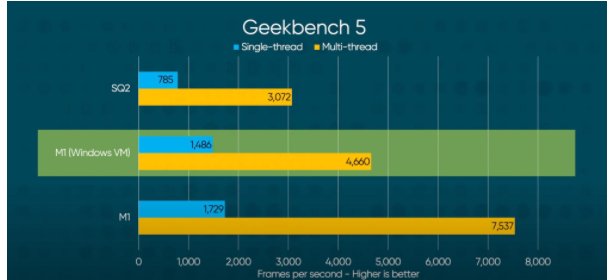
来源:Linus Tech Tips
这个测试也少了对于功耗的监测,不过它仍能说明M1芯片即便加个虚拟机中间层,跑别家操作系统,效率打个折扣,依然远强于高通如今面向低功耗PC所推的竞品。
除开性能,M1芯片的低功耗也已经有很多测试的先例了。在我上篇有关大小核设计的文章中也谈到了M1足以惊掉x86处理器下巴的低功耗表现,几乎所有日常使用场景,包括办公、网页浏览、闲置待机,功耗都比Intel和AMD同代竞品低了几个数量级:M1芯片网页浏览功耗仅相当于十一代酷睿的1/6,视频流播功耗则仅有十一代酷睿的15%,Word办公功耗则相当于十一代酷睿的20%-30%......
苹果究竟是如何做到拳打Intel/AMD,脚踢高通和Arm的?
要把芯片做大
前面这部分性能数据呈现,并未给出CPU之外其他部分的数据。包括苹果的8核GPU,性能相比Intel最新的Xe核显(十一代酷睿)都有显著优势,真实游戏性能可达到Geforce MX350的水平;以及AI专用单元、AMX等组成部分,鉴于篇幅皆不再展开。
标题说M1比Intel酷睿i9彪悍,这话虽不可一概而论——比如酷睿i9一定在多核性能表现上是优于M1的,毕竟处理器规模大很多。但作为一颗低压处理器,实际使用中,M1的确在很多场景下能够达到酷睿i9的水平。
比如Final Cut Pro剪视频实时预览和多种格式的编解码;Xcode写代码直接秒杀iMac 2020高配版;即便是以负优化著称的Adobe Premiere,M1都在很多项目上(而且还是Rosetta 2转译)足以对酷睿i9构成威胁。要知道M1和酷睿i9,前者定位便携式设备,而后者定位工作站(i9-10900K)。
苹果达成这个水平,究竟靠什么?很多人说是苹果的软硬件契合度高,这的确是个重要因素,但不够具体。总结成三点,大致上是M1芯片超宽微架构;诸多专用单元的堆砌;苹果超强的生态掌控力。
这几点将在下文详述。不过这几点的外部表现就是,很大的芯片面积(die size),或者很多的晶体管数量。因为无论是超宽的处理器微架构,还是为某些功能做专用的硬件单元,都需要更多的die空间。苹果自家芯片在A系列产品线上,就有超大die size的传统。早在苹果iPhone 5s时期,其芯片尺寸就比其他手机SoC大很多,有时大1倍(A11 Monsoon大核心加cache占地面积,比骁龙845的A75大核与cache大1倍还多)。
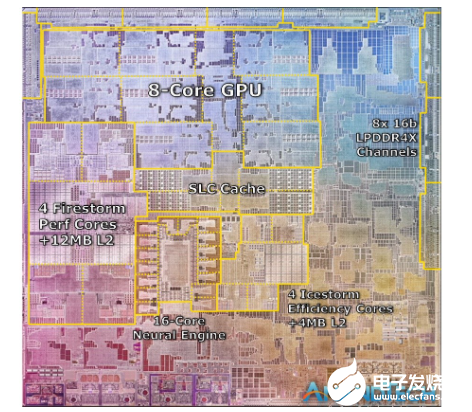
来源:AnandTech
如果单看die size的话,苹果A7、A8用上4MB L3 cache之时,同时代的Cortex-A57/A72/A73都还没有L3 cache,到A75才支持。更不要说苹果喜欢堆超大的L2 cache,苹果A11有着8MB L2 cache,可以用巨大来形容。高通骁龙835才3MB L2 cache,没有L3 cache(2016-2017年)。
而且苹果从几年前就喜欢给整个SoC芯片加system cache(或者叫System Level Cache -SLC,Arm公版设计现在普遍也有了)。这种system cache属于整个SoC级别的cache,在SoC的各个IP(如CPU、GPU、NPU等)之间共享。A12的system cache就达到了8MB,相比A11翻番。
A14与M1的system cache目前是16MB,是麒麟、骁龙这些移动阵营竞争对手的2-3倍。而Intel十一代酷睿Tiger Lake(i7-1185G7)的L3 cache也不过12MB。至于L2 cache,M1的Firestorm大核是12MB,小核都有4MB。移动阵营就不说了,Intel十一代酷睿L2 cache(i7-1185G7)为4x 1.25MB。作为对比,酷睿i9-10900K(十代酷睿)L2 cache 2.5MB(每核256KB),L3 cache 20MB。
(不过苹果的cache设计和一般CPU似乎不大一样,包括L2 cache共享;而且system cache在速度上应该也是比不上仅面向CPU的L3 cache的。)
L1 cache的巨型相较其他竞品(如192KB的L1指令缓存,是Arm公版设计的3倍,x86现有设计的6倍;据说速度还很快),也就不需要再多谈了。单就芯片上占地面积巨大的cache而言,苹果都始终在规模上有着令人肝颤的堆料。当然cache大小并不能说明性能高低,而且大尺寸的存储子系统易带来更高的时延。但论消费电子应用处理器的堆料,在低压处理器这个量级内,大概没人能强过苹果。下文还会详述,“堆料”堆的可不只是cache。

那么Intel、AMD、高通这些竞争对手也这么堆料可行吗?排除微架构上的一些限制不谈,就商业模式而言,Intel、AMD和高通虽然也可以这么做,但却非常不经济。因为这样堆料,意即die size的增加,也就意味着成本的急剧提升。芯片制造工艺的提升,一定程度也是为了在更小的die size内,实现更高的性能,并缩减成本。
苹果之所以可以这么做,是因为苹果最终面向用户出售的是终端设备。比如一台iPhone上,除了SoC芯片之外,还有屏幕、闪存、增值服务等。但面向用户时,就只有一个终端设备价格。抛开iPhone一年几亿销量,以及iPhone吃下整个手机市场大半的利润不谈,苹果也可以在不同组件之间来权衡、抵消、转嫁各种成本支出。iPad、MacBook也都可受惠于iPhone芯片设计的经验,及iPhone巨大出货量带来的营收。
而Intel、AMD、高通这些企业出售的只是处理器,他们需要依靠处理器来获取利润。下游手机厂商要赚钱,上游IP供应商也要赚钱。在产业链各不同环节利润叠加的情况下,成本控制显得尤为重要。
此外,Intel的处理器不仅面向某一个型号的PC,而且面向不同价位的PC,以及其他市场,如服务器、数据中心。其中的核心IP很大程度上会复用,如果核心都做得很大很宽,对需求大量核心并行运算的使用场景而言,就会显得尤为昂贵。所以单纯以芯片制造商身份存在的这些企业,很难像苹果这样“不讲武德”地堆料,因为其商业模式是根本不同的。
对于一般的芯片制造商而言,通过提升芯片频率来获得性能提升,而不是增大芯片面积、增加成本来获得性能提升,显然是更为经济的方案。
在成本控制问题上,尤为值得一提的是,在前年《深度学习的兴起,是通用计算的挽歌?》一文中,我曾提到芯片设计与制造的成本正在逐年攀升,尤其尖端制造工艺成本,包括建厂成本在内。即便不看技术限制,现有市场参与者也已经不可能再像过去那样按照摩尔定律去迭代制造工艺。而这件事情对于Intel的影响,也远大于对台积电、三星的影响。因为Intel主要营收来源就是尖端工艺,台积电和三星的早期制造工艺也是其重要的营收来源。
Intel在10nm与7nm难产的当口,将极易陷入恶性循环,不仅影响到其芯片产品的市场竞争力,而且可能会越来越远离世界最尖端工艺工厂的称谓。Intel如今背负的包袱,都会比苹果、AMD、高通、三星这些不同层级的市场参与者都明显更为沉重。
超宽的架构(选读)
当然,“把芯片做大”只是结果,而不是目的。之所以芯片做大,除了更大的cache获得更高的数据带宽之外,还在于苹果热衷于超宽的处理器架构,以及还喜欢给SoC加各种专用单元。以下文字内容皆可选读,面向轻度技术爱好者。
前文就提到苹果M1以仅3.2GHz主频,获得了超过竞争对手5GHz频率处理器的性能。那么M1的频率若是提到5GHz,岂不是就逆天了?这一点恐怕是无法达成的,因为苹果走的“宽”核心路线,将更不利于频率提升,否则功耗也更容易崩边。一般的,频率提高,功耗会以频率三次方的比例提高。所以那些以将近5GHz换得与M1差不多性能的处理器,也需要付出对应功耗的代价。
在iPhone 6s时代,苹果A9及更早的处理器,普遍有着比市面上同期竞品更低频率的传统。比如说苹果A8是1.5GHz主频,A9则为1.8GHz,而同期的Arm Cortex-A72频率已经来到2.5GHz,A73则为2.8GHz。但苹果处理器依然有默秒全的性能水准。这是因为苹果一直以来都很喜欢搞“宽”核心,实现更高的指令并行度,也表现在IPC数字上(虽然现在的A系列处理器也来到了3GHz水平上)。
即每周期可做的事情更多,自然能够以更低的频率跑任务。高指令并行或者高IPC,要求更“宽”的处理器核心,比如每周期能同时读取、解码,执行或者回写多条指令。提升指令并行度的方法有很多,当代处理器架构的一个重要因素就是乱序执行能力。也就是让没有依赖关系的指令可以乱序执行,后面的指令不必等到前面的指令执行完再执行。
不过乱序执行需要额外的电路,来解决很多可能会遭遇的实际问题,也就要求更多的芯片面积和功耗。而“拓宽”整个架构,比如提升每周期解码指令的数量,许多的dispatch单元,增加更多的ALU执行单元,以增加指令并行度,都需要额外的芯片面积。
而且拓宽架构也并没有那么简单,如何让拓宽的这些单元保持足够高的利用率,而不是浪费资源也多有讲究。但越宽的处理器架构,起码是实现较高指令并行的基础。
前文提到,对于Intel这样的芯片制造商,很多时候通过提升处理器频率来获得性能提升,而不是增大芯片面积、拓宽芯片架构、增加成本来获得性能提升,显然是更为经济的方案。更窄、更“深”的处理器架构,也更易于提升频率。
苹果M1芯片CPU部分的宽度,某种程度上达到了新高。下面这张图来自AnandTech,是Andrei Frumusanu画的Firestorm核心(即A14和M1大核心)架构框图,是他结合研究与经验得到的。现在流传绝大部分有关Firestorm微架构的解读应当都脱胎于此:
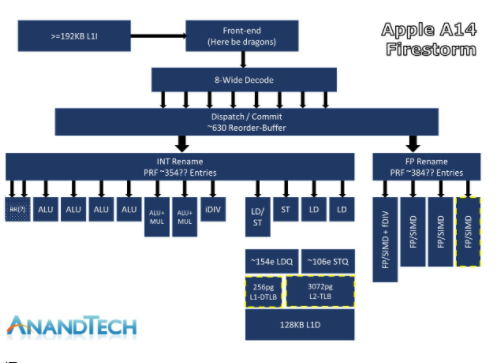
来源:AnandTech
其中有一些尤为值得一提的点。首先是前端8-wide指令解码,这是什么概念呢?AnandTech评论其为目前行业内“最宽的商用设计”。AMD和Intel当代处理器指令解码宽度普遍为4-wide(Intel为1+4);Arm这边,解码宽度主流是4-wide,今年主推的Cortex-X1为5-wide;传说中超超超宽的三星M3(Exynos 9810),解码宽度6-wide。
从AnandTech的研究来看,苹果A11、A12的解码宽度就达到了7-wide,A13步入8-wide大关。
其次是ROB(Re-order Buffer),也就是乱序执行的重排序buffer。Firestorm的ROB达到了630个条目(或者差不多630)。ROB越深,则一定程度上表明了具备更高的乱序度,也是更宽架构的写照。与此相比,Intel的十一代酷睿(Willow Cove)ROB为352条目,AMD Zen 3为256条目,Arm Cortex-X1为224条目。看起来高度指令并行就是苹果要达到的。
Firestorm的后端执行引擎部分也非常“宽”。整数管线部分,重命名物理寄存器堆(INT Rename PRF)大小约354条目,算术运算“至少”7个执行端口,包括4个简单ALU(ADD指令),2个复杂ALU(MUL),以及一个专用整数除法单元。核心每周期可处理2个分支。
不过整数管线部分“变化不大”,浮点与矢量执行管线部分是Firestorm的重点。前文也提到了在性能测试里,M1的浮点运算能力相比竞争对手有较大优势。Firestorm增加了第四条执行管线,浮点重命名寄存器为384条目,也“相当之大”。4条128bit NEON管线,和AMD、Intel桌面处理器现有吞吐一致。浮点操作吞吐与管线数为1:1的关系,意即Firestorm核心每周期能够执行4个FADD(浮点加法)操作和4个FMUL(浮点乘法)操作,分别3与4周期延迟,是Intel处理器每周期吞吐的四倍,Zen 3的两倍。
AnandTech评论说,这可能是苹果在浏览器测试中表现如此之优秀的原因。如今PC上的一个很重要的应用就是web浏览,这大约也是苹果意识到的用户需求迫切的一大应用场景吧。此外矢量执行能力不变,浮点除法、倒数、平方根操作吞吐较低。
最后是存储子系统部分,比较值得一提的是load-store前端,最高可以达到148-154个load与106 store,比市面上任何微架构都要宽。与此对比,AMD Zen 3这两个数字分别是44和64,Intel十代酷睿(Sunny Cove)分别为128和72。
而L1 TLB(translation lookaside buffer,一种页表的cache,是一个内存管理单元,用于提升虚拟地址到物理地址转换速度)翻倍至256 pages,L2 TLB提至3072 pages。L2 TLB因此能够覆盖48MB cache。缓存部分的提升,以及与其他竞品的对比,这里不再赘述——本文前一个段落已经做了解释。
只不过前面提到的这些并不是一蹴而就的。在iPhone Xs时期,苹果A12的Vortex核心在宽度上就已经有了桌面级CPU的规模,相比当时的Arm Cortex-A76和三星M3,都要宽上不少,无论是执行管线还是存储子系统。所以M1如今的这种超宽架构,也算是苹果芯片的一脉相承了。
引入更多专用单元(选读)
《深度学习的兴起,是通用计算的挽歌?》一文已经提到随摩尔定律放缓,通用处理器性能提升变慢,为保证满足应用对性能增长的需求,专用处理器是一条更能走得通的路。实践证明,这两年的这一趋势也愈发显著。
本文文首已经提到,PowerPC G3在对战Intel奔腾II时“2倍”速度就是依靠某个专用单元达成的。苹果的这种思路似乎早年就埋下了。
此前Geekbench测试工具经常被人戏称为Apple Bench,原因是很多人认为其中的某些测试项明摆着是给苹果和Arm专门设计的,而对x86非常不友好。多年前Linux之父Linus Torvalds曾评论Geekbench is sh*t. 原因是在Arm64架构处理器上,SHA1性能有专用硬件辅助,Arm处理器跑分因此就很好看。
在Geekbench 5单核性能测试里,M1的加密子项得分依然非常高,远高于酷睿i9-10990K。这是此前很多人认为,Arm靠这种方式来骗分,并认定Arm在高性能上做不到x86处理器的依据。不过这次Geekbench 5其他项目,比如整数、浮点性能,M1也能碾压酷睿i9(十代酷睿)。而且专用硬件单元辅助某个项目,本质上对于体验也是有帮助的。

类似的情况在苹果当代芯片上相当常见。比如用iPad(A14)和MacBook(M1芯片)做视频剪辑(尤其是Final Cut Pro),其体验和效率就远超Windows PC(Intel酷睿)。
这是基于M1芯片中的编解码器强过市面上绝大部分GPU(在Handbrake的硬件H.265测试里,M1的编码模块表现出对Intel和AMD的彻底碾压);外加M1之上的AI专用处理器也参与画面分析,专门的ISP(图像处理器)可执行 ProRes RAW格式的demosaic运算;而且M1内部还集成了SSD主控,对于I/O敏感操作也有帮助。
所以对于经常需要剪视频的人来说,M1简直太适配了。同理还有码农、摄影师,以及单纯的视频娱乐用户等。
这些都建立在M1作为一颗SoC,以更多专用单元来解决具体问题的基础上。虽说专用单元弹性欠缺,但苹果很清楚MacBook目标用户群日常都拿设备来做什么。有针对性地优化专用单元,并且提升特定使用场景下的操作体验,达成性能和效率(功耗表现)的双重提升。这也印证了通用计算裹足不前时,靠专用计算就是个重要方向,虽然未必得是专用处理器。
这些专用单元的存在,其本质在我看来,与Intel为酷睿增加AVX-512指令支持并无太大区别。无论说这些专用单元是“刷分”利器也好(甚至有人说system cache也是刷分利器),是奇技淫巧也好,它们都实实在在地发挥了作用。
这其中再度迸发的一个问题是,既然超宽架构和专用单元这么好,Intel和AMD为什么不做呢?其中的原因大概是多种多样的,而且Intel、AMD事实上也的确在朝着这些方向努力。或许更重要的一点在这两个选项,仍是以增加die size为基础的,参见文本第二部分。
还有一些现实问题,比如说具体到在CPU前端解码宽度问题上,x86这种变长指令,指令长度在1-15 bytes之间,而Arm为4 bytes定长指令。这也就意味着x86的解码器很难搞清楚一条指令究竟从哪里开始,需要对每条指令做长度分析。X86处理器在解码阶段因此要处理不少错误,AMD曾经谈到过增加更多解码器会导致更多的问题,而4-wide解码宽度成为其设计的一个限制。
恐怖的生态掌控力
从芯片设计,到操作系统,到开发生态,到消费终端设备设计制造,甚至到销售,苹果都一手掌控。这在整个业界怕都是绝无仅有的(三星似乎欠缺十分重要的操作系统环节)。其促成的商业模式,也是苹果可以如此在M1和Firestorm核心上任意妄为的基础,这在前文中就已经提过了。
而除了处理器本身的微架构,在更上层的系统设计以及软件架构上,苹果也有相当的话语权。M1设计上的一个典型代表是封装在一起的DRAM内存,采用一种叫Unified Memory Architecture技术。CPU和GPU使用内存时,不必再区隔不同空间,也就不需要在双方互通时进行内存拷贝这样的操作,实现更低的延迟和更高的吞吐。
(顺带一提:单核Firestorm也达到了58GB/s的读取带宽,33-36GB/s写入带宽,除了表现出色外 ,AnandTech评论“单核填满内存控制器这种设计令人震惊,我们之前也从未见到过”。)
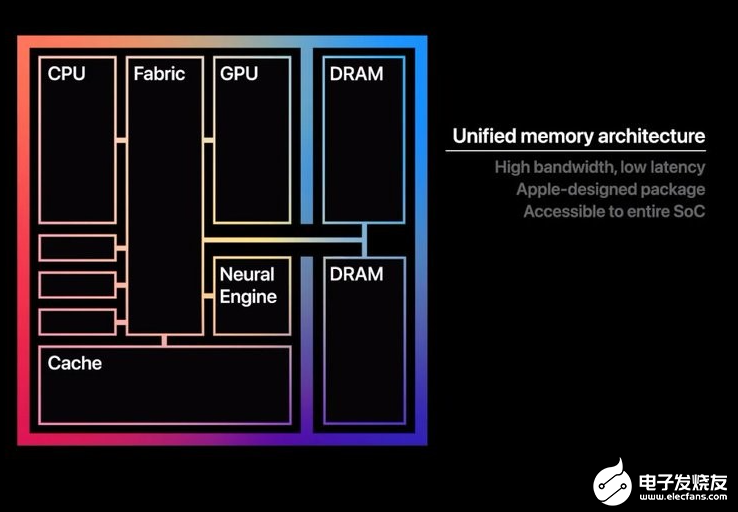
这种设计并不新颖,AMD早年也做过类似的技术,但并未得到普及。这种设计对于软件开发有新的要求。苹果牢固的开发生态掌控力,应付这种事应该也只是件小事。对Windows PC不同市场参与者分而治之的局面来说,这件事就显然没那么容易了。
与此同时,还能够显现苹果生态掌控力牢固的一点在于苹果十分轻易地在M1芯片上换用自家GPU。“原生代码”在图形计算一侧就显得没那么重要,苹果的Metal API可以直接为苹果GPU准备就绪,意即苹果图形计算方面的储备可在M1及现有生态上,立刻发挥作用。(虽然Metal相比DirectX,似乎在软件效率上还是弱了点)
微软在Windows 10 on Arm的生态部署上就万般掣肘,这虽然和微软自身举棋不定的决策力也有关。但在Arm版Windows出现这么久,也没有像样的生态构建起来,Windows开发者对于Windows Runtime也意兴阑珊,就能表现出苹果在这次转舵中的决绝和生态构建的超级速度。
前一阵传言微软决定自研芯片,用于将来的Surface。个人感觉这条信息的可信度不大,因为微软不像苹果那样,有数亿出货量的设备可为其分担芯片的设计和制造成本,尤其是尖端工艺的制造成本。要知道没有大量出货来分摊成本,以Surface的量是走不起尖端工艺的。但这条消息的出现也表明,苹果在M1及其周边生态的打造上,有多成功。
只不过苹果的这种模式与生态,究其根本也依托于消费电子终端设备的销量。若哪一日iPhone销量大幅下滑,则芯片业务与周边生态也将很快难以为继。分而治之的生态便没有如此脆弱。
用一句悲观的话来总结本文:Windows PC阵营恐怕很难出现苹果M1那样的芯片。不过这并没有什么大不了,毕竟是两个生态:看隔壁Android阵营也从不因为iPhone卖得多好,各参与者就乱了方寸。
参考来源:
[1] The 2020 Mac Mini Unleashed: Putting Apple Silicon M1 To The Test - AnandTech
https://www.anandtech.com/show/16252/mac-mini-apple-m1-tested
[2] Apple Annouces The Apple Silicon M1: Ditching x86 - What to Expect, Based on A14 - AnandTech
https://www.anandtech.com/show/16226/apple-silicon-m1-a14-deep-dive
[3] How did Microsoft screw this up? - Surface Pro X (SQ2) vs M1 Macbook Air - Linus Tech Tips
https://www.youtube.com/watch?v=OhESSZIXvCA
编辑:hfy
-
处理器
+关注
关注
68文章
19169浏览量
229155 -
高通
+关注
关注
76文章
7442浏览量
190363 -
intel
+关注
关注
19文章
3480浏览量
185755 -
半导体行业
+关注
关注
9文章
403浏览量
40473 -
M1芯片
+关注
关注
0文章
21浏览量
5078
发布评论请先 登录
相关推荐





 工商网监
工商网监
评论