 了解嵌入式C:什么是结构?
了解嵌入式C:什么是结构?
本文提供了有关嵌入式C编程中的结构的一些基本信息。
在介绍了结构之后,我们将看一下这个强大的数据对象的一些重要应用。然后,我们将检查C语言语法以声明结构。最后,我们将简要介绍数据对齐要求。我们将看到,通过简单地重新排列其成员的顺序,我们也许可以减小结构的大小。
结构体
逻辑上彼此相关的多个相同类型的变量可以分组为一个数组。在组上而不是自变量的集合上工作使我们可以整理数据并更方便地使用它。例如,我们可以定义以下数组来存储将语音输入数字化的ADC的最后50个样本:
uint16_tvoice[50];
请注意,uint16_t是宽度为16位的无符号整数类型。这在C标准库stdint.h中定义,该库提供与系统规格无关的特定位长的数据类型。
数组可用于对同一数据类型的多个变量进行分组。如果不同数据类型的变量之间存在联系怎么办?我们可以在程序中将这些变量视为一组吗?例如,假设我们需要指定 上面生成语音阵列的ADC的采样率。我们可以定义一个float变量来存储采样率:
floatsample_rate;
尽管变量voice和sample_rate彼此相关,但它们被定义为两个独立变量。为了使这两个变量相互关联,我们可以使用称为结构的C语言强大的数据构造。结构允许我们将不同的数据类型分组,并将它们作为单个数据对象处理。一个结构可以包括不同种类的变量类型,例如其他结构,指向函数的指针,指向结构的指针等。对于语音示例,我们可以使用以下结构:
structrecord{
uint16_tvoice[50];
floatsample_rate;
};在这种情况下,我们有一个称为record的结构,该结构 具有两个不同的成员或字段:第一个成员是uint16_t元素的数组,第二个成员是float类型的变量。语法以关键字struct开头。struct关键字后的单词是一个可选名称,用于以后引用该结构。我们将在本文的其余部分中讨论定义和使用结构的其他细节。
为什么结构很重要?
上面的示例指出了结构的重要应用,即定义了可以将不同类型的各个变量相互关联的依赖于应用的数据对象。这不仅导致处理数据的有效方式,而且使我们能够实现称为数据结构的专门结构。
数据结构可用于各种应用程序,例如两个嵌入式系统之间的消息传递以及将从传感器收集的数据存储在不连续的内存位置中。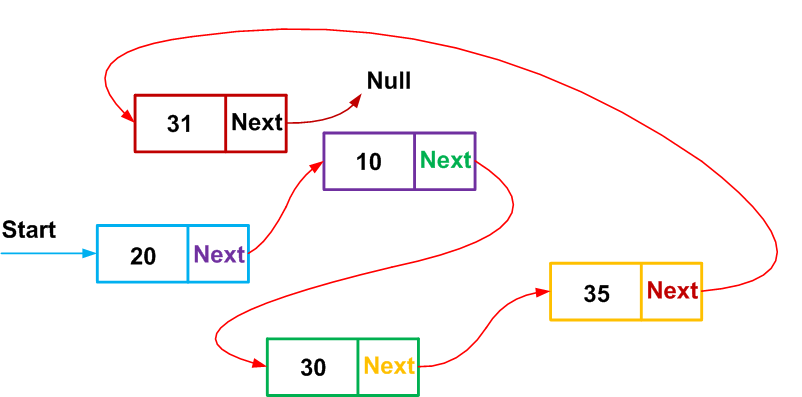
图1.结构可用于实现链表。
此外,当程序需要访问内存映射的微控制器外围设备的寄存器时,结构是有用的数据对象。在下一篇文章中,我们将介绍结构应用程序。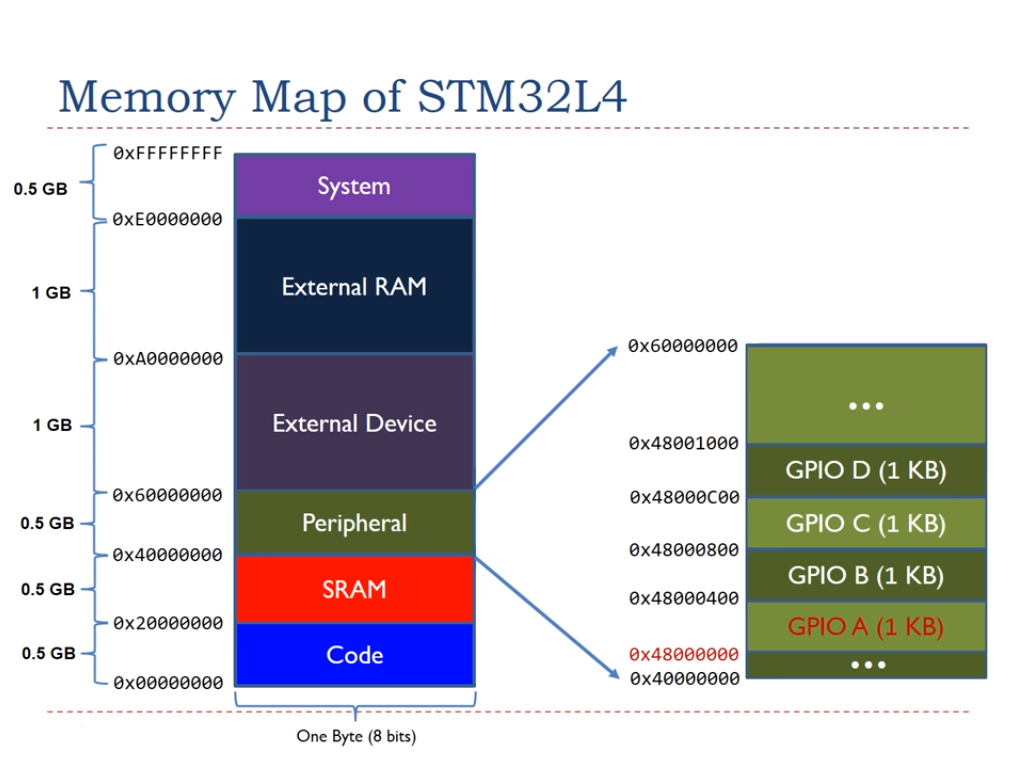
图2.STM32MCU的存储器映射。图片由带ARM的嵌入式系统提供。
声明结构
要使用结构,我们首先需要指定一个结构模板。考虑下面的示例代码:
structrecord{
uint16_tvoice[4];
floatsample_rate;
};这指定了用于创建此类型的将来变量的布局或模板。该模板包括一个uint16_t数组和一个float类型的变量。模板的名称为record,它位于关键字struct之后。值得一提的是,没有用于存储结构模板的内存分配。仅在定义了基于此布局的结构变量之后,才进行内存分配。以下代码声明 了上述模板的mic1变量:
structrecordmic1;
现在,为变量mic1分配了一部分内存。它有空间存储数组的四个uint16_t元素和一个float变量。
可以使用成员运算符(。)访问结构的成员。例如,以下代码将100分配给数组的第一个元素,并将sample_rate的值复制到fs变量(该变量必须是float类型)。
mic1.voice[0]=100; fs=mic1.sample_rate;
声明结构的其他方法
在上一节中,我们介绍了一种声明结构的方法。C语言支持其他一些格式,本节将进行介绍。在整个程序中,您可能会坚持使用一种格式,但有时可能会对其他格式有所帮助。
声明结构模板的一般语法为:
structtag_name{
type_1member_1;
type_2member_2;
…
type_nmember_n;
}variable_name;该TAG_NAME和变量名是可选的标识符。通常,我们会至少看到这两个标识符之一,但是在某些情况下,我们可以消除这两个标识符。
语法1:当同时存在tag_name和variable_name时,我们在模板后面定义结构变量。使用此语法,我们可以重写以下示例:
structrecord{
uint16_tvoice[4];
floatsample_rate;
}mic1;现在,如果我们需要定义另一个变量(mic2),我们可以编写
structrecordmic2;
语法2:仅 包含variable_name。使用此语法,我们可以按以下方式重写上一节中的示例:
struct{
uint16_tvoice[4];
floatsample_rate;
}mic1;在这种情况下,我们必须在模板之后定义所有变量,而我们以后不能在程序中定义任何其他变量(因为模板没有名称,以后也不能引用它)。
语法3:在这种情况下,没有tag_name或variable_name。以这种方式定义的结构模板称为匿名结构。可以在另一个结构或联合中定义匿名结构。下面是一个示例:
structtest{
//Anonymousstructure
struct{
floatf;
chara;
};
}test_var;要访问上述匿名结构的成员,我们可以使用成员运算符(。)。以下代码将1.2分配给成员f。
test_var.f=1.2;
由于该结构是匿名的,因此我们仅使用一次成员运算符访问其成员。如果它的名称如下面的示例所示,我们将不得不两次使用成员运算符:
structtest{
struct{
floatf;
chara;
}nested;
}test_var;在这种情况下,我们应该使用以下代码将1.2分配给f:
test_var.nested.f=1.2;
如您所见,匿名结构可以使代码更具可读性,而又不那么冗长。也可以将typedef关键字与结构一起使用以定义新的数据类型。我们将在以后的文章中介绍这种方法。
结构的内存布局
C标准保证结构的成员将按照在结构中声明成员的顺序一个接一个地位于内存中。第一个成员的内存地址将与结构本身的地址相同。考虑以下示例:
将分配四个存储位置来存储变量c,d,e和f。内存位置的顺序将与声明成员的顺序匹配:c的位置将具有最低的地址,然后是d,e,最后出现f。我们需要多少字节来存储此结构?考虑到变量的大小,我们知道至少需要1 + 4 + 1 + 2 = 8个字节来存储此结构。但是,如果我们将此代码编译为32位计算机,则会令人惊讶地观察到MyStruct的大小是12个字节而不是8个字节!这是由于以下事实:编译器在为结构的不同成员分配内存时具有某些约束。例如,一个32位整数只能存储在其地址可被4整除的内存位置。实施这种约束,称为数据对齐要求,以使处理器更有效地访问变量。数据对齐会导致内存布局浪费一些空间(或填充)。仅在这里介绍该主题。我们将在本系列的下一篇文章中详细介绍。
图3.数据对齐会导致内存布局中的空间浪费(或填充)。
意识到数据对齐要求后,我们也许可以重新排列结构中成员的顺序,并使内存使用效率更高。例如,如果我们按如下所示重写上述结构,则在32位计算机上,其大小将减小为8个字节。
structTest2{
uint32_td;
uint16_tf;
uint8_tc;
uint8_te;
}MyStruct;对于受内存限制的嵌入式系统,将数据对象的大小从12个字节减少到8个字节可节省大量资金,尤其是当程序需要许多此类数据对象时。
下一篇文章将更详细地讨论数据对齐,并研究在嵌入式系统中使用结构的一些示例。
概要
结构允许我们定义依赖于应用程序的数据对象,这些对象可以将不同类型的各个变量相互关联。这导致了一种有效的数据处理方法。
称为数据结构的专用结构可用于各种应用程序,例如两个嵌入式系统之间的消息传递以及将从传感器收集的数据存储在不连续的内存位置中。
当我们需要访问存储器映射的微控制器外设的寄存器时,结构很有用。
通过重新排列结构中成员的顺序,我们也许可以使内存使用效率更高。
-
C语言
+关注
关注
180文章
7604浏览量
136676 -
结构体数据
+关注
关注
0文章
3浏览量
5958
发布评论请先 登录
相关推荐
新手怎么学嵌入式?
一文了解嵌入式软件开发的对象





 工商网监
工商网监
评论