 IPC多高才算高呢?
IPC多高才算高呢?
IPC的意义
一般来说IPC是越高越好, 这意味着单位时间执行了更多的指令, 通过观测IPC可以一定程度上了解软件的执行效率. 但是多高才算高呢? 这并没有标准答案, 它需要有基线进行对比, 有的代码逻辑就决定了不可能有太高的IPC, 比如存在大量的跳转逻辑或者随机访问, 当然这可能就是需要优化的地方.
首先来看一个简单的测试程序:
# cat s1.c void main() { unsigned long sum = 0, i = 0; for (i = 0; i < 0x10000000; i += 1) { sum += i; } } $ gcc -O0 s1.c -o s1 $ perf stat ./s1 2,145,851,708 cycles # 2.284 GHz (83.30%) 1,606,130,789 stalled-cycles-frontend # 74.85% frontend cycles idle (83.30%) 180,401,278 stalled-cycles-backend # 8.41% backend cycles idle (66.78%) 1,347,161,466 instructions # 0.63 insns per cycle
一种比较通用的优化方法就是把for循环展开(unroll), 再来看看效果:
$ cat s2.c void main() { unsigned long sum = 0, a = 0, b = 0, c = 0, d = 0, i = 0; for (i = 0; i < 0x10000000; i += 4) { a += i; b += i + 1; c += i + 2; d += i + 3; } sum = a + b + c + d; } $ perf stat ./s2 632,338,513 cycles # 2.281 GHz (83.40%) 229,407,430 stalled-cycles-frontend # 36.28% frontend cycles idle (83.41%) 7,151,154 stalled-cycles-backend # 1.13% backend cycles idle (66.83%) 1,343,577,403 instructions # 2.12 insns per cycle
可以看到, 这个优化效果非常好, IPC从0.63上升到了2.12, 同时CPU执行cycles也相应地从2,145,851,708下降到了632,338,513. 不过指令条数基本上没有变化, 如果再看汇编代码, 就会发现-O0编译出来的代码还有很多访存, 那么我们现在稍微修改一下, 使用register来存放变量i:
$ cat s3.c void main() { unsigned long sum = 0, a = 0, b = 0, c = 0, d = 0; register unsigned long i = 0; for (i = 0; i < 0x10000000; i += 4) { a += i; b += i + 1; c += i + 2; d += i + 3; } sum = a + b + c + d; } $ gcc -O0 s3.c -o s3 $ perf stat ./s3 540,912,972 cycles # 2.284 GHz (83.12%) 270,437,339 stalled-cycles-frontend # 50.00% frontend cycles idle (83.48%) 5,344,535 stalled-cycles-backend # 0.99% backend cycles idle (67.08%) 1,074,783,046 instructions # 1.99 insns per cycle
这个优化同样有效, CPU执行时间从632,338,513 cycles减少到540,912,972, 不过IPC却从2.12减少到了1.99, 性能提升主要来源于指令条数的较少. 再进一步, 所有变量都使用register:
$ cat s4.c void main() { register unsigned long sum = 0, a = 0, b = 0, c = 0, d = 0; register unsigned long i = 0; for (i = 0; i < 0x10000000; i += 4) { a += i; b += i + 1; c += i + 2; d += i + 3; } sum = a + b + c + d; } $ gcc -O0 s4.c -o s4 $ perf stat ./s4 203,071,748 cycles # 2.284 GHz (83.14%) 68,298,093 stalled-cycles-frontend # 33.63% frontend cycles idle (83.15%) 1,056,363 stalled-cycles-backend # 0.52% backend cycles idle (67.05%) 598,151,024 instructions # 2.95 insns per cycle
这个优化更加明显, CPU执行时间优化了一大半, 这来源于指令条数大幅减少了40%, 同时IPC从1.99上升到了2.95. 到这里我们已经拿到了一个相对满意的结果, 是否还有优化的空间我们可以一起思考.
那么IPC到底说明了什么? 它从某一个侧面说明了CPU的执行效率, 却也不是全部. 想要提高应用的效率, 注意不是CPU的效率, 简单地说无非两点:
没必要的事情不做
必须做的事情做得更高效, 这个是IPC可以发挥的地方
指令并发
上面已经看到, IPC是可以大于1的. 一般的理解是CPU通过pipeline提高了throughput, 但一条流水线每个cycle还是只能完成一条指令, 这种情况下IPC是<=1的. 那么是否可以推测出一个CPU上其实有多条流水线? 答案是肯定的. 不过多流水其实有不同的实现方法, 主要是VLIW (Very Long Instruction Word) 和SuperScalar, VLIW通过compiler在编译时静态完成多指令的调度, 而SuperScalar则是在运行时调度多指令. 目前稍微好点的CPU使用的都是SuperScalar, Intel的CPU也不例外.
具体的信息可以参考Instruction Level Parallelism
飞得更高
既然IPC可以接近3, 那么还能不能再高点? 我们看2个测试, alu.c 和 nop.c, 测试运行在Xeon E5-2682 v4 (Broadwell架构).
$cat alu.c void main() { while(1) { __asm__ ( "movq $0x0,%rax " "movq $0xa,%rbx " "andq $0x12345678,%rbx " "orq $0x12345678,%rbx " "shlq $0x2,%rbx " "addq %rbx,%rax " "subq $0x14,%rax " "movq %rax,%rcx"); } } $gcc alu.c -o alu $perf stat ./alu 6,812,447,936 instructions # 3.84 insns per cycle $cat nop.c void main() { while(1) { __asm__ ("nop " ... // 总共128个nop操作 "nop"); } } $gcc nop.c -o nop 8,577,428,850 instructions # 3.66 insns per cycle
通过这2个测试可以看到, IPC甚至可以接近4, 同时也产生了几个疑问:
3.84应该不是极限, 至少应该是个整数吧?
alu比nop还高, 这似乎不符合常理?
alu中的很多指令有依赖关系, 怎么达到高并发的?
首先来看第一个问题, 为什么是3.84, 而不是4或者5呢? 这里面第一个需要关注的地方就是while(1), 相对于其他move/and/or/shl/sub指令, 它是一个branch指令. CPU对branch的支持肯定会复杂一点, 碰到branch指令还会prefetch之后的指令吗? 如果branch taken了那之前的prefetch不就没用了? 另一个需要考虑的就是Broadwell的每个core里面只有4个ALU, 其中只有2个ALU能够执行跳转指令, 并且每个cycle最多能够dispatch 4个micro ops. 而alu.c中每个循环是8条指令, 加上跳转指令本身有9条指令, 看起来不是最好的情况. 那么在循环中减少一条指令会怎么样:
$sed /orq/d alu.c > alu8.c $gcc alu8.c -o alu8 $perf stat ./alu8 10,276,581,049 instructions # 3.99 insns per cycle
可以看到IPC已经达到3.99, 非常接近4了. 如果把每个循环的指令条数修改为12 (包括跳转指令), 16, 20等都可以验证IPC在3.99左右, 反之如果是13, 14就差一点. 唯一的例外来自于7, 它同样能达到3.99 (原因?), 再减少到6又差点.
这里使用了一个userspace读CPU PMU的工具likwid
$likwid-perfctr -g UOPS_ISSUED_CORE_STALL_CYCLES:PMC0,UOPS_ISSUED_CORE_TOTAL_CYCLES:PMC1,UOPS_EXECUTED_STALL_CYCLES:PMC2,UOPS_EXECUTED_TOTAL_CYCLES:PMC3 -t 1s -O -C 1 ./alu

根据上面的结果可见, stalled cycle并无明显区别, 因为只有当一个cycle中没有issue/execute任何一条指令的时候才计算, 对于这个测试用例是很少发生的. 测试发现event IDQ_UOPS_NOT_DELIVERED 和IPC的变化表现出相关性.Intel 64 and IA-32 Architectures Optimization Reference Manual, B.4.7.1 Understanding the Micro-op Delivery Rate
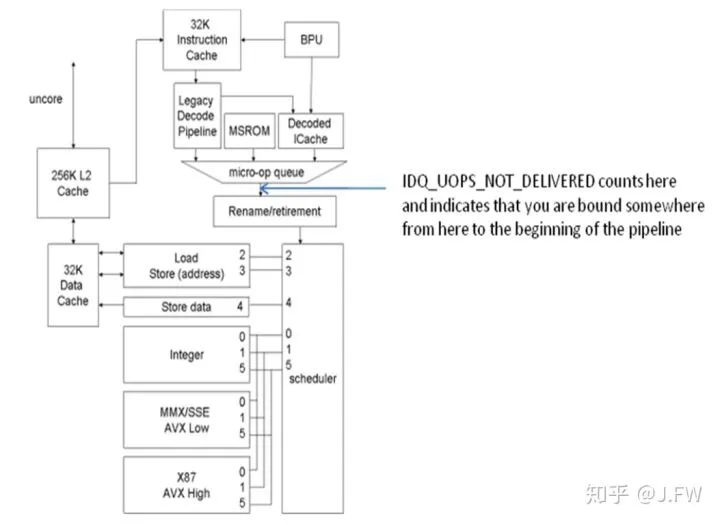
也就是说front end不能够及时把指令发给RAT (Resource Allocation Table), 这个通过stalled-cycle-front end是不一定能看出的. 那么一个无条件jmp指令怎么就能影响到front end, 并且还跟每个循环的指令数相关? 按理说所有的micro ops都已经在IDQ (Instruction Decode Queue)中, 并且LSD (Loop Stream Detector)应该完全能够cover住这几条指令. 具体原因暂时还不清楚, 如果知道这个了, 也许就有了另外一个问题的答案, 为什么是3.84而不是3.75或者别的呢?
现在来看第二个问题, 为什么alu比nop的IPC还要高呢? 上面已经分析过jmp指令的影响, 并且瓶颈点是在front end而不是在back end, nop和alu的指令并没什么区别. 所以需要控制的是一个循环的指令数, 把其修改为8, 则nop一样可以达到3.99的IPC.
第三个问题, CPU是怎么处理数据依赖的. 首先需要明确的是, 产生了数据依赖肯定会给并发带来影响, 后面的指令必须等待前面指令的结果. 这里关键的一点是虽然在一个循环里面没有独立的四条指令, 但这并不影响2个甚至多个循环的并发性. 也就是说, 即使有跳转指令, 后续的指令依然可以乱序执行. 但两次循环之间不还是使用相同的寄存器从而产生依赖吗? 是的, 如果它们最终使用的是相同的寄存器. 不过对于CPU来说, 汇编指令中的rax, rbx等不过是逻辑寄存器, 运行时还要进行一次rename的过程, 这个过程把一些false dependency给解决掉. 比如wiki上的例子. 而且CPU内部物理寄存器的个数是远远大于可以rename的逻辑寄存器个数的, 一般来说足够解决在流水线及乱序情况下的false dependency.
CPU架构
再继续探讨IPC之前有必要先了解一下CPU的体系结构, 以Haswell (和Broadwell同一个架构, 更小的制程) 为例:
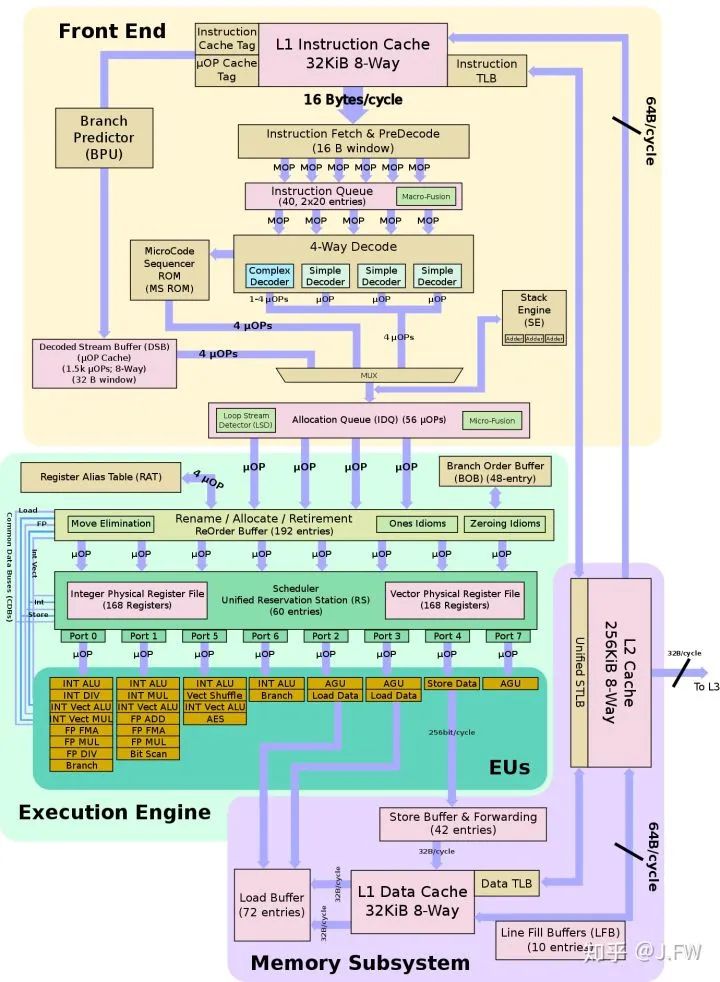
CPU是流水线工作的, 前半部分可以称为front end, 功能主要包括取指, 译码等, 在这个图中IDQ及其前面的部分就是front end. 译码其实是个很费时间的步骤, 因为x86是外表是CISC架构, 支持变长的指令, 内部其实更像RISC架构, 所以需要把这些宏指令(也就是汇编指令)转化为微指令(micro ops/uops). 对于Broadwell, IDQ的最大带宽是4 uops/cycle, Skylake的带宽可以到6 uops/cycle. 关于译码的作用, 可以参考A JOURNEY IN MODERN COMPUTER ARCHITECTURES
back end自然指的就是IDQ后面的部分. Broadwell (Skylake也一样) 的scheduler最大输入是4 uops/cycle. 考虑到有的指令比如nop, xor rax,rax等在rename阶段就结束, 并且这类指令的IPC同样只能到4 uops/cycle, 可以确定rename的带宽只有4 uops/cycle, 那是不是刚好说明最大IPC是4呢?
执行单元(port)总共有8个, 其中4个p0156能执行ALU操作, 注意能执行branch的只有2个p06. scheduler最多可以调度8 uops/cycle.
micro/macro fusion
如果没有fusion, 可以认为4 uops/cycle就是IPC的最大值, 并且前面的测试代码已经做到了.
micro fusion. 因为CPU的执行单元是类RISC, 所以一条instruction有可能需要拆成2条或者多条uops. 比如store, 就需要2条uops, 一个store address (上图中STA), 一个store data (STD). micro fusion把这2条uops合并成一个uops, 虽然在执行时又分成2个uops. 关于micro fusion的decoder的影响同样可以参考Decoding x86: From P6 to Core 2 - Part 2. 利用好micro fusion能提升程序的效率, 但micro fusion不会提升最大IPC.
macro fusion. 如果相邻的2条instruction符合某种条件, macro fusion会把它们合并成一个uops, 在执行的时候也不会再拆成2个. 很显然macro fusion是有可能提高max IPC的. 上面已经了解到, 整个CPU执行栈的瓶颈在rename阶段只能处理4个uops, 既然一个uops可以包含2条指令, 不就可以处理更多的instruction了吗? 答案是肯定的. macro fusion的条件主要包括:
第一条指令是CMP, TEST, ADD, SUB, AND, INC, DEC
第二条指令是conditional branch
天空在哪
上面macro fusion的讨论中已知1 uops可以包含2 instructions, 那是不是可以简单计算得到max IPC = 4 * 2? 上面已经说过, 8个port中只有2个是支持branch的, 而macro fusion中必须包含branch, 所以max IPC = 6. 还有一个问题是以后IPC还会不会涨, 为什么呢?
来自agner.org的一个例子:
#define ASM_TWO_MICRO_TWO_MACRO(in1, sum1, in2, sum2, max) __asm volatile ("1: " "add (%[IN1]), %[SUM1] " "cmp %[MAX], %[SUM1] " "jae 2f " "add (%[IN2]), %[SUM2] " "cmp %[MAX], %[SUM2] " "jb 1b " "2:" : [SUM1] "+&r" (sum1), [SUM2] "+&r" (sum2) : [IN1] "r" (in1), [IN2] "r" (in2), [MAX] "r" (max)) +----------------------------+---------+--------------+| Event | Counter | Core 1 |+----------------------------+---------+--------------+| Runtime (RDTSC) [s] | TSC | 4.038255e-01 || UOPS_ISSUED_ANY | PMC0 | 4000147000 || UOPS_EXECUTED_CORE | PMC1 | 6000580000 || UOPS_RETIRED_ALL | PMC2 | 6000100000 || BR_INST_RETIRED_NEAR_TAKEN | PMC3 | 1000001000 || INSTR_RETIRED_ANY | FIXC0 | 6000005000 || CPU_CLK_UNHALTED_CORE | FIXC1 | 1003127000 || CPU_CLK_UNHALTED_REF | FIXC2 | 1003129000 |+----------------------------+---------+--------------+
性能调试
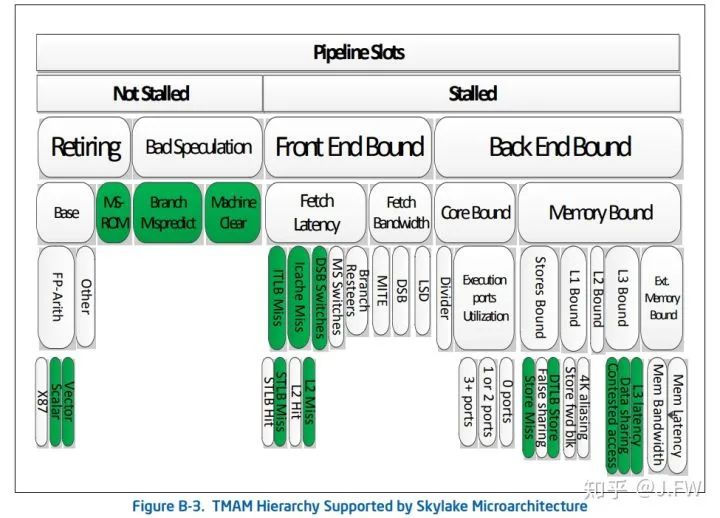
指令相关的性能调试大框架可以参考Intel优化手册的方法
本文目的
本文通过有意构造出来的理想代码, 从CPU角度分析IPC产生的原因. 虽然这些代码在生产环境中出现的可能性很小, 但是通过分析这些极端情况, 不只了解了CPU的极限在哪, 分析过程本身也很有意义. 那么我们是不是可以去尝试回答这些问题: 为什么超线程这么不给力? Xeon E5-2682相比E5-2630有哪些改进? CPU使用率都100%了还有提高空间吗? IPC还会增长吗?
本文作者:J.FW
原文标题:IPC到底能有多高
文章出处:【微信公众号:Linuxer】欢迎添加关注!文章转载请注明出处。
-
IPC
+关注
关注
3文章
352浏览量
51965
发布评论请先 登录
相关推荐
博泰车联网厦门制造基地顺利通过IPC QML审核
ipc系统的网络带宽需求分析
用opa657按照Datasheet里面的电路接好,输出输入波形都会有许多高频杂波,为什么?
IPC工控机有哪些技术特点?
ipc820工控机使用教程
IPC-2152 与 IPC-2221:哪种标准适合用于 PCB 热分析

第一次IPC摄像头测试开场了吗

请问在Allegro中,如和设置“临近网络距离(adjacency information)”,并导出IPC-D-356A呢?谢谢
HarmonyOS跨进程通信—IPC与RPC通信开发
IPC平台商的市场格局






 工商网监
工商网监
评论