 建立决策树的逻辑
建立决策树的逻辑
一个小故事
zenRRan二十出头了,到了婚配的年龄啦。又因为家是名门望族,所以一堆人抢着想来应聘配偶的职位。但是zenRRan比较挑剔,必须达到他的要求才能有机会成为他的另一半,要求为:
1. 性别女,非女性不要
于是刷刷刷走了一半人,剩下的全部为女性。
2.身高必须要在150-165cm
于是又走了一堆人,剩下的为160-165cm之间的女生。
3.性格要温柔贤惠
听到这些,又走了一些人,最后留下的极为最后的应聘候选人。
上述过程可以用树来表示:
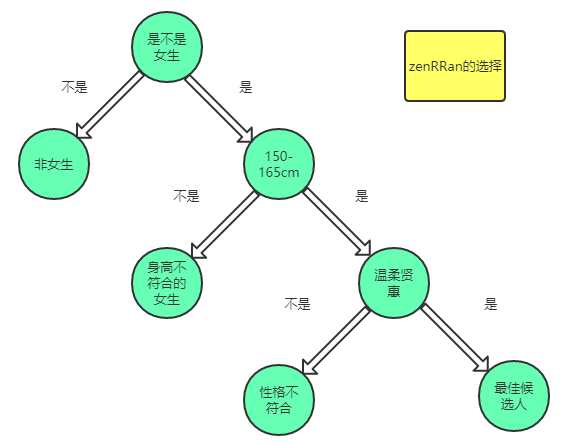
像上面的这样的二叉树状决策在我们生活中很常见,而这样的选择方法就是决策树。机器学习的方法就是通过平时生活中的点点滴滴经验转化而来的。
建立决策树的逻辑
正如上述树状图所示,我们最终会通过特征:
性别,身高,性格
得到了4种分类结果,都存在于叶子节点。
非女生,身高不符合的女生,身高符合性格不符合的女生,都符合的最佳候选人。
现在我们来回想下上面的建立决策的流程:
首先在一群给定数据(应聘者)中,我们先通过一个特征(性别)来进行二分类。当然选取这个特征也是根据实际情况而定的,比如zenRRan选取第一个条件为性别的原因是,来的男的太多了,比例占的有点大,所以先给他分成类放到一边,剩下的更加好分类而已。
然后,对叶子节点(那些还想继续分类的节点们)继续进行上述的流程。
那么怎么选取特征作为当前的分类依据呢?有两种方法:
信息熵和基尼系数。
信息熵
熵这个概念想必大家都不陌生,熵用来表示数据的确定性程度。研究一个词,就要从他的来源说起,熵,来自热动力学,表示原子或者一个事物的稳定程度,温度越高,原子越活跃,越不稳定;反而温度越低,就越稳定,越保持不动。所以慢慢的这个概念被用到各个方向,也就有了新的定义词汇,但是它的本意没变,就是稳定程度大小的表示。
那么在决策树里面,我们用的是一种熵,信息熵,来表示类别的稳定程度。
公式为:
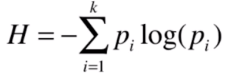
注:p为一个类的占比
什么意思呢?具体用数字表示下:
比如一个分类结果由三个类组成,占比为1/3 1/31/3,那么它们的信息熵为:
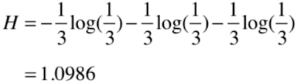
如果占比为1/10 2/10 7/10,那么它的信息熵为:
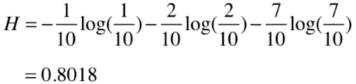
那再举一个极端情况,也就是我们想要得到的类,只包含一种情况,其他的比例为0,那么比如占比情况为:1 0 0,那么它的信息熵为:
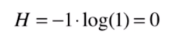
我们会发现一个分类结果里,里面的类别比例越是接近,信息熵也就越大,反之越是趋向于一个值,越是小,会达到0。
如果将所有的情况考虑在内的话,就能绘成一个图(为了好画,以该分好的类别里有两种事物为例):
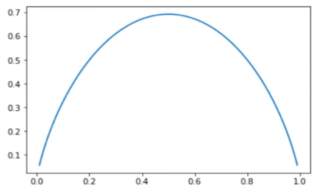
我们会发现,当占比为0.5的时候,也就是另一个事物的占比也是0.5的时候信息熵最高,当倾向于一个事物的时候,信息熵最小,无限接近并达到0。
为什么都占比一样的时候信息熵最大呢?也就是说最不稳定呢?因为当每个事物都占比一样的时候,一个小事物进来,不清楚它到底属于哪一类;如果只有一类事物或者一类事物居多数,那么也就比较明确该属于哪类,也就稳定,确定了。
那么怎么用呢?
我们通过计算机分类,因为有很多种分类情况,不是每一次分类都是直接将同一类分到一个类别里,而是将该分好的两个类的信息熵总和最小为依据,不断地通过暴力寻找最佳选择。然后递归进行对分好类的数据进行再分类。
基尼系数
基尼系数和信息熵在这里具有同样的性质。先看看它的公式:
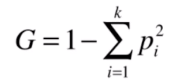
公式看不出什么特色之处,就继续用数字展示下:
比如依然是三分类,类别占比为1/3 1/3 1/3,基尼系数为:
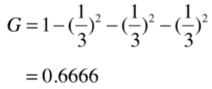
类别占比为1/10 2/10 7/10,基尼系数为:
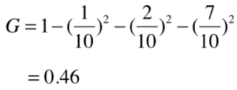
如果是极端情况下占比为1 0 0,那么基尼系数为;
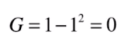
我们根据公式其实就能看出来,平方的函数为凸函数,而该公式在都相等的时候值最大。
代码实现
再重说下流程:
通过对每个特征进行尝试分类,记录当前分类最小的信息熵(或基尼系数)的特征为当前分类结果。
选取一些点,初始化数据:
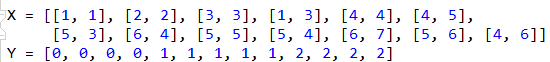
X为二维平面的数据点,Y为类别。
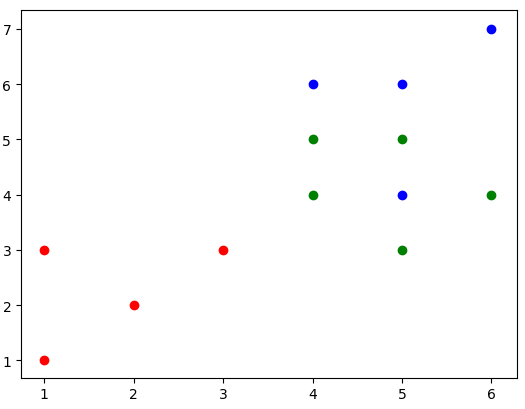
数据点分布情况:
信息熵函数:

基尼系数函数:

二者使用一个即可。
下面是一个分类核心的流程:
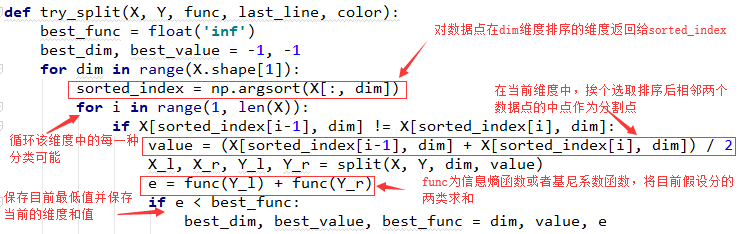
文字描述为:
对数据点的特征0维进行尝试分类,先按照0维数据排序,然后取每相邻的中点值,然后以0维该值分界线,处于分界线两侧的数据分别求信息熵(或基尼系数),如果比之前的小,这就保存该值和当前维度。然后选取第1维进行相同操作,最终的最小信息熵(或基尼系数)最小对应的值为本次分类的结果。
但是这个仅仅是一层分类,如果还子节点还有要分类的数据,继续上述操作即可。
分类代码:

分类效果流程图:
决策树第一层分类结果为:
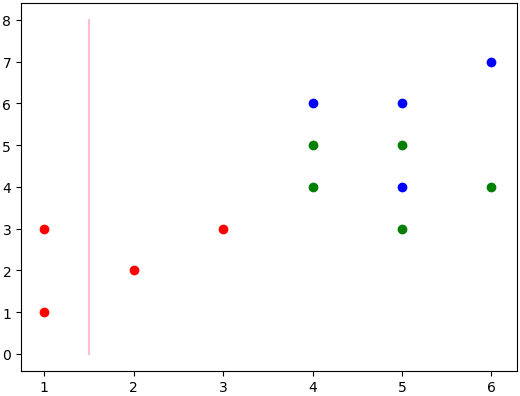
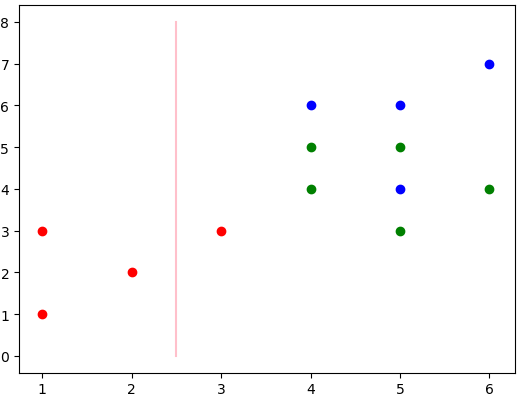
当前线为最佳值,1维的数据就是分过的,但是没有当前的值好,也就没显示。
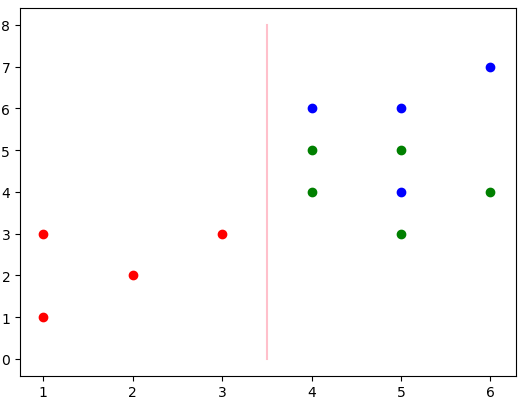
现在已经分出了两类,左边的红色和右边的绿色+蓝色。那么还要对上述的右边进行分类,获取该数据,并且继续进行分类,分类流程图为:
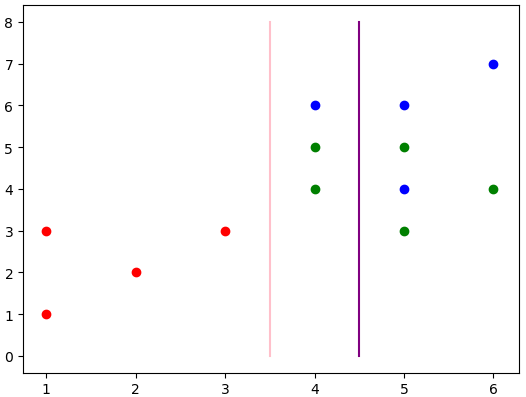
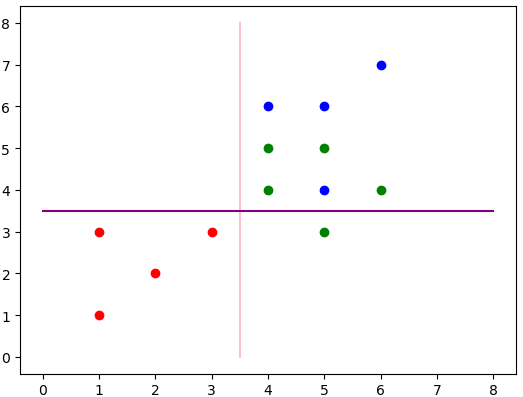
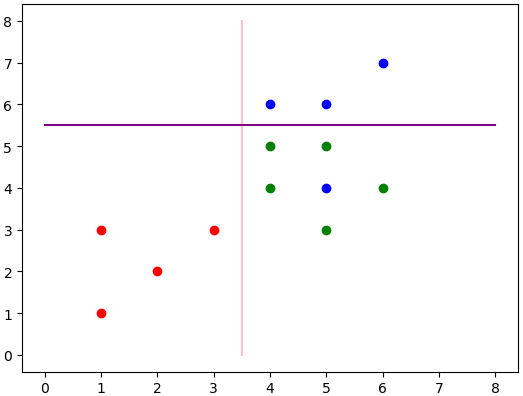
最终得出的分类结果为上述两条线。其中粉色为第一层分类,紫色为第二层分类。
批判性思维看决策树
看到上述的分类结果,其实你心里也想到了决策树的缺点了,就是分类总是横平竖直的,不能是曲线。
比如
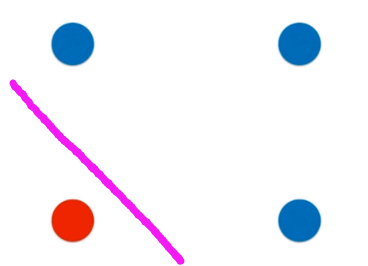
该四个数据的分类最佳理想条件下应该为上述紫色线条,但是决策树的结果为;
如果存在数据在:
明明应该属于蓝色点的,但是被划分到红色点里。
所以可以看出,决策树对数据的要求是是苛刻的。
另一个问题是,决策树的学习问题,从上述代码实现过程能够看出来,可以说是暴力求解了。
责任编辑:lq
-
二叉树
+关注
关注
0文章
74浏览量
12324 -
机器学习
+关注
关注
66文章
8406浏览量
132562 -
决策树
+关注
关注
3文章
96浏览量
13548
原文标题:【机器学习】决策树的理论与实践
文章出处:【微信号:zenRRan,微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
逻辑异或和逻辑或的比较分析
逻辑异或的定义和应用 逻辑异或与逻辑与的区别
简单认识逻辑电路的用途
LSM6DSV16X基于MLC智能笔动作识别(2)----MLC数据采集

什么是默克尔树(Merkle Tree)?如何计算默克尔根?
数字逻辑怎么把逻辑图画成电路图
数字系统的核心:逻辑门电路

机器学习算法原理详解
原理图设计里两颗重要的树(国产EDA)
崔东树:进口车增量助力消费增长,年内潜力巨大
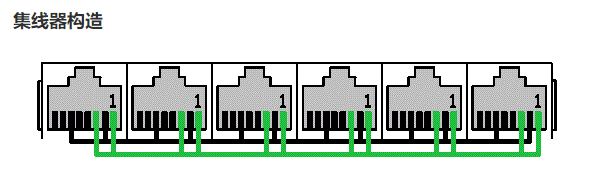
集线器是什么?集线器内部构造
什么是随机森林?随机森林的工作原理





 工商网监
工商网监
评论