 图神经网络在处理基于图数据问题方面取得了巨大的成功
图神经网络在处理基于图数据问题方面取得了巨大的成功
1 引言 图神经网络在处理基于图数据问题方面取得了巨大的成功,受到了广泛的关注和应用。GNNs通常是基于消息传递的方式设计的,本质思想即迭代地聚合邻居信息,而经过次的迭代后, 层GNNs能够捕获节点的局部结构,学习来自跳邻居的信息。因此更深层的GNN就能够访问更多的邻居信息,学习与建模远距离的节点关系,从而获得更好的表达能力与性能。而在实际在做深层GNN操作时,往往会面临着两类问题:1. 随着层数的增加,GNNs的性能会大幅下降;2. 随着层数的增加,利用GNNs进行训练与推断时需要的计算量会指数上升。对于第一个问题来说,现有的很多工作分析出深层GNNs性能下降的原因是受到了过平滑问题的影响,并提出了缓解过平滑的解决方案;而对于第二个问题来说,设计方案模拟深层GNNs的表现能力并减少GNNs的计算消耗也成了亟待解决的需求,比如用于实时系统的推断。针对这两个问题,本文将分别介绍两个在KDD 2020上的关于深度GNNs的最新工作。 第一个工作是Research Track的《Towards Deeper Graph Neural Networks》。该工作从另一个角度去解读深度图神经网络随着层数增加性能下降的问题,认为影响性能下降的主要原因是Transformation和Propagation两个过程的纠缠影响作用,并且基于分析结果设计了深度自适应图神经网络(Deep Adaptive Graph Neural Networks) 模型,能够有效地缓解深层模型的性能快速下降问题。 第二个工作是Research Track的《TinyGNN: Learning Efficient Graph Neural Networks》。该工作尝试训练small GNN(浅层)去模拟Deep GNN(深层)的表达能力和表现效果,致力于应用在实时系统推断等对推断速度有较高要求的场景。 2 Towards Deeper Graph Neural Networks 2.1 引言 1层的GCN只考虑了1跳邻居的信息,而当使用多层的图卷积操作扩大GCN的接受域之后,性能也会大幅下降。已有的一些工作[1,2]将这个性能大幅下降的原因归根于图神经网络的过平滑问题(over-smoothing)。然而这篇文章保持一个不同的观点,并且从另一个角度去解读深度图神经网络性能下降的问题。这篇文章认为影响其性能快速下降的主要因素是表示变换(Transformation)和传播(propagation)的纠缠作用,过平滑问题只有在使用了非常大的接受域,也就是叠加非常多层的时候才会影响图神经网络的表现效果。在进行了理论和实验分析的基础上,该文章提出了深度自适应图形神经网络的设计方案。代码链接: https://github.com/mengliu1998/DeeperGNN 2.2实验与理论分析 2.2.1 图卷积操作 通常图卷积操作遵循一种邻居聚合(或消息传递)的方式,通过传播其邻域的表示并在此之后进行变化以学习节点表示。第层的操作一般可以描述为:
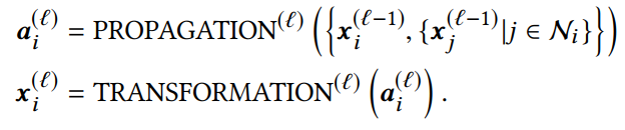
2.2.2 平滑度的定量度量 平滑度是反映节点表示相似程度的度量标准。通常两个节点的欧氏距离值越小,两个节点表示的相似性越高。本文作者提出了一种计算整张图平滑度的指标:
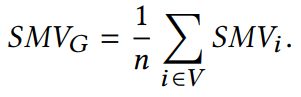
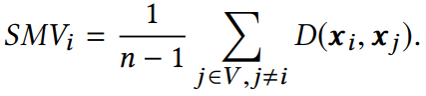
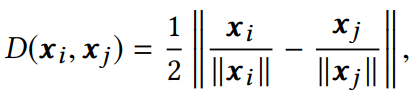
它与图中节点表示的整体平滑度呈负相关,即越小,图的平滑度越大。 2.2.3 深度GNN性能下降的原因 在评价指标的基础上,作者对GCN在cora数据集上进行节点分类实验的准确率、可视化以及指标数值的变化情况进行了统计,结果如下:

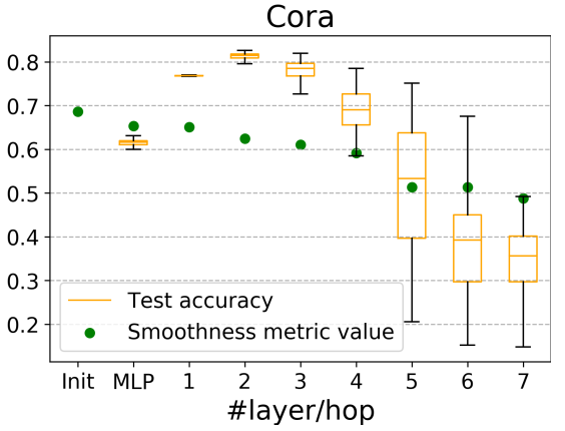
并给出质疑over-smoothing的两点原因:(1) 过平滑问题仅会发生在节点表示传播很多层之后,而实验中cora的分类结果在10层之内就大幅下降。(2)评价指标的值与初始相比只有轻微下降,证明平滑程度只有一定的上升,而不足以导致过平滑。 而作者进一步指出,是转换(Transformation)和传播(propagation)的纠缠作用严重损害了深度图神经网络的性能。并且为了验证该假设,作者将两个过程分解出来,设计了如下的一个简单模型:
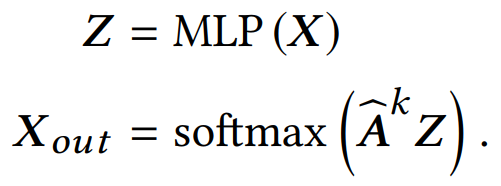
并同样给出在cora上的实验结果:
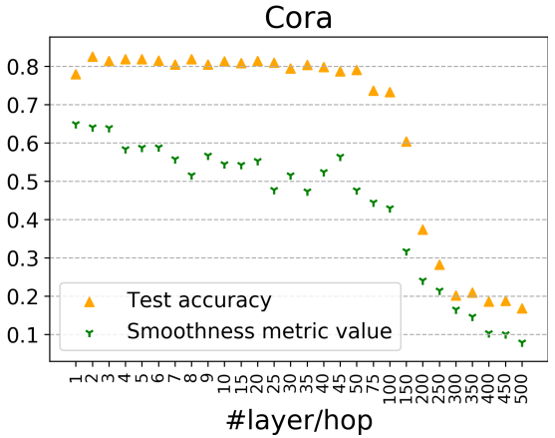

当两个过程分解后,50层内的GCN准确率基本能够在80%左右,当层数达到100+后才会陆续下降,对应的值也在300层以后变得很低,说明此时网络受到过平滑的影响。以上两个实验说明了在GNN受过平滑影响之前,转换(Transformation)和传播(propagation)的纠缠作用确实会损害深度图神经网络的性能,导致性能大幅下降。也证实了解耦转换和传播可以帮助构建更深层次的模型,从而利用更大的可接受域来学习更多的信息。 2.2.4 理论证明 经过变换与传播的解耦,作者的理论分析可以更严格且温和地描述过平滑问题。在本节中,作者严格描述两种典型传播机制的过度平滑问题,并推导出当层数趋近于无穷时,两种(, 的收敛情况。并证明该种传播模式是线性不可分的,利用它们作为传播机制将产生难以区分表征,从而导致over-smoothing问题。 2.3 模型
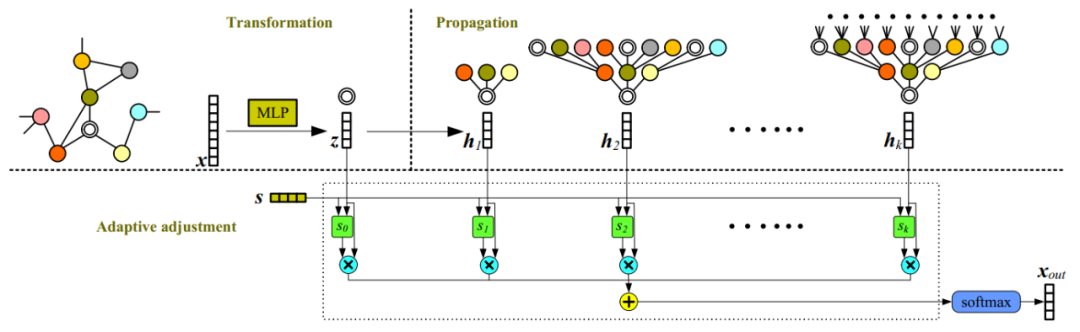
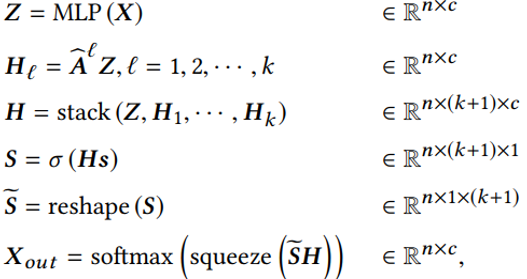
主要思想是将节点表示的变换与传播过程解耦,并同时进行至层传播,最后利用学得的融合权重向量做一个自适应调整融合。 2.4 实验
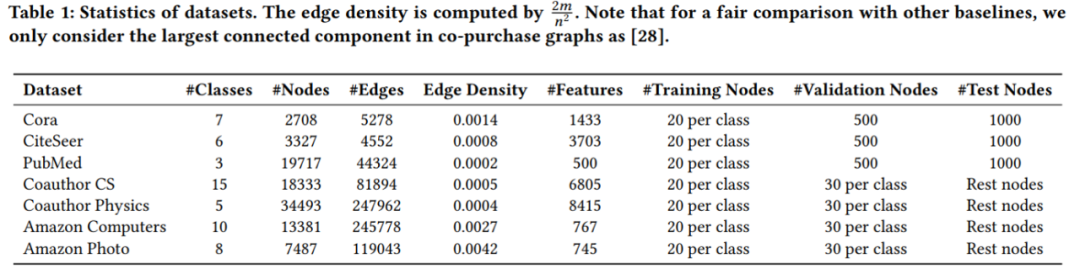
实验数据集
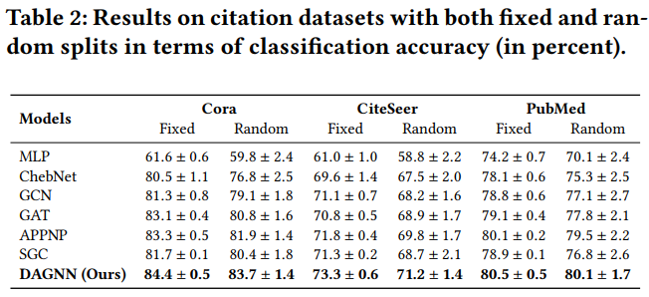
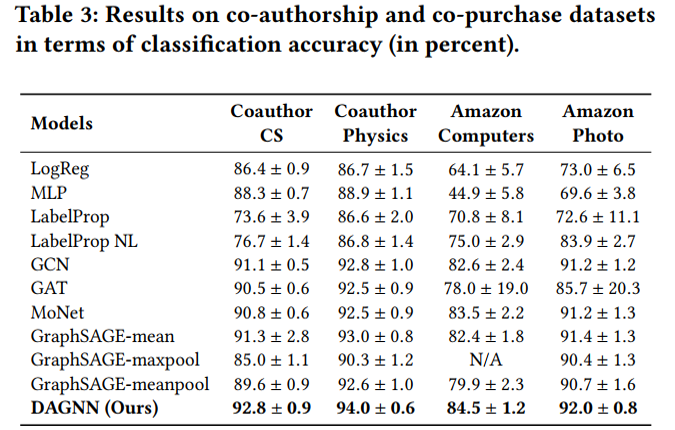
节点分类实验结果
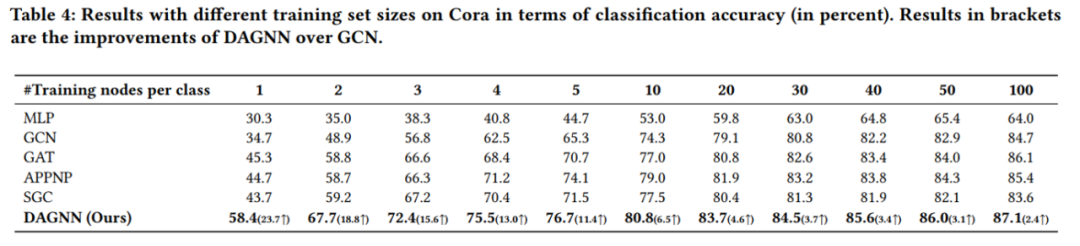
cora数据集上不同训练集比例的分类准确率 值得分析的有以下两点: (1)为什么低label rate的DAGNN表现要好?这些比较可观的改进主要归功于DAGNN的优势: 通过消除表示转换和传播的纠缠,同时扩展接受域的范围,使得利用信息更丰富。 (2)和APPNP SGC的区别是什么?APPNP和SGC实际上都解耦了转换和传播,并且APPNP也扩展了k阶接受域。DAGNN比APPNP好,是因为设计了自适应调整每个节点来自不同接收域的信息权重。
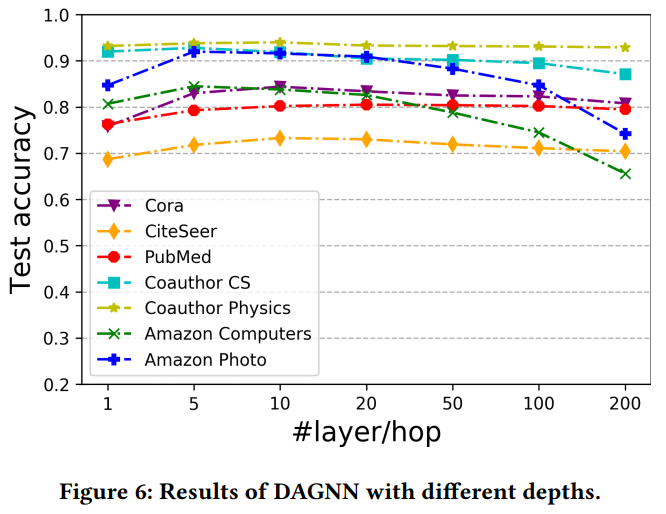
DAGNN在不同数据集上随层数变化的表现 3 TinyGNN: Learning Efficient Graph Neural Networks 3.1 引言 经过k次迭代后,k层GNN可以捕获来自k-hop节点结构信息。通过这种方式,一个更深层的GNN就有获取更多邻居信息的能力,从而取得更好的性能。举例来说,下图随着GAT层数的增加,两个数据集的分类准确率都有大幅提升。
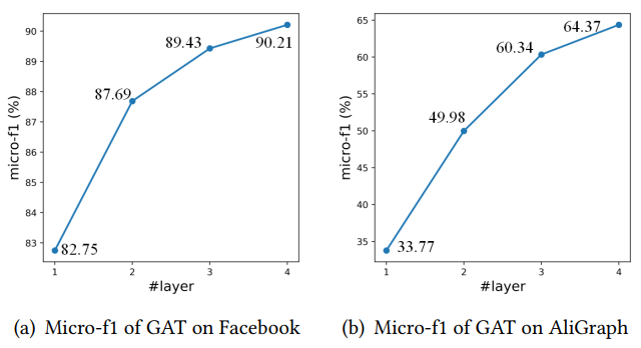
而相对应的,当GNN进一步扩展层数时,邻域的指数扩增会导致GNNs模型需要大量的训练和推理计算消耗。这使得许多应用程序(如实时系统)无法使用更深层的GNN作为解决方案。举例来说,同样的两个数据,4层GAT的计算时间以指数级增长,导致计算消耗十分巨大。
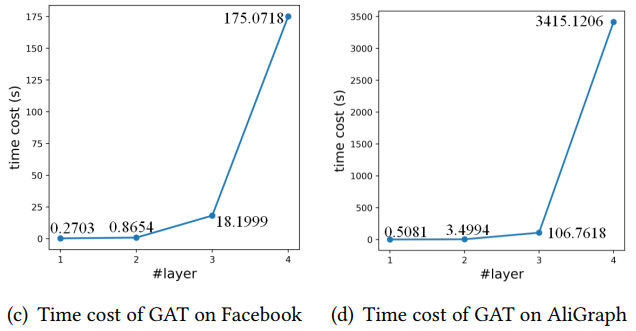
因此这里就存在着一个困境,即采用深层的GNN就越容易取得高性能,但是从效率的角度又往往倾向于开发一个小而推断迅速的GNN。但是较小的GNN与较深的GNN之间存在较大的邻域信息差距,这也是需要考虑的。因此这篇文章旨在训练一个较小的GNN,既能很好地刻画了局部结构信息,与较深的GNN相比可以获得相似性能,同时也能够进行快速的推断。总结来说,贡献如下: (1)提出了一种小型、高效的TinyGNN,能够在短时间内实现推断出高性能的节点表示。 (2)利用对等感知模块(PAM)和邻居蒸馏策略(NDS),以显式和隐式两种方式对局部结构建模,并解决小GNN和较深GNN之间的邻居信息差距。 (3)大量的实验结果表明,TinyGNN可以实现与更深层次的GNN相似甚至更好的性能,并且在实验数据集上,推理过程能够有7.73到126.59倍的提速。 3.2 模型 3.2.1 对等感知模块 对等节点(peer nodes)指的是同一层GNN从同一个点源点采样出的所有邻居集合,在下图(b)用相同的颜色表示。对等节点之间没有通信,所有对等节点都能够通过上层节点在两跳内相连。大量的对等节点是邻居,来自底层的邻居信息可以被对等节点直接配置。
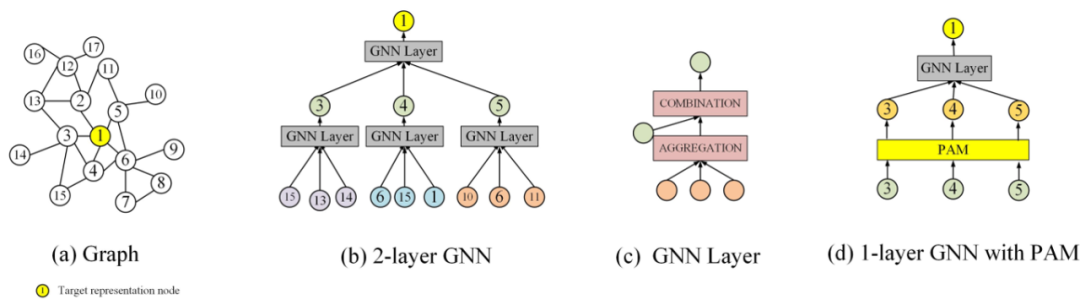
PAM建模对等节点的方式如下,以两个节点隐层表示的相似度作为融合权重。PAM能够帮助探索同一层中的节点之间的新关系,并帮助建模较小的GNN从而避免由较低层的邻居迭代聚集而导致的大量计算。
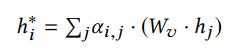
PAM可以被用于任何图网络结构中,作为一个基础的模块,1层GNN+1层PAM的计算量要小于两层GNN。 3.2.2 邻居蒸馏策略 作者利用知识蒸馏设计了邻居信息蒸馏方案,teacher GNN是深层模型,能够建模更广泛的邻域。而student GNN采用浅层模型,能够有更快的推断速度。并且利用teacher GNN 教student GNN隐式地捕捉全局深层结构信息,使得student GNN有深层GNN的表现效果。
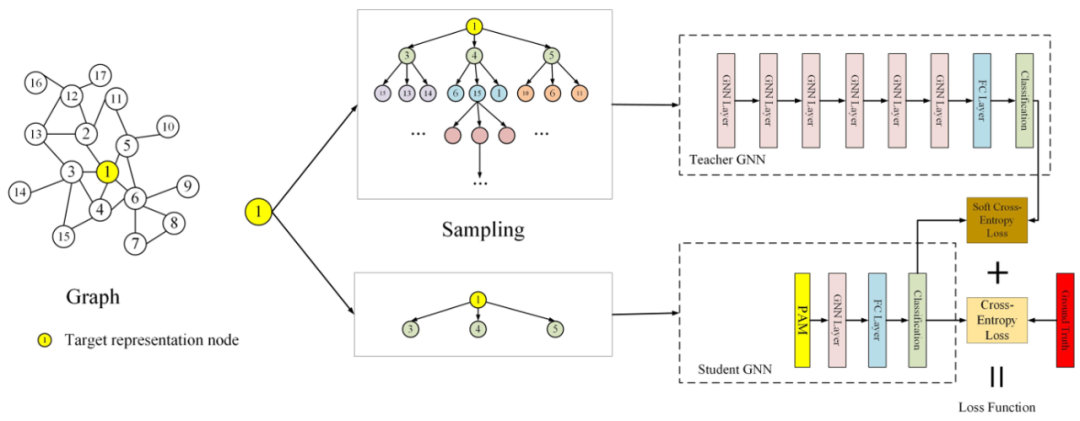
teacher GNN的损失函数:
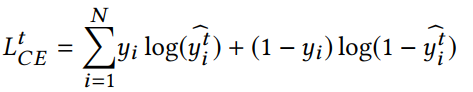
student GNN的损失函数,同时利用来自teacher网络的软标签和真实标签进行学习,T表示蒸馏温度。
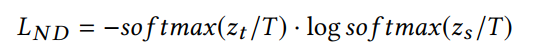
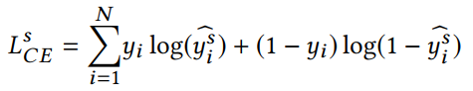
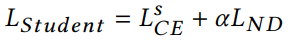
3.3 实验
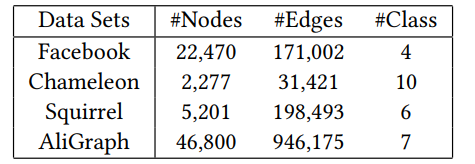
实验数据集
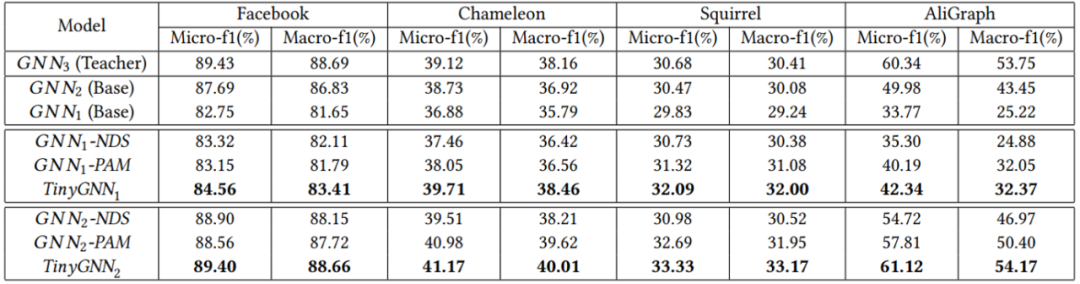
节点分类实验结果
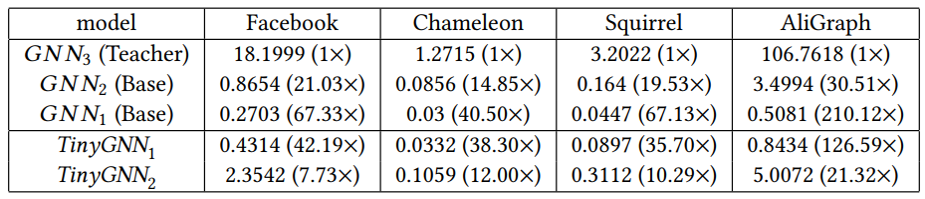
速度提升情况
-
神经网络
+关注
关注
42文章
4762浏览量
100534 -
数据集
+关注
关注
4文章
1205浏览量
24640 -
GNN
+关注
关注
1文章
31浏览量
6328
原文标题:【KDD20】深度图神经网络专题
文章出处:【微信号:zenRRan,微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐





 工商网监
工商网监
评论