 发展方兴未艾的先进封装技术
发展方兴未艾的先进封装技术
以《战略绪论》一书闻名的近代法国战略大师薄富尔曾说:「战略的要义是『预防』而非『治疗』,『未来和准备』比『现在和执行』更重要。」半导体业界亦同,当摩尔定律所预言的制程微缩曲线开始钝化,将不同制程性质的芯片,透过多芯片封装包在一起,以最短的时程推出符合市场需求的产品,就成为重要性持续水涨船高的技术显学。 而这些先进芯片封装也成为超级电脑和人工智能的必备武器。别的不提,光论nVidia 和AMD 的高效能运算专用GPU、Google 第二代TPU、无数「人工智能芯片」,就处处可见HBM 记忆体的存在。
毕竟天底下没有面面俱到的半导体制程,观察到先进制程晶圆厂每隔4 年成本倍增的「摩尔第二定律」,也突显了电晶体单位成本越来越高的残酷现实。AMD 处理器从7 纳米制程开始全面性「Chiplet 化」,将7 纳米制程的CPU 核心和12 纳米制程的I/O 记忆体控制器分而治之,实乃不得不然。
发展方兴未艾的先进封装技术
也因此,无论台积电还是英特尔,无不拼命加码,相关产品也如雨后春笋一个个冒出头来,而AMD 更在未来产品计画,大剌剌写着「融合2.5D 与3D 的X3D 封装」(虽然大概也是直接沿用台积电的现有技术),以达成超过时下产品十倍的记忆体频宽密度。
稍微替各位复习一下什么是「2.5D」封装,台积电拥有超过60 个实际导入案例的CoWos(Chip-on-Wafer-on-Substrate)算是这领域最为知名的技术,包含近期夺下超级电脑Top500 榜首的Fujitsu A64FX。英特尔用自家EMIB(Embedded Multi-Die Interconnect Bridge)将Kaby Lake 处理器与AMD Vega 绘图核心「送作堆」的Kaby Lake-G,也曾是轰动一时的热门话题。
有别于「2D」的SiP(System-in-Package),2.5D 封装在SiP 基板和芯片之间,插入了矽中介层(Silicon Interposer),透过矽穿孔(TSV,Through-Silicon Via)连接上下的金属层,克服SiP 基板(像多层走线印刷电路板)难以实做高密度布线而限制芯片数量的困难。
「叠叠乐」的3D 封装就不难理解了,台积电就靠着可减少30% 的封装厚度InFO(Integrated Fan-Out),在iPhone 7 的A10 处理器订单争夺战击败三星,终结了消费者购买iPhone 6S 还得担心拿到三星版A9 的尴尬处境(笔者不幸曾是受害者之一)。但3D 封装的散热手段与热量管理,也是明摆在半导体产业界的艰巨挑战。
英特尔相对应的3D 封装技术则为Foveros。最近正式发表、代号Lakefield 的「混合式x86 架构处理器」,堆叠了「1 大4 小核心」的10 纳米制程(代号P1274)运算芯片、22 纳米制程(代号P1222)系统I/O 芯片和PoP(Package-on-Package)封装的记忆体,待机耗电量仅2mW。
英特尔2019 年7 月公布的Co-EMIB,用2.5D 的EMIB 连接多个3D 的Foveros 封装,「整合成具备更多功能」的单一芯片。为EMIB 概念延伸的ODI(Omni-Directional Interconnect)则用来填补EMIB 与Foveros 之间的鸿沟,为封装内众多裸晶连接提供更高灵活性,细节在此不论。
连接封装内多颗裸晶之间的汇流排也是不可或缺的技术。 英特尔在2017 年将EMIB 连接裸晶的「矽桥」(Silicon Bridge)正式命名为「先进介面汇流排」(AIB,Advanced Interface Bus)并公开免费授权,2018 年将AIB 捐赠给美国国防先进研究计划署(DARPA),当作免专利费的裸晶互连标准,MDIO(Multi-Die I/O)则是AIB 的下一代。台积电相对应技术则为LIPINCON(Low-voltage-INPackage-INterCONnect),规格与英特尔互有长短。
超级电脑用的系统单芯片并非IBM 和Fujitsu 的专利
长期关心ARM 指令集相容处理器与超级电脑的读者,想必对先前采用Fujitsu A64FX 处理器打造的日本理化学研究所的「富岳」并不陌生。这颗台积电7 纳米制程并CoWoS 2.5D 封装4 颗8GB HBM2 记忆体的产物,堪称当代最具代表性的「超级电脑专用系统单芯片」,让人不得不想起十几年前的IBM BlueGene /L。
曾在21 世纪初期靠着「地球模拟器」(Earth Simulator)独领风骚两年多的NEC,其SX 向量处理器的最新成员SX-Aurora TSUBASA,也是台积电16 纳米制程、2.5D 封装6 颗8GB HBM2 记忆体的超级电脑心脏。
而英特尔的Xeon Phi 系列更是知名代表,透过2.5D 封装包了8 颗2GB MCDRAM(Multi-Channel DRAM),可设定为快取记忆体、主记忆体或混合两者之用。虽然Xeon Phi 家族两年前惨遭腰斩,中断自从Larrabee 以来的「超级多核心x86」路线,英特尔决定整个砍掉重练,一步一脚印重头打造「传统GPU」当作未来高效能运算与人工智能应用的基础,但异质多芯片封装的重要性仍不减反增,最起码被英特尔从AMD 挖角、主导GPU 发展的Raja Koduri,自己是这样讲的,也没什么怀疑的空间。
不过AMD 也并未缺席,并看似有后来居上的气势,而且这并非突发奇想,早在2010 年之前,就开始进行长期研究,至今超过十年,并「很有可能」以EHP(Exascale Heterogenous Processor)之名开花结果,融合2.5D 与3D 封装的X3D 则是达成EHP 的关键。
Exa 意指Peta 的1 千倍,也是近年来超级电脑的下一个竞争指标,像预定采用AMD Zen 2 世代EPYC 处理器的美国国家核能安全管理局El Capitan 超级电脑,理论运算效能就超过2ExaFlops。
AMD 自从2007 年购并ATI 之后,整合处理器与绘图核心的APU 之路,一直走得相当挣扎,迟迟难以找到适合的产品规格与市场定位,不是CPU 不够好、GPU 不够强、就是两者都不上不下,到了Zen 2 世代才算脱胎换骨。 这些年来,AMD 在超级电脑市场逐渐边缘化,今年6 月的Top500 只剩下10 台AMD CPU 和一台AMD GPU,更需要强力的新兵器,才能「突破英特尔和nVidia 的封锁」。身为「超级电脑APU」的EHP 就成为AMD 默默进行的新方向。
以加拿大ATI身分在2010年申请「藉由假矽穿孔替3D封装进行导热」(Dummy TSV To Improve Process Uniformity and Heat Dissipation)专利为起点,AMD一路累积了「记忆体运算的快取资料一致性」 (2016年)、「3D晶粒堆叠的热量管理」(2017年)、「拥有极致频宽与可延展性能耗比的GPU架构」(2017年)、「记忆体内运算的阵列」(2018年) 、「回圈脱离预测(2018年)以改善闲置模式的效率」到「混合CPU与GPU的动态记忆体管理」(2018年)等成果,确定了AMD在2015年的财务分析师大会透露的「伺服器专用APU」与当年7月IEEE Micro发表的「藉由异质运算实现百亿亿级运算」(Achieving Exascale Capabilities through Heterogeneous Computing)计画并不是玩假的,更何况现在AMD当家作主的还是一位以务实闻名的全球薪酬最高女性执行长。
根据已公开的资料,EHP 概略规格如下,但后面势必将随着技术演进而有更动:
32 个CPU 核心(当时是8 颗4 核心CCD)。
8 颗32 个GPU CU,总计256 CU 与16,384 个串流处理器(那时预定是GCN 第五代的Vega,看来将会推进到CDNA)。
8 块4GB HBM2 记忆体堆叠。
时脉1GHz 时,双倍浮点精确度理论效能为16TeraFlops,如十万颗组成超级电脑,就是1.6ExaFlops,预估耗电量为20MW。
AMD 在2015 年7 月IEEE Micro 专文,表示32 个CPU 核心、320 个时脉1GHz 的GPU CU(20,480 个串流处理器)、3TB/s 记忆体频宽、160W 功耗,是能耗比最好的组态,总之实际的产品一定会变。
EHP 和X3D 的技术资产会「推己及人」到Zen 3 世代EPYC 处理器「Milan」的可怕传言(像10 颗CCD 凑80 核心或塞HBM2 当L4 之类的),一直没有停过。
EHP 也有配置芯片封装以外的外部记忆体,像断电后资料不会消失的NVRAM(Non-Volatile RAM,如英特尔/Micro 的3D Xpoint 和发展中SST-MRAM 等)和「记忆体内运算」的PIM (Processing-In-Memory,记忆体内建位元运算电路),相关的动态记忆体管理与快取资料一致性,也是AMD 需要克服的技术门槛,至于软体环境的完备性,更将是AMD 能否追上nVidia 的最核心因素。
同场加映:nVidia 也没吃饱闲着
近来因「光明的未来前瞻性」而让公司市值一举超越英特尔的nVidia,在高效能运算、人工智能与自驾车等领域的优势地位几乎是牢不可破。除了帐面硬体规格,发展了十多年的CUDA 应用环境生态、远远超越英特尔和AMD 的GPU 虚拟化(这让客户使用AMD GPU 部署云端个人电脑的效益会明显不如nVidia,云端服务业者的虚拟GPU 亦同,比较一下可负荷用户端数量,就知道差别有多大了)和更多「不足外人道也」之处,才是支撑nVidia 股价的真正根基。 将话题拉回多芯片封装这件事,就算不论以「训练」为主的高阶GPU,nVidia 连「推论」用的芯片研究案都走向「多芯片封装延展性」。
但各位有没有想过一个更有趣的可能性:既然nVidia 高阶GPU 都这么大颗,干么不干脆「顺便」包一颗高效能的ARM(或RISC-V)指令集相容处理器,不再是英特尔、AMD 处理器的「附属品」,让GPU 变身成「可自行开机的超级电脑系统单芯片」? 事实上,nVidia GPU 内本来就有内建好几颗简称为Falcon(Fast Logic Controller)的微控制器,用来辅助GPU 运算处理,像支援影像图形解码到安全性机制,或减轻CPU 执行驱动程式的负担,如以前因为Windows 作业系统的延迟程序呼叫(DPC,Deferred Procedure Call)会逾时而不能进行的排程等。 2016 年,nVidia 先采用柏克莱大学的开源RISC-V 指令集相容处理器Rocket,开发出第一代Falcon 微控制器,2017 年第二代产品扩展到64 位元,并自行新增自定义的新指令。前述由27 颗封装而成的RC18 推论芯片,也是RISC-V 核心,每秒可执行128 兆次推论,功耗仅13.5W。 那么未来,假如nVidia 将「更多的工作」搬到GPU 内的RISC-V 核心,特别是驱动程式涉及大量GPU 底层机密资讯的「下面那一层」丢过去,或经由GPU 虚拟化掩盖起来,又会发生什么事?这件牵扯到另一个少人知悉的潜在需求了:来自官方的开源驱动程式。
弦外之音:GPU 驱动程式开源的冲击
台面上看不到或少人着墨的议题,举足轻重的程度往往远超乎看热闹外行人的想像。 无论超级电脑还是人工智能(尤其是人命关天的自动驾驶),基于安全性考量,芯片厂商的客户或多或少都希望检视所有程式码,理所当然包含驱动程式,这就是GPU 驱动程式开源之所以如此重要的主因。但偏偏这又是暗藏大量商业机密的黑盒子,要如何满足客户需求又不让机密外泄,大方释出「官方开源驱动程式」,就是nVidia、AMD 甚至即将「GPU 战线复归」的英特尔,已经面对很久的机会与挑战。 技术的发展跟着应用的需求走,这恐怕也将会注定AMD 靠着「超级电脑APU」反攻高效能运算市场的企图能否悲愿成就的锁钥。点到为止,剩下的就留给各位慢慢思考了。 本文转载自:半导体行业观察
原文标题:市场 | 芯片巨头决战先进封装
文章出处:【微信公众号:旺材芯片】欢迎添加关注!文章转载请注明出处。
责任编辑:haq
-
芯片
+关注
关注
459文章
51566浏览量
429752 -
封装
+关注
关注
127文章
8142浏览量
143848 -
gpu
+关注
关注
28文章
4830浏览量
129776 -
人工智能
+关注
关注
1800文章
48082浏览量
242143
原文标题:市场 | 芯片巨头决战先进封装
文章出处:【微信号:wc_ysj,微信公众号:旺材芯片】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
玻璃基芯片先进封装技术会替代Wafer先进封装技术吗
先进封装技术-19 HBM与3D封装仿真

先进封装成为AI时代的核心技术发展与创新
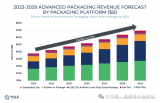
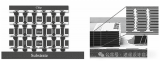
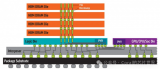
先进封装技术-7扇出型板级封装(FOPLP)
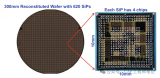
先进封装技术- 6扇出型晶圆级封装(FOWLP)

先进封装的技术趋势

先进封装技术的类型简述

晶圆微凸点技术在先进封装中的应用

先进封装技术综述






 工商网监
工商网监
评论