 如何用约43000张图片的数据集,来计算得出表情包的火爆程度排名
如何用约43000张图片的数据集,来计算得出表情包的火爆程度排名
电视节目的火爆程度可以根据尼尔森收视率排名(Neilsen ratings)来衡量,但是表情包呢?目前仍然没有什么独立指标能用以评估表情包(memes)的浏览人数,所以笔者自己摸索出了一些方法!
本文将说明如何用约43000张图片的数据集和五项数据科学原则,来计算得出表情包的火爆程度排名。
1. 明确定义估算对象
对文字信息的理解因人而异。笔者不知见识过多少次这样的场景:二人在对话中就项目的目标达成了一致,之后却发现彼此对关键词的理解大相径庭。因此,如果在项目开始时彻底厘清每个词的定义,就能省下不少时间。
例如,假设你要估算“2019年的英国人口数量”。这是指2019年初、年末还是年中的人口数量?还是三者的平均值?这里的“人口”是指常住居民,还是包括游客和临时居民在内的所有人?
回到表情包的话题上。首先声明,笔者要讨论的并非表情包的学术定义,而是网络表情包(结合了网上流行的图像和文字)。更具体地说,笔者感兴趣的是找出最流行的表情包模板(表情包的背景图像)。因此笔者所谓的“最火表情包”其实指的是:浏览人次最多的表情包模板(通过累加所有使用该模板的网络表情包的浏览量来计算得出)。
明确了这一点之后,就要开始收集数据。
2.以最小化偏差的方式采样数据
尼尔森排名系统不可能监测每台电视机,同样,笔者也无法全部下载网络上的每个表情包。因此,这两种情况都必须要经过采样。
如果一个数据样本真正代表了更广泛的群体,那么我们称其为无偏见数据。但在很多情况下,这是不可能的。通常,我们必须以尽可能合理的方式最小化偏差,然后在分析数据时尽最大努力修正偏差。
本项目中的表情包采集自Reddit,它是世界上最大的图片分享网站之一。使用一个爬虫工具在一天中多次查看该网站与表情包有关的几个部分,并且抓取前100张最受欢迎的图片。
其中的许多表情包都托管在Imgur上,该网站公开了表情包浏览数据。因此交叉引用这些数据可以让我们推断出Reddit上图片的浏览量。通过Reddit和Imgur的应用程序接口(API),只需寥寥几行python代码就可完成该采样。
接下来的问题是:这一采样方法真的能够最小化偏差吗?Reddit只是网站中的一个个例,所以并不能真正代表整个互联网。我们可以对其他网站(如instagram或Facebook)上的表情包进行采样,以减少偏差。
然而,这些网站公开的数据有限,无法进行比对。比对这些网站数据的唯一的方法是做出大胆的假设,但此举可能会为最终估计值引入更多的偏差。
没有十全十美的答案。有时,我们只能接受这一点。笔者认为应当从一个最优的数据来源进行采样,而不是将多个数据来源合并起来得到一个不可靠的数据集。笔者之所以称Reddit是最好的来源,是因为它是最大的图像共享网站,从中(通过交叉引用Imgur的数据)可以推断出精度合适的浏览量。
3. 复杂模型只适用于复杂问题
我们需要确定数据集中每个表情包所使用的图像模板。这是一个图像分类问题,并且属于一个简单的图像分类问题。如果简单的方法就足以见效,那么就没必要选择复杂的解决方案。
近来最先进的图像分类器,比如那些在Image-Net比赛中名列前茅的分类器,都是能够不受角度、光线或背景的影响而正确识别物体的深度神经网络。观察一个表情包并识别其图像模板则容易得多,因此需要的东西远非100层神经网络那么复杂。
表情包图像模板的数量有限,并且都具有独特的颜色模式。我们仅需要计算像素并将结果传递给线性支持向量机,就能精确地分类表情包。训练支持向量机仅需几秒,而神经网络则需要数天。
4. 审核(有条件时引入人工)
很多时候,踌躇满志的年轻数据科学家跑来找到笔者,自豪地公布一个伟大的发现,却在被问及如何审核结果时面露怯色。通过基本的审核发现重大纰漏后,所谓的伟大发现往往将黯然退场。
在审核图形分类模型的结果时,人眼是无可替代的(至少目前如此)。你或许认为,验证图形分类器在这个数据集(约有43000张图像)上的结果需要很长时间,但有许多工具能加速这一过程。
借助标注工具,笔者平均使用20秒就能够审核100张图像(在10x10的格子中浏览),因此,全部审核完43000张图像只花费了不到3小时。这样的事情日常做大概吃不消,但一年一次还可以忍受。
5. 仔细考虑每个假设
统计模型有赖于数据和假设。通常情况下,原始数据无法优化,但假设可以改进。工作的最后一步是获取数据集,并提取出每个表情包模板的浏览数据。由于数据具有局限性,这一分析需要一些额外的假设。
第一个假设涉及到缺失值。如果数据集中的某个条目出现了缺失值,那么最好是移除该条目(因而将减小样本)呢,还是推测该缺失值是什么(因而或将引入误差)呢?
这取决于数据集中缺失值的比例。如果比例较低,通常最好直接丢弃缺失值。而如果比例较高(该表情包数据集就是如此),那么丢弃所有缺失值可能会大大降低样本的代表性。因此,笔者认为尽可能准确地填充这些缺失值是更好的做法。
第二个假设涉及修正我们的数据集对Reddit用户的倾向性。笔者用下面的“传播”假设来解决这一问题。笔者从Reddit的几十个不同板块进行了采样,以此来测量每个表情包模板在多少个板块中出现过。笔者假设,一个表情包在Reddit内部传播得越广,说明它在Reddit之外的传播范围也越广。为了反映这一点,笔者扩增了这些表情包的浏览次数。
对于假设来说,标准答案是不存在的。我们唯一的选择就是做出能让人信服的抉择。
计算结果:最受欢迎的表情包模板(2018年)
该算法在2018年全年都在运行,共下载了40万张图片,并识别出其中的43660张使用了250个最常见的表情包模板之一。
如你所见,歌星Drake的表情图以极大优势夺得了2018年的流行之冠,共有1亿5700万次浏览量(该分析结果很有可能小于实际数据)。
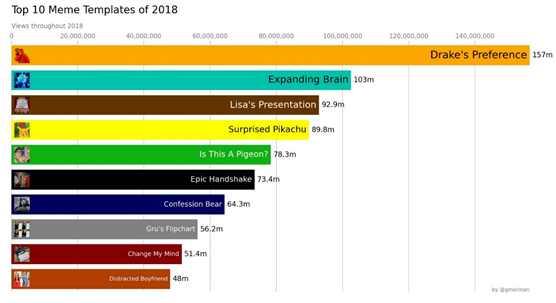
此外,顶层模板的总浏览量分布近似于帕累托分布(Pareto distribution)。
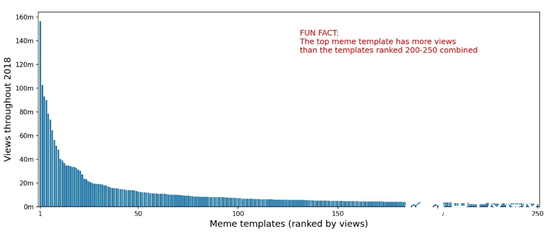
世界上有许多难以精确测算的事物,表情包的流行程度就是其中之一。有时我们只能尽量追求最优解。笔者讨论了在这一工作中使用的5项原则,一言以蔽之,即:在着手开始之前,仔细考虑项目的每个步骤。
责编AJX
-
数据
+关注
关注
8文章
7017浏览量
89009 -
数据采集
+关注
关注
38文章
6090浏览量
113641 -
数据科学
+关注
关注
0文章
165浏览量
10056
发布评论请先 登录
相关推荐
使用Python+OpenCV处理图片
高精密的电路噪声如何计算?
ADS1298RECGFE-PDK增强导联的模拟输出和计算后的数值为什么有很大差异?
TAS5720MEVM Z1/Z2/C11/C12是如何计算得出的?
LPV521 Vout是怎么计算得出的呢?
LMH6552在设置放大倍数为2时,计算得RF/RG=2,输出的波形有偏差,为什么?
张永炜:智能物联2.0时代,如何用数字化手段助力“双碳”目标的实现?

请问NanoEdge AI数据集该如何构建?
STM32 IDE如何访问、计算得到122.69K并暂存到变量中呢?

鸿蒙HarmonyOS引用图片的方法





 工商网监
工商网监
评论