 出了世界最大芯片的公司!
出了世界最大芯片的公司!
前言:这半年日子过得有点困苦,(请走过路过的朋友多多请我吃饭咖啡),为了在苦中有点开心的事情,我决定用业余时间来八卦公司。
如果说IT硬件行业三大项:计算,存储和网络。我十年修习网络,十年修习计算(仅半边),至于存储,存储我认识专家。从业经验么,我待过四家公司,我肯定避开这四家公司。
结合这种背景,来看我仅代表个人观点的八卦。
1.2019 Hot Chips一鸣惊人
Cerebras是2019年HotChips大会上一鸣惊人的。Wafer Scale,可着一个wafer能出的最大芯片尺寸出的,1.2T的晶体管,超过EDA工具的能力了,40万个AI核,18GB的片上Memory, 100Pbit/s的Fabric带宽。
做世界第一大芯片,难不难?难到超纲,本来是有一个Reticlesize的约束的。上一次试图做类似尝试的公司,在1980年代烧光了$230million美金(wow,美国的VC们很有钱很有野心么),还留了一句,大约要等上100年,才能成功的话。无论Cerebras的AI做得成不成功,至少大芯片做得很成功,超摩尔定律的那种成功。
46,225平方毫米,约等于462平方厘米
2.公司财务与核心成员
Cerebras在2016年成立,A轮融了$27 million, B轮$25million,C轮$60milion,最近的D轮融了 $88 million,就是一共$200million (2亿美金),一共200人。这是一家估值在3年前,C轮就到近9亿的公司,就算是10亿美金的公司吧。
第一颗芯片,16nm,按Gartner2017年的数字,费用大约$80 million。因为Cerebras的难度,还有做系统的费用,我觉得研发至少得花了$100 million吧。如果一个工程师,一年的开销是$150K,200人,一年$30 million。好在前两年不会有那么多的人,薪资这块算$50million,因此帐上应该还有$50 million吧。第二颗芯片的投片之前,得再融一轮吧。
公司的CEO,也是一个人物,成功创建了SeaMicro(熟,做服务器的) ,然后2012年成功的卖给AMD。CTO 早在1990年代,在Sun的时代(那时的Sun如日中天)就是一个芯片设计工程师,做过AMD的fellow。
看看其它核心成员,一水的SeaMicro + AMD的经历,这是一个成熟的创业团队(团队组的早,创业创的好)。
CEO:Andrew Feldman
Chief Hardware Architect:Sean Lie
Chief System Architect:Jean-PhilippeFricker
Chief Software Architect:MichaelJames
3.产品
为什么选Cerebras这种创业公司开始写?我其实写NVIDIA写了几个月了,产品线才刚刚理明白。Cerebras统共就一颗芯片WSE1,一个参考系统CS-1,明年出第二代产品,估计把数字换成2就行了,多么简单明了。
3.1 回溯历史与产品规划的Inside Out
这家公司,我觉得算是典型的Inside Out的产品规划思路。(刚刚上过的产品课程。Inside Out是指把团队能力输出成产品,然后在世界上寻找可以解决的问题,这种产品规划模式;相对的是Outside In,先确定一个要解决的问题,把解决方式提炼为产品的过程)。
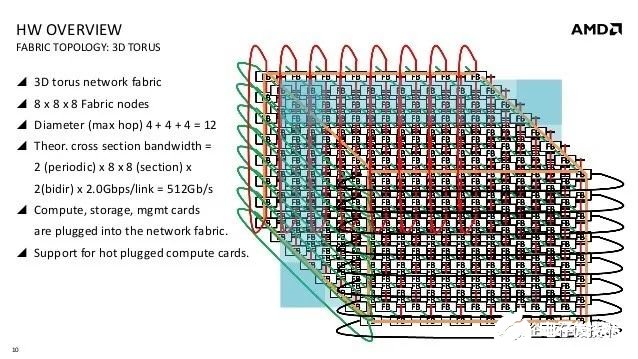
这个团队的能力是搭建众核系统的能力, sea of cores, 什么core并不重要,AMD当年收购SeaMicro是为了 Freedom Fabric ASIC Technology,2012年的Freedom Fabric是一个颗独立的芯片,可以用2.5Gbps接口,以3D torus的方式连接512个处理器。我找了一张旧图如下。
如果按照这个套路,拿众核系统来看有什么问题可以解决,那么AI是选中的问题。2016年就选定AI training做目标问题,这个眼光,还是很可以的。
3.2 为什么做超级大芯片与做超级大芯片难在哪里
在AI领域,做超大系统,是一件正确的事情么?
回答:不但正确,而且是竞争激烈的巅峰之战。
(BTW,这是CTO的角度,像我这种,打算修炼为CMO-chief marketing officer其实并不赞成这种军备竞赛似的大系统,物美价优的云服务才是主航道)
Google TPU:我的multi-pods可以支持最高到4K芯片集联(128*32 mesh拓扑)。
NVIDIA:我不但有售价近20万美金的DGX系统,我还能组合1,000个GPU成为SuperPOD (200Gb/s IB network)呢,而且SuperPOD和SuperPOD还能互联成更大系统呢,知道我为什么买Mellanox了吧。
Graphcore:我们8个芯片的系统才卖3万5(美金)。我们有自有的IPU-Fabric(3D ring 拓扑),可以搭64,000个IPU的超级系统。(这是我打算八卦的第二个公司)
Cerebras:我们就是一个支持40万个核的平淡无奇的小AI系统吧。买两个系统有折扣,就500万美金
把一个超大系统做在一个芯片里,难么?
回答:难
首先光刻机能加工的最大尺寸die,这个限制叫Reticlesize,如下图左;其次突破Reticle size的限制,我们采取例如CoWoS这种封装技术,如下图中,拿两个die拼一个大芯片;但是Cerebras是如下图右,通过cross-die connectivity 连接了84个die。
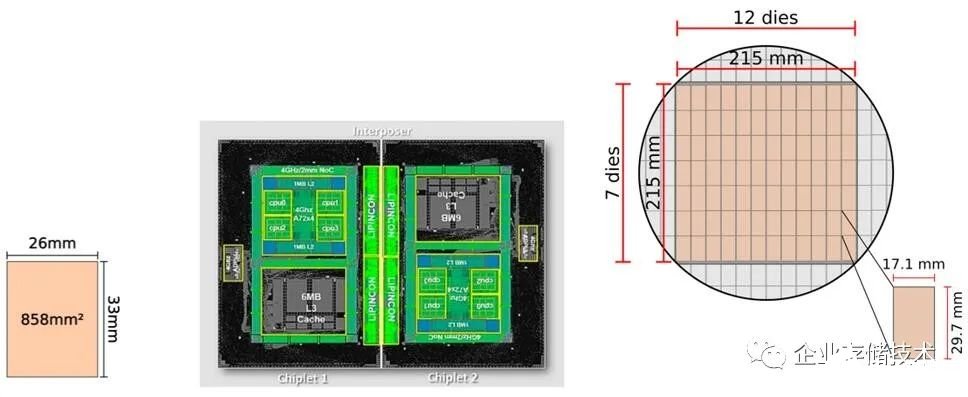
在Cerebras给出的需要解决的挑战问题中,如何做cross-die的互联,排在第一位。代价比想象得低,只多了一层mask。Yield问题解决的也很漂亮。Hot Chips 2019的资料已经公开,太设计相关的细节我就不详细展开了,大家有兴趣的,可以自行参考。
编者补充:当蚀刻电路时,晶圆会产生一些无法修复的缺陷区域。在同样的缺陷分布下,晶圆分割的数量越少,裸片越大,缺陷的影响就越大。因此Cerebras必须建立冗余电路、绕过缺陷。
有了芯片,高达15KW的功耗,供电冷却都是问题,系统也难做。
一个好的产品经理,往往都卡着产业界的极限设计产品。因此突破一个极限之后,等待工程师的是连续的极限挑战。Cerebras就是这样的一个,连续挑战极限的产品与系统。它的商业成功很难预计,但是从技术突破的角度看,有很多看点。我对它的第二代产品,还是蛮有期待的。
打破了的极限,就是产业界的能力。TSMC已经放出消息来,打算2年之内,把这个wafer-scale芯片技术商业化。我甚至对第二家打算走这条路的公司,都有所期待了。
责任编辑:haq
-
芯片
+关注
关注
454文章
50472浏览量
422041 -
带宽
+关注
关注
3文章
918浏览量
40858 -
IT
+关注
关注
2文章
857浏览量
63474 -
AI
+关注
关注
87文章
30272浏览量
268502
发布评论请先 登录
相关推荐
富士康将在墨西哥建设全球最大英伟达芯片厂
今日看点丨富士康:正在建设全球最大的英伟达超级芯片工厂;传理想汽车智能驾驶SoC芯片年底前完成流片
世界先进和恩智浦合资成立VSMC公司
芯海科技闪耀2023世界计算大会:EC芯片引领计算新变革

OPA2365作为电压跟随器,超出了手册推荐最大的5.5V就会发热,为什么?
英飞凌全球最大SiC芯片厂在马来西亚启用
40亿,今年芯片领域最大规模融资诞生

英特尔最大神经形态计算机研制成功
全球最大的芯片工厂,投资907亿美元
世界第一AI芯片发布!世界纪录直接翻倍 晶体管达4万亿个

世界最大SSD终于开卖:至少2.65万
芯片设计公司靠啥赚钱?
全球模拟芯片原厂公司一览(TOP 30)





 工商网监
工商网监
评论