 C语言的进阶操作实例讲解
C语言的进阶操作实例讲解
#include“xxx.c”
1、操作一波
咱们先体验一波#include“xxx.c”文件能不能用:
参考demo:
1//FileName :main
2#include 《stdio.h》
3#include 《stdlib.h》
4
5/***************************
6* .c文件声明区域
7**************************/
8#include “module1.c”
9#include “module2.c”
10
11/***************************
12* Fuction: main
13* Author :(最后一个bug)
14**************************/
15int main(int argc, char *argv[]) {
16
17Fuction1;
18Fuction2;
19printf( “欢迎关注公众号:最后一个bugn”);
20return0;
21}
1//FileName: Module1.c
2#include《stdio.h》
3/***************************
4* Fuction: Fuction1
5* Author :(最后一个bug)
6**************************/
7voidFuction1
8{
9printf( “Run Fuction1n”);
10}
1//FileName: Module2.c
2#include《stdio.h》
3/***************************
4* Fuction: Fuction2
5* Author :(最后一个bug)
6**************************/
7voidFuction2
8{
9printf( “Run Fuction2n”);
10}
输出结果:
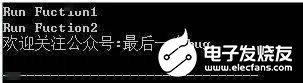
分析一下:
看来这波操作可行,似乎还省去了.h文件,之前bug菌说过,分析.h文件的时候直接把.h文件在对应的.c文件中的位置处展开然后进一步分析即可,其实这.c文件也是如此,接着往下看。
参考demo:
1//FileName :main
2#include 《stdio.h》
3#include 《stdlib.h》
4
5char * cBug1 = “bugNo1”; //这里是位置1
6char * cBug2 = “bugNo2”;
7/***************************
8* .c文件声明区域
9**************************/
10#include “module1.c”
11#include “module2.c”
12
13//char * cBug1 = “bugNo1”;//这里是位置2
14//char * cBug2 = “bugNo2”;
15
16/***************************
17* Fuction: main
18* Author :(最后一个bug)
19**************************/
20int main(int argc, char *argv[]) {
21
22Fuction1;
23Fuction2;
24printf( “欢迎关注公众号:最后一个bugn”);
25return0;
26}
1//FileName: Module2.c
2#include《stdio.h》
3/***************************
4* Fuction: Fuction1
5* Author :(最后一个bug)
6**************************/
7voidFuction1
8{
9printf( “Run Fuction1n”);
10printf( “%sn”,cBug1);
11}
1//FileName: Module2.c
2#include《stdio.h》
3/***************************
4* Fuction: Fuction2
5* Author :(最后一个bug)
6**************************/
7voidFuction2
8{
9printf( “Run Fuction2n”);
10printf( “%sn”,cBug2);
11}
输出结果:
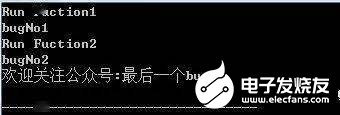
分析一下:
我们在位置1进行两个变量的定义,成功编译运行得到如上的结果,符合我们的预期,然而当我们去掉位置1进行位置2的定义,程序却无法进行编译,看来跟我们预期在编译过程中直接展开.c文件是一致的。
2、有什么用?
这种方式在bug菌的编码历史长河中一般只在两种情况下用到:
1、维护毫无设计的代码
有些历史悠久的项目经过了N多位大佬的蹂躏,说实在的代码结构上已经非常可怕了,往往每个源文件内容非常之长,为了保持代码原样,会采用#include“xxx.c”把这几的相关文件嵌入进去,也便于自己后期维护。
2、测试代码
在前期进行软件调试的时候可能自己会在不同的文件中安插不同测试功能函数,通过这样方法可以方便的引入和剔除。
比如说你需要对源文件中的一些静态变量进行相关的监控处理,然而又不想在本文件中增加测试代码,于是便可以在#include“xxx.c”中进行测试函数的编写来供使用,比如 :
1//FileName :main
2#include 《stdio.h》
3#include 《stdlib.h》
4
5staticint a = 5;
6/***************************
7* .c文件声明区域
8**************************/
9#include “module1.c”
10
11/***************************
12* Fuction: main
13* Author :(最后一个bug)
14**************************/
15int main(int argc, char *argv[]) {
16
17Fuction1;
18printf( “main %dn”,a);
19printf( “欢迎关注公众号:最后一个bugn”);
20return0;
21}
1//FileName: Module2.c
2#include《stdio.h》
3/***************************
4* Fuction: Fuction1
5* Author :(最后一个bug)
6**************************/
7voidFuction1
8{
9printf( “Run Fuction1n”);
10printf( “Fuction1 %dn”,a);
11}

注意了!!
那么之前有小伙伴说 : “ static的作用域仅仅在对应的文件中 ”,通过上面的多个.c文件使用静态a变量,那么这位小伙伴表述就不那么贴切了!
3、技术总结
大家在正常的开发过程中bug菌还是不建议使用#include“xxx.c”,因为在我们程序的设计过程中,.h文件就是一种外部的引用接口,而.c是对应的内部实现,如果滥用#include“xxx.c”有可能造成函数等等的重复定义,同时也对调试相关程序带来一些困扰,当然如果游刃有余就没啥问题的啦。
不过对于喜欢写长文件的小伙伴来说却是是福音,把一个长的.c文件分成多个.c文件,这样至少可以把不知道这种用法的同事面前秀一秀!
贰
void
1、简单认识一下void
void在大部分小伙伴的程序中都只是用于函数无参数传入,或者无类型返回。然而我们平时所定义的变量都会有具体的类型,int,float,char等等,那是否有void类型的变量呢?大家可以动手实验一下,答案是:不行,编译会出错。
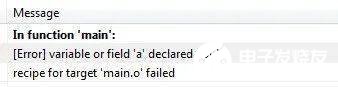
上图很明显编译器不允许定义void类型的变量,变量都是需要占用一定内存的,既然void表示无类型,编译器自然也就不知道该为其分配多大的内存,于是造成编译失败。
虽然void不能直接修饰变量,但是其可以用于修饰指针的指向即无类型指针void*,无类型指针那就有意义了,无类型指针不是一定要指向无类型数据,而是可以指向任意类型的数据。
2、void * 基本操作
大家其实在使用动态内存分配的使用就已经遇到了void *的使用,来我们一起看看如下几个标准函数的原型定义:
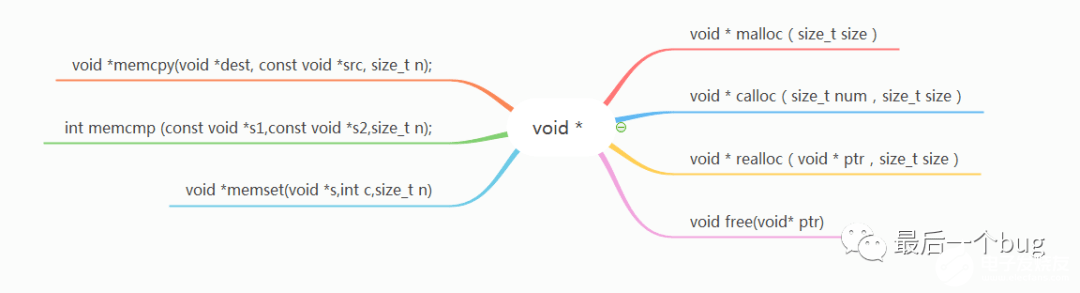
上面这些函数都是与内存操作有关的函数,可能一些小伙伴使用过也不一定知道每个参数的具体类型是什么,这些void*部分的形参所传入的实参都是不需要进行强制类型转化的,所以根本就不需要关注传入指针所指向的具体类型,然而函数所返回的void *一般都需要通过强制类型转化为对应的具体类型,除非你最后所传递的变量也是void*类型。
参考void*用法:
1#include 《stdio.h》
2#include 《stdlib.h》
3#include 《malloc.h》
4
5#define NUM 10
6/*************************************
7* Fuction:了解一下void*的使用
8* Author : (最后一个bug)
9*************************************/
10int main(int argc, char *argv[]) {
11int *p1 = (int *)malloc(NUM*sizeof(int));
12int *p2 = (int *)malloc(NUM*sizeof(int));
13int i = 0;
14
15//初始化p1
16for(i = 0;i 《 NUM;i++)
17{
18*(p1+i) = i;
19}
20//进行内存copy
21memcpy(p2,p1,NUM*sizeof(int));
22
23//输出另外一个分配的内存
24for(i = 0;i 《 NUM;i++)
25{
26printf( “%d,”,*(p2+i));
27}
28//释放内存
29free(p1);
30free(p2);
31return0;
32}
运行结果:
3、使用void * 实现无类型数据封装
为了保持文章的完整性,也许这里才是作者最想跟大家介绍的,void*既然如此的灵活一定大有用处,如果仅仅只是用来简单的传递参数似乎有点大材小用,我们得把其用到上层的软件设计上来。
在一些项目中经常看到有小伙伴把数据类型转来转去,甚至有时候为了一个数据类型的变化还得重新写一个仅仅数据类型不同的函数,这样的代码上万行代码指日可待,按下面我们以一个例子来跟大家介绍一种办法能够减少数据类型变化所带来的程序重复代码的增加。
参考实例:
1#include 《stdio.h》
2#include 《stdlib.h》
3/**********************************
4* Fuction : add
5* descir : 加法的相关数据及处理办法
6* Author : (最后一个bug)
7**********************************/
8typedef struct _tag_Add
9{
10int a;
11int b;
12int result;
13}sAdd;
14
15voidAdd( void*param)
16{
17sAdd *p = (sAdd *) param;
18p-》result = p-》a + p-》b;
19}
20/**********************************
21* Fuction : add
22* descir : 乘法的相关数据及处理办法
23* Author : (最后一个bug)
24**********************************/
25typedef struct _tag_Mul
26{
27float a;
28float b;
29float result;
30}sMul;
31
32voidMul( void*param)
33{
34sMul *p = (sMul *) param;
35p-》result = p-》a * p-》b;
36}
37
38/*************************************
39* Fuction : sCal
40* descir : 公共的调用接口
41* Author : (最后一个bug)
42************************************/
43voidsCal( void*param, void*fuc)
44{
45(( void(*)( void*))fuc)(param);
46}
47
48/**********************************
49* Fuction : main
50* descir : 应用接口实例
51* Author : (最后一个bug)
52**********************************/
53int main( void)
54{
55sAdd stAdd;
56sMul stMul;
57
58//数据初始化
59stAdd.a = 10;
60stAdd.b = 20;
61
62stMul.a = 5;
63stMul.b = 5;
64//接口直接用
65sCal(&stAdd,Add);
66sCal(&stMul,Mul);
67//对应的输出
68printf( “a + b = %dn”,stAdd.result);
69printf( “a * b = %fn”,stMul.result);
70printf( “公众号:最后一个bugn”);
71return0;
72}
运行结果:

分析一下:
上面的例子可能还是无法完全彰显void*的强悍之处了,不过其主要的作用就是为了隐藏数据类型,大家也可以理解为一种数据类型的抽象处理,这也是面向对象编程的一种体现。
4、技术总结
大家一定要记得对于一些编程技巧一定要尝试着去使用,可能达到项目目标的方式有很多种,但是一些好的设计不仅仅会让你的代码增色不少,同时也会让同事们觉得你是一个喜欢专研技术的人。
叁
“ 逗号表达式 ”
1、先来一个逗号表达式例子
一个逗号表达式的实例:
1#include 《stdio.h》
2#include 《stdlib.h》
3/******************************************
4* Fuction: Main
5* Descir : 测试一个逗号表达式
6* Author :(最后一个bug)
7*****************************************/
8int main(int argc, char *argv[]) {
9int Val = 1;
10
11Val = ++Val,Val+ 10,Val* 10; //逗号表达式
12
13printf( “Val = %d”,Val);
14
15return0;
16}
分析一下:
大家首先可以自己算一下最后输出的结果,然后再去看下面的答案,其实对于逗号表达式的语法规则并不是很难,主要是大家在平时的开发中使用得比较少,一旦经常不使用就容易淡忘。
逗号表达式的形式 :表达式1,表达式2,。..。..,表达式n
三点搞定:
逗号表达式从表达式1开始顺序 从左向右 执行;
其逗号表达式最后的值为 最后一个表达式的值 ;
逗号运算的 优先级最低 ,也就说明与其他运算符结合使用的时候,在没有括号的情况下逗号运算符最后才执行。
上面例子的结果:
可能有部分小伙伴算出的结果是10,主要是没有考虑其逗号表达式优先级最低,所以第一赋值表达式优先执行。
2、“不怎么用”是不是就“没有用”?
既然大家平时都用得不多,是不是这个逗号表达式就是多此一举呢 ? C发展这么多年,如果真的没有价值估计早就不存在了吧,所以还是要秉承着“存在即是合理”的态度看待逗号表达式。

大家在平时阅读代码的时候应该都是按照从左至右,然后从上至下来的方式吧。基本上一个分号结束一行的书写,由于电脑屏幕的限制,有效代码暴露在人的视野中是有限的,同时人瞬间记忆时间也是有限的,如果在一个小小的屏幕上阅码势必会阻碍程序员的阅读和理解,比如下面两种书写方式:
1/******************************************
2* Fuction: 非逗号表达式书写
3* Descir :
4* Author :(最后一个bug)
5*****************************************/
6if(IsOk)
7{
8sOkProc;
9returnGetOkCode;
10}
11else
12{
13sNoProc;
14returnGetNoCode;
15}
16/******************************************
17* Fuction: 采用逗号表达式书写
18* Descir :
19* Author :(最后一个bug)
20*****************************************/
21return(IsOk)?(sOkProc,GetOkCode):(sNoProc,GetNoCode);
分析一下:
上面是两种代码书写方式,第一种占据了多行,而第二种进占据一行,这样同样 一个屏幕所容纳的有效代码第一种就明显少于第二种方式 ,所以很多程序员都会选择使用一种大长屏或者多屏进行开发。
第二种方式似乎很多小伙伴觉得代码不够美观,也不便于维护,其实这仅仅只是一种习惯罢了,就好像编码的时候 : 第一个大括号是否需要另外起一行,或者是使用==号一定要像 if( 1== b) 这样把数据放左边,当你习惯了这种编码风格也会觉得用第二方式来得直接。
3、逗号表达式常用的地方
下面为大家介绍几个用逗号表示式比较多的地方:
1、for循环中的处理
参考demo:
1#include 《stdio.h》
2#include 《stdlib.h》
3#define ROW_NUM ( 5)
4#define LINE_NUM ( 5)
5/******************************************
6* Fuction: Main
7* Descir :for 遍历查找
8* Author :(最后一个bug)
9*****************************************/
10int main(int argc, char *argv[]) {
11int i = 0,j = 0;
12int Matrix[ROW_NUM][LINE_NUM] ={{ 1, 1, 1, 1, 1},
13{ 2, 2, 2, 2, 2},
14{ 3, 3, 3, 3, 3},
15{ 4, 4, 4, 4, 4},
16{ 5, 5, 5, 5, 5},
17};
18
19for(i = 0,j = 0;(i 《 ROW_NUM)&&(j 《 LINE_NUM);i++,j += 2)
20{
21printf( “Matrix[%d][%d] = %dn”,i,j,Matrix[i][j]);
22}
23printf( “公众号:最后一个bugn”);
24return0;
25}
分析一下:
上面在for循环中遍历相关数据几比较常规的处理,也是逗号表达式经常出现的地方,这样的表现形式让代码更加简单明了。
其结果如下:

2、弱化++处理
大家应该都知道++在前先执行自加,然后再进行相应处理,而++在后则相反,那么我们可以使用逗号运算符优先级最低的特点来弱化该问题,避免编码出现bug。
参考Demo
1#include 《stdio.h》
2#include 《stdlib.h》
3/******************************************
4* Fuction: Main
5* Descir :弱化++前后问题
6* Author :(最后一个bug)
7*****************************************/
8int main(int argc, char *argv[]) {
9int i = 0;
10
11//1、常规操作
12i = 0;
13while(++i 《 3)
14{
15printf( “ i = %dn”,i);
16}
17printf( “*****************n”);
18
19i = 0;
20while(i++ 《 3)
21{
22printf(“ i= %dn”, i);
23}
24printf(“***************** n”);
25
26// 2、逗号表达式处理一下
27i= 0;
28while( i++, i《 3)
29{
30printf(“ i= %dn”, i);
31}
32printf(“***************** n”);
33
34i= 0;
35while( ++ i, i《 3)
36{
37printf(“ i= %dn”, i);
38}
39printf(“***************** n”);
40
41printf(“公众号 :最后一个 bugn”);
42return0;
43}
44
分析一下:
当使用逗号表达式以后,不管++在前还是在后,其都会自增加1,然后再进行右边表达式的处理,这样就不用担心是不是多记了一次,导致各种问题。
运行结果:

3、更加精简宏定义
参考demo
1#include 《stdio.h》
2#include 《stdlib.h》
3
4#define GET_INDEX(a ,b) ( a+= 2,a + b)
5/******************************************
6* Fuction: Main
7* Descir : 简化宏
8* Author :(最后一个bug)
9*****************************************/
10int main(int argc, char *argv[]) {
11int i = 0,Val = 0;
12int Param1 = 0, Param2 = 0;
13int Matrix[ 5] ={ 5, 5, 5, 5, 5};
14
15printf( “ Matrix = %dn”,Matrix[GET_INDEX(Param1,Param2)]);
16printf( “公众号:最后一个bugn”);
17return0;
18}
分析一下:
逗号表达式 最终还是一个表达式 ,所以它可以直接用在几乎所有变量可以用的地方,这是和语句不同的。
所以逗号表达式左边的表达式可以预先进行各种处理,其最右边的表达式相当于返回最后的结果,从而减少函数的封装和调用。
4、技术总结
逗号表达式其实就是横向编码的一种方式,能够让程序员更好的利用一行的空间,使得代码更加紧凑,所以使用逗号表达式并没炫技,而是增强了代码的灵活度,不过话说回来逗号表达式在C混乱编码大赛上的使用频度是非常之高的。
-
调试
+关注
关注
7文章
578浏览量
33923 -
C语言
+关注
关注
180文章
7604浏览量
136683 -
函数
+关注
关注
3文章
4327浏览量
62569
发布评论请先 登录
相关推荐

C语言的进阶学习课件资料合集







 工商网监
工商网监
评论