 微软在EMNLP2020上发表最新工作
微软在EMNLP2020上发表最新工作
来自:NLPCAB
句子表示在很多任务中都是重要的一环。尤其是在大数据量的场景下,很多场景都需要召回+排序两个步骤,如果第一个环节没有召回候选结果,那最后的排序模型再怎么优秀也没法给出正确答案。
今天就给大家介绍一个微软在EMNLP2020上发表的最新工作,利用transformer生成更高质量的句子编码。
虽然BERT式模型的出现解决了很多判别问题,但直接用无监督语料训练出的BERT做句子表示并不理想:
如果只取CLS,这个表示是针对NSP进行优化的,表示的信息有限
如果取平均或最大池化,可能会把无用信息计算进来,增加噪声
所以作者的改进目的是设计一个下游任务,直接优化得到的句子embedding。
那怎么设计目标才能充分利用无监督数据呢?
作者给出了一个巧妙的方法,就是用周边其他句子的表示预测当前句子的token。
具体的做法是:先利用Transformer抽取句子表示,再对句子表示进行attention,选取相关的句子预测当前token。有点Hierarchical Attention的意思。

比如在预测上图中最后一句的黄蓝两个token时,明显第一句的信息就够用了,那目标函数的设置会让第一句的权重变大,也会让抽取出的句子表示去包含这些信息。
接下来详细介绍一下预训练和精调的步骤,以及作者加入的其他tricks。
Cross-Thought模型
预训练
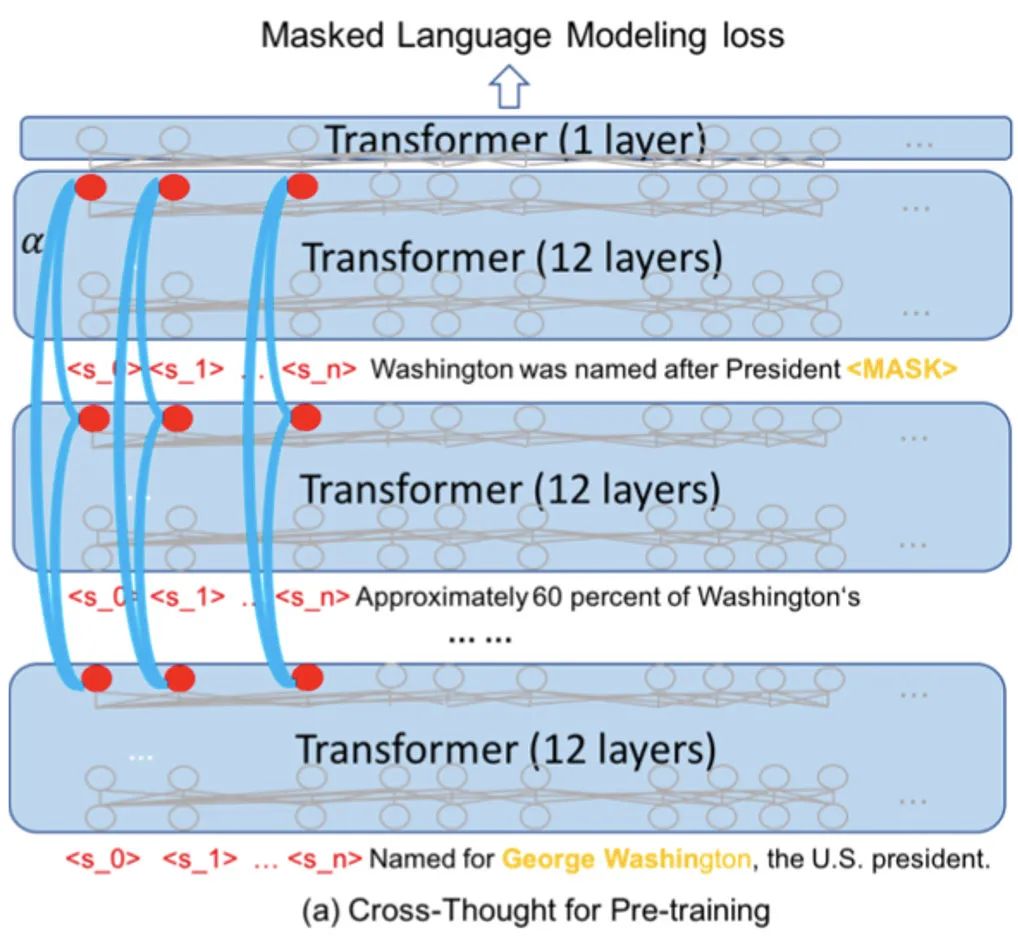
下图是预训练的模型结构,计算的步骤是:
将段落按顺序拆成独立短句,通过12层Transformer(蓝色半透明的矩形)分别进行编码。在实际的预训练中,每个sample包含500个长度为64的短句,batch size是128(16张V100)
取出
把每列句子表示作为一个序列输入到cross-sequence transformer(蓝色弧线,每一列的cross-sequence transformer参数都不同),输出attention分数加权后的新表示
将新的句子表示与第一步的token表示进行拼接,经过一层transformer,预测被mask的15%个token(每个句子都这么处理,图中只画了第一个句子的)
整体流程理解起来比较简单,作者还用了一些额外的tricks提升效果:
为了抽取更多的信息,在句子开头加入了多个占位token(之前BERT只有一个[CLS]),在实验结论中发现5个占位的表现较好(但占位token的增加会加大计算量)
占位token的位置表示是固定的,而真实token是随机从0-564中抽取连续的64个,这样可以训练更多的位置表示,方便之后对更长的序列进行编码
精调
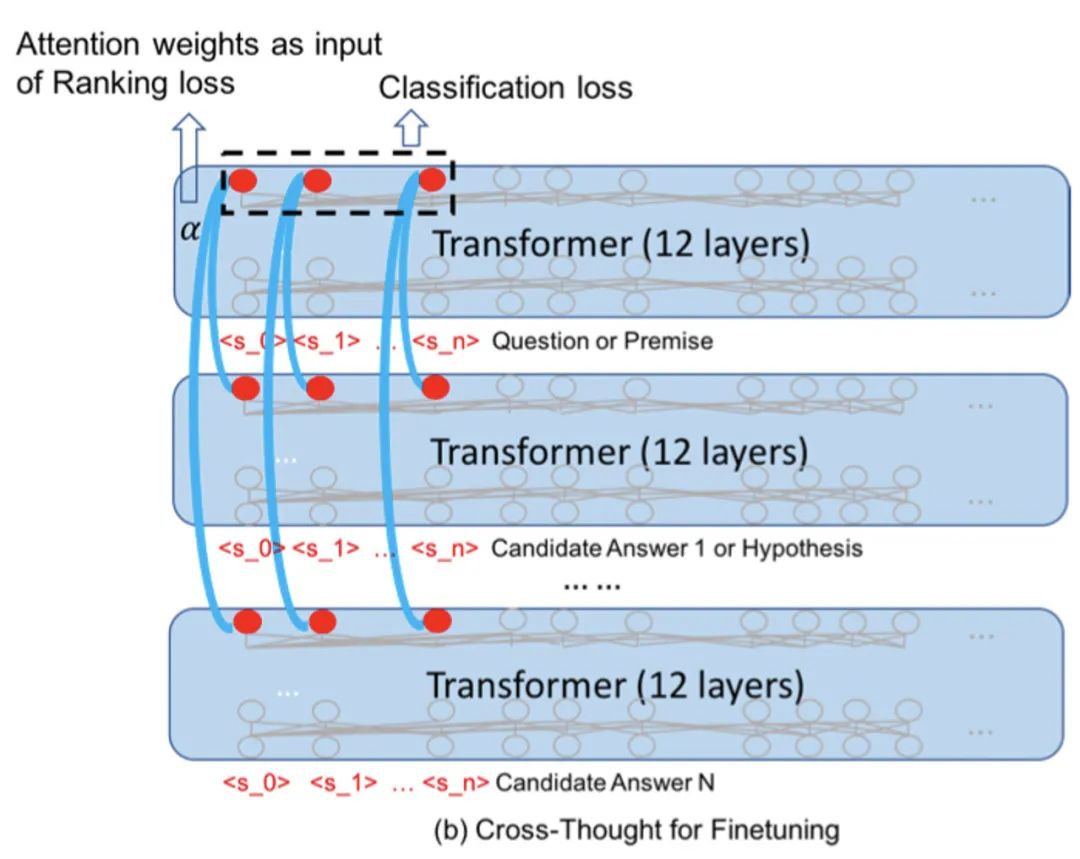
精调主要是考虑和下游任务的衔接。作者选择了问答和句子对分类来验证模型的表现。
对于问答任务,假设答案句子的表示都已经编码好了:
输入问题,经过12层Transformer得到问题表示
利用cross-sequence transformers,对问题表示与答案表示进行计算,得到各个答案的权重 (每列都会得到一个,作者对所有列取了平均)
根据gold answer的index m,计算Ranking loss(代表第0个答案的权重)
对于句子对分类任务比较简洁,输入两个句子A和B:
分别对A和B进行编码,取出句子表示,输入cross-sequence transformers得到融合后的句子表示
将两个句子的所有表示拼接起来,得到2Nxd的矩阵(N是占位token的个数,d是表示的维度)
把第二步得到的表示flatten,得到一个长度 2Nd 的一维向量,输入到分类层
实验效果
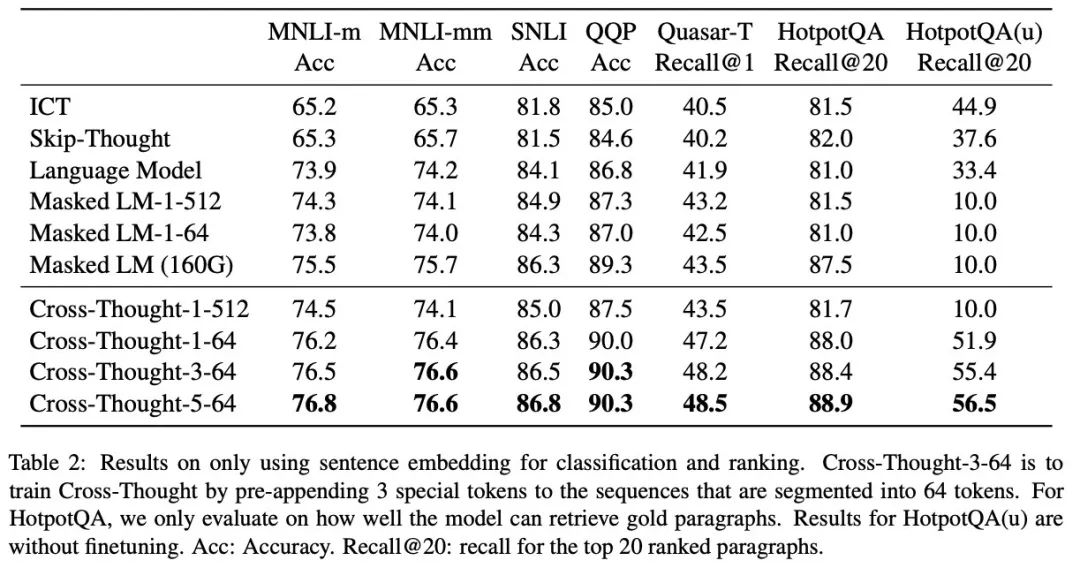
作者在不少数据集上都验证了效果,单纯从输出句子表示的效果来看,不仅是句间关系还是问答的候选召回上都有不小的提升,尤其是召回:
除了指标对比外,作者还展示了两个无监督预训练模型的打分结果:

总结
近两年句子表示的研究越来越少了,因为句子表示经常用于句间关系判断的任务,而交互式的判别显然比双塔效果要好。所以研究者们要不在研究更轻量的句间匹配模型(比如RE2、Deformer),要不就是继续用BERT类模型做出更好的效果。但对于业界来说,句子表示在召回上的速度还是最快的,效果也比单纯的字面匹配要好。
为了充分利用无监督数据、得到更高质量的句子表示,Cross-Thought提供了一个新的预训练思路:用句子表示预测token。同时也给我们展现出了它在候选召回上的巨大潜力,添加的额外cross-sequence transformer对速度的影响也不会太大。另外,作者只使用了wiki语料进行预训练,如果有更多语料相信效果会更好。
目前源码还未放出,希望开源社区的富有大佬们早日训一个中文的Cross-Thought~
原文标题:【EMNLP2020】超越MLM,微软打造全新预训练任务
文章出处:【微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
责任编辑:haq
-
微软
+关注
关注
4文章
6600浏览量
104129 -
函数
+关注
关注
3文章
4333浏览量
62700
原文标题:【EMNLP2020】超越MLM,微软打造全新预训练任务
文章出处:【微信号:zenRRan,微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
微软寻求在365 Copilot中引入非OpenAI模型
微软在美国面临反垄断调查
微软发布Azure AI Foundry,推动云服务增长
微软在东京开设日本首个研究基地
NVIDIA Research在ECCV 2024上展示多项创新成果
微软高管谈AI将如何改变工作方式

【P2020无法上电】付费咨询
芯思杰杨彦伟团队荣获“示范性劳模和工匠人才创新工作室”授牌

微软关闭旗下四家游戏工作室
喜讯!坚持技术创新,华秋获评深圳市示范性劳模和工匠人才创新工作室






 工商网监
工商网监
评论