 微软团队发布生物医学领域NLP基准
微软团队发布生物医学领域NLP基准
来自:HyperAI超神经
微软的研究团队近日在 arxiv.org 发布了论文:《Domain-Specific Language Model Pretraining for BiomedicalNatural Language Processing生物医学特定领域的语言模型预训练》,介绍并开源了一个能够用于生物医学领域 NLP 基准,并命名为 BLURB。
BiomedicalLanguageUnderstanding andReasoningBenchmark 的首字母缩写,即为 BLURB 的命名规则,翻译为生物医学语言理解和推理基准。
医学 NLP 基准,BLURB 身负重任
BLURB 包括 13 个公开可用的数据集,涉及 6 个不同的任务。
为了避免偏重多可用数据集的任务,如命名实体识别(NER),BLURB 的报告和排名,将所有任务的宏观平均数作为主要得分。
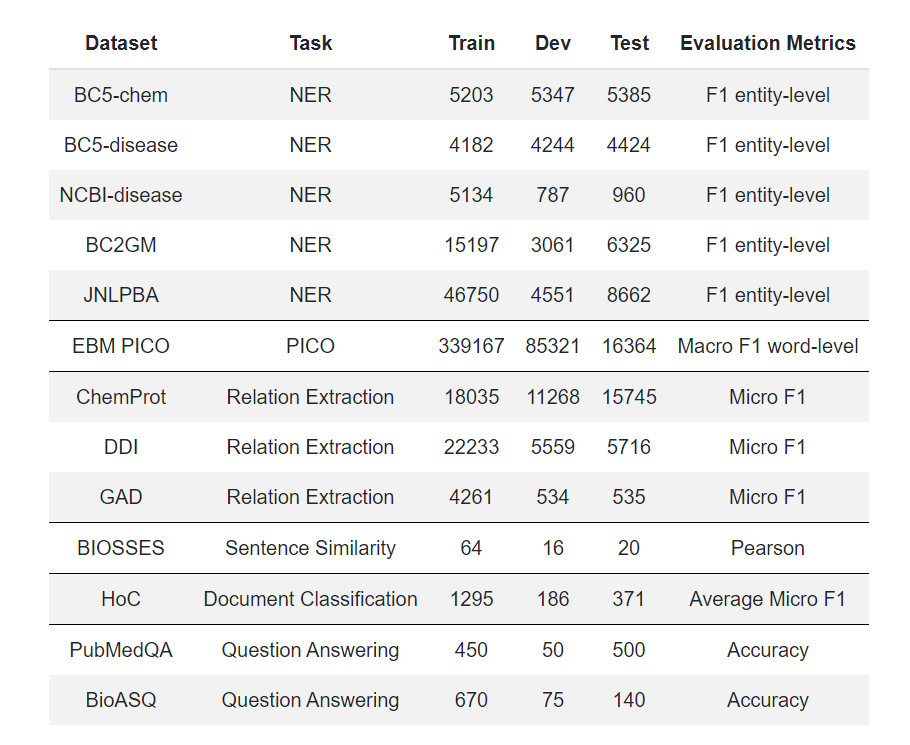
图为 BLURB 中使用的数据集、以及
团队列出的训练、开发和测试中的实例数量
BLURB 排行榜是不分模型的。任何能够使用相同的训练和开发数据产生测试预测的系统都可以参与。
团队表示 BLURB 的主要目标是:降低生物医学NLP的准入门槛,帮助加快该领域的进展,能对社会和人类产生积极影响。
生物医学 NLP :必须使用域内文本
研究已经表明生物医学 NLP 可以在医学领域提高数据集的准确性。但是在跨学科的数据集中,准确性又会大大降低。而由于不同医学领域之间(Domain)跨度较大,所以对于 NLP 的预训练会花费非常多的时间。
微软研究人员为了提升 NLP 的训练速度,通过对预训练和特定任务的微调,对生物医学 NLP 应用的影响进行了建模比较,从而评估最适合的预训练方法。
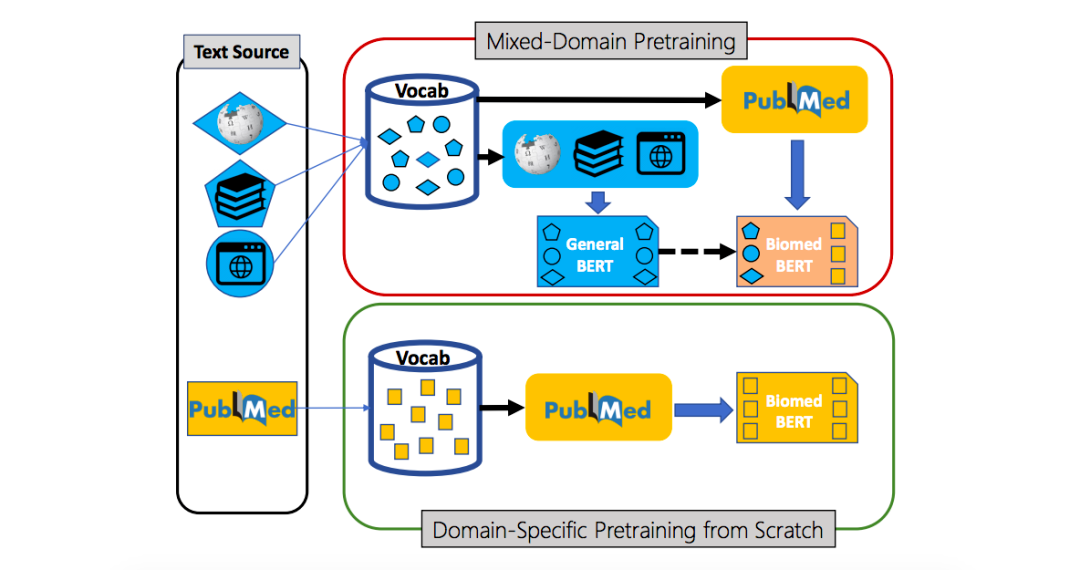
团队对域内文本与混合域外文本进行的对照
首先,团队创建了一个名为「生物医学语言理解与推理基准」(BLURB)的基准,该基准侧重于 PubMed 提供的出版物,涵盖了相似问题解答和文本提取之类的任务。
实验证明,这种对比的方法能够将 NLP 训练的速度提升数倍。
同时,为了鼓励对生物医学 NLP 的研究,研究人员创建了以 BLURB 基准为基准的排行榜,还开源了预训练模型。以求快速生物医学 NLP 能够早日投入使用。
原文标题:医学AI又一突破,微软开源生物医学NLP基准:BLURB
文章出处:【微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
责任编辑:haq
-
微软
+关注
关注
4文章
6644浏览量
105048 -
AI
+关注
关注
87文章
33025浏览量
272812 -
生物医学
+关注
关注
0文章
47浏览量
11244
原文标题:医学AI又一突破,微软开源生物医学NLP基准:BLURB
文章出处:【微信号:zenRRan,微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
安泰:1600V高电压放大器生物研究超声测试怎么做
函数信号分析仪的原理和应用场景
雷钰团队及合作者在二维材料缺陷调控及生物应用等领域取得新进展

短波、中波、长波和近红外VCSEL在各个领域的革命性研究

功率放大器应用:超声波换能器从材料策略到生物医学的应用

高通量生物分析技术之微流控芯片
高光谱成像技术在生物物证领域的研究进展2.0

BioMEMS的原理、结构及应用
威世科技硅PIN光电二极管VEMD8082,引领生物医学监测新纪元
NLP技术在人工智能领域的重要性
北卡罗来纳州立大学:加速外骨骼机器人控制系统的研发
微软发布新版Team Copilot,强化团队协作功能
受蜂巢结构启发的SERS微阵列,用于自动化检测唾液中脲酶活性

电化学生物传感器在生物检测领域的显著优势





 工商网监
工商网监
评论