 MLPerf Inference基准测试结果的第二轮发布
MLPerf Inference基准测试结果的第二轮发布
今天是MLPerf Inference基准测试结果的第二轮发布(0.7版)。与7月份宣布的最新培训结果一样,新的推论数字表明提交的公司数量有所增加,支持的平台和工作负载也有所增加。MLPerf推断编号分为四类-数据中心,边缘,移动和笔记本。提交的数量从43个增加到327个,提交的公司数量从仅仅9个增加到21个。提交的公司包括半导体公司,设备OEM和几个测试实验室。这轮提交的明显遗漏包括Google和所有中国公司,包括先前的参与者阿里巴巴和腾讯。
作为快速更新,MLPerf是一个行业协会,旨在开发机器学习(ML)/人工智能(AI)解决方案的标准。MLPerf是一组基准测试的汇编,用于测量ML / AL硬件,软件和服务的训练和推理性能。最新的Inference v0.7结果仅是第二次发布推理结果。第一次是大约一年前。MLPerf组织正在不断努力,以代表真实AI工作负载的新模型或增强模型来增强基准套件。此外,该组织正在努力提高测试频率,以每年至少两次为目标,正在考虑允许在主要版本之间发布测试结果,并努力添加其他限定词,例如用于评估AI平台效率的功耗数据。测试结果可以由电子价值链中的任何公司提供,并可以进行随机审核。
每个细分类别都包括一个“封闭”和“开放”细分。“封闭”部分是指使用与参考模型相同的工作量模型运行的测试。“开放”部分允许更改模型,以便供应商可以展示相对于其他目标工作负载的性能。此外,还有一些细分市场-当前市场上的产品“可用”,未来六个月内市场上的产品的“预览”,以及仍在开发中或刚刚考虑的产品的“研究,开发或内部”实验室项目。为了保持一致,我们大多数分析都集中在封闭和可用的细分上。在某些情况下,产品没有所有测试的编号,因为没有提交编号或无法达到最低99%的准确度等级。由于基准套件不断变化,在套件达到更成熟的状态之前,将数字与以前的结果进行比较并不是特别有用。但是,从结果中可以收集到很多东西。
对于数据中心应用,推理0.7v测试包括四个新基准测试-代表自然语言处理工作负载的双向编码器表示和转换(BERT),代表推荐工作负载的深度学习推荐模型(DLRM),代表医学成像的3D U-Net工作量,以及代表语音到文本工作量的递归神经网络转换器(RNN-T)。在封闭类别中,结果类似于7月份发布的培训测试结果。加速平台在性能上大大超过了纯CPU平台,领先的加速器是GPU,领先的GPU则是英伟达基于Ampere架构的新型A-100 GPU。在每个工作负载中,前任领导者特斯拉(T4)GPU的性能提升显然是显而易见的。这证明了Ampere架构的价值,该架构允许在单个GPU上进行七个推理分区。在其他加速器方面,仅Xilinx FPGA代表并且仅在开放类别中。
责任编辑:lq
-
人工智能
+关注
关注
1791文章
47294浏览量
238573 -
机器学习
+关注
关注
66文章
8419浏览量
132670 -
深度学习
+关注
关注
73文章
5503浏览量
121179 -
MLPerf
+关注
关注
0文章
35浏览量
641
发布评论请先 登录
相关推荐
MLCommons推出AI基准测试0.5版
Sam Altman亲自推销Rain AI寻求新融资
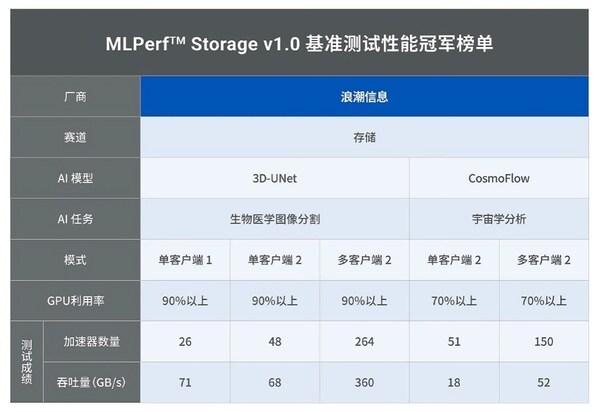
浪潮信息AS13000G7荣获MLPerf™ AI存储基准测试五项性能全球第一
Applied Intuition再获3亿美元融资,加速AI技术布局
PhotonVentures基金募资达7500万欧元,开发集成光子学的“深度技术”
华为Pura 70新机悄然发售,全年销量有望破5000万台
UL Procyon AI 发布图像生成基准测试,基于Stable Diffusion
连接器企业盛凌电子深交所IPO新进展
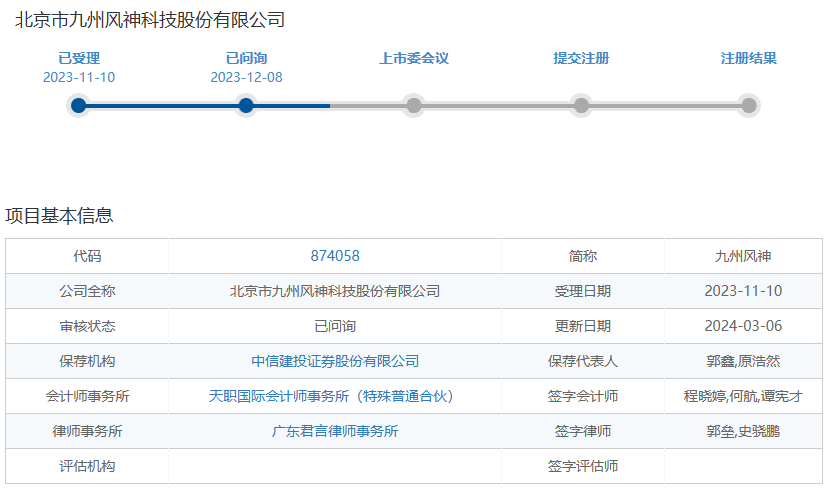
九州风神冲刺北交所IPO
九州风神北交所IPO新进展
九州风神北交所IPO迎新进展!主打高性能散热器,募资5亿进军马来西亚和欧洲市场
三星电子薪资谈判困局,罢工危机隐现
Vision Board/首款ARM Cortex-M85开发板价格大公开






 工商网监
工商网监
评论