 混合CPU和模拟内存AI处理器的发明专利解析
混合CPU和模拟内存AI处理器的发明专利解析
英特尔发明的混合处理架构的人工智能芯片,通过将CPU与模拟内存AI处理器相耦合,从而达到加速神经网络运算的目的。
英特尔在2019年发布了两款Nervana NNP系列新的处理器,目的在于加速人工智能模型的训练。据悉,英特尔的这两款芯片是以2016年收购的Nervana Systems命名,在人工智能训练以及数据分析等方面有着极大的价值。
而英特尔与英伟达作为AI芯片竞争的主要成员,均在AI领域奋起发力,其中,英特尔主导AI推理市场,而英伟达主导AI训练芯片。
但是用于神经网络处理的加速器系统,仍然存在着许多问题,例如由于与从存储器到数字处理单元的数据传输的带宽限制而导致的问题,这些加速器通常需要在片外存储器和数字处理单元之间传输大量数据,而这种数据传输会导致延迟和功耗的不良增加。
为此,英特尔在2020年7月30日申请了一项名为“混合CPU和模拟内存人工智能处理器”的发明专利(公开号:US 2020/0242458 A1),申请人为英特尔公司,该专利旨在提供用于实现通用处理器的混合处理架构的技术。
根据该专利目前公开的资料,让我们一起来看看这项混合处理架构的人工智能芯片吧。
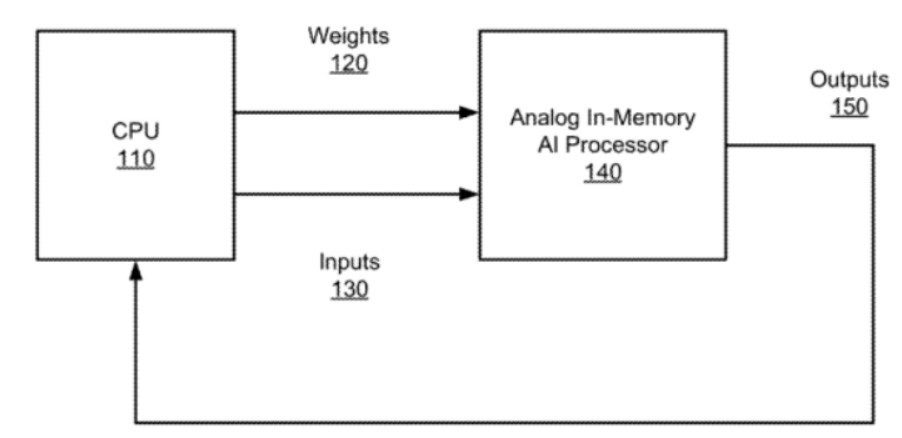
如上图,为这种混合处理器的顶级框图,可以看到,CPU与模拟内存AI处理器相耦合,CPU是通用处理器,例如我们熟知的x86架构处理器。模拟存储器中AI处理器可以通过数字访问电路从CPU接收加权因子和输入数据130,并基于加权因子和数据执行模拟神经网络处理。
模拟内存中AI处理器包括多个MN层,可以将它们配置为卷积神经网络层和全连接层,并且可以任意的组合使用,卷积神经网络层的处理结果也可以通过数字访问电路提供给CPU作为输出150。
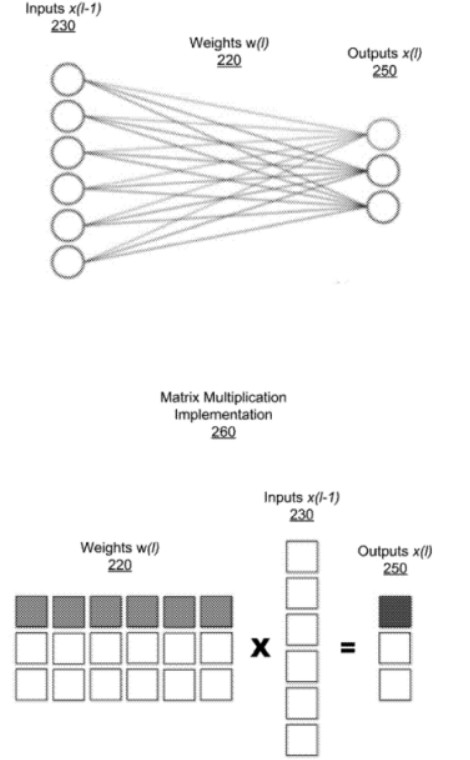
如上图,展示了全连接层的网络层和该层的矩阵乘法实现,网络层接受来自于上一层的输入230,并将权重w(220)应用于输入x(230)和输出x(250)之间的每个连接,由此将网络实现为矩阵乘法运算,如260所示,将输出的每个元素计算为权重220行与输入230列之间的点积。
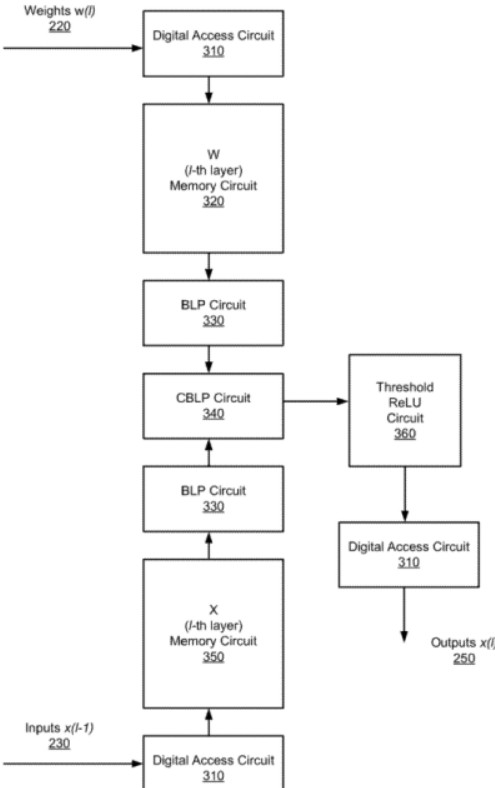
如上图,为该专利中的模拟内存人工智能处理器的框图,AI处理器用来实现完全连接的单个神经网络层,其中包括数字访问电路310、第一存储器电路320、第二存储器电路350、位线处理器电路330、交叉位线处理器电路340以及阈值整流线性单元(ReLU)电路360。
这些电路的作用就是实现各种点乘运算以及模拟乘法运算,这些运算是深度神经网络中常用的操作,而人工智能芯片就是在硬件的层面上对于这些运算进行实现,而直接从硬件层面进行运算的好处就在于会更加的快捷以及有较高的效率。
具体而言,交叉位线处理器电路通过定时电容器上的电流积分来执行点积运算的模拟乘法部分,该电路实际上是一个与开关串联的电容器。在位线上感测到的电压作为被乘数输入之一,通过与电容器产生电流,另一个被乘数用来控制串联开关的时序,以使开关导通的持续时间与第二个开关成比例。从而通过电荷累积来执行点积运算的模拟求和部分。
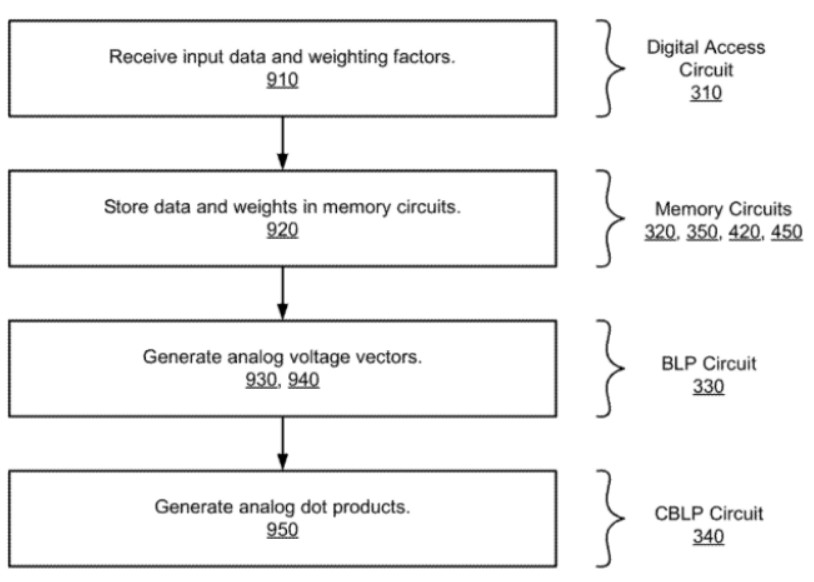
最后,是这种用于模拟内存中神经网络处理的方法的流程图,如上图所示,可以看出,这种方法包括了多个阶段和子过程,分别对应着上述的系统架构来实现。首先,用于模拟内存中神经网络处理的方法通过数字访问电路从CPU中接收输入数据和加权因子而开始运算。
接着,将输入数据存储在第一存储电路中,并将加权因子存储在第二存储电路中,存储电路用于模拟内存计算。其次,由第一存储电路生成模拟电压值,有第二存储电路生成模拟电压值的第二序列。最后,再由交叉位线处理器计算一系列的模拟点积,从而完成整个运算过程。
以上就是英特尔发明的混合处理架构的人工智能芯片,通过将CPU与模拟内存AI处理器相耦合,从而达到加速神经网络运算的目的。这种技术特别适用于AI平台,例如在智能家居控制系统、机器人、虚拟助手等方面均可以发挥重要的作用。
关于嘉德
深圳市嘉德知识产权服务有限公司由曾在华为等世界500强企业工作多年的知识产权专家、律师、专利代理人组成,熟悉中欧美知识产权法律理论和实务,在全球知识产权申请、布局、诉讼、许可谈判、交易、运营、标准专利协同创造、专利池建设、展会知识产权、跨境电商知识产权、知识产权海关保护等方面拥有丰富的经验。
责任编辑:tzh
-
处理器
+关注
关注
68文章
19523浏览量
231768 -
芯片
+关注
关注
458文章
51526浏览量
429491 -
AI
+关注
关注
87文章
32330浏览量
271431 -
人工智能
+关注
关注
1799文章
48047浏览量
241946
发布评论请先 登录
相关推荐
端侧 AI 音频处理器:集成音频处理与 AI 计算能力的创新芯片
中微公司发明专利再获中国专利奖殊荣
笃行不怠,踔厉奋发,华普微又一科技成果获发明专利授权

内存和微处理器的互联演变
芯启源取得GNSS有源功分器发明专利证书
微处理器与CPU的关系
ARM处理器和CPU有什么区别
盛显科技:拼接处理器为什么要配置混合矩阵?

村田起诉国产电感龙头顺络电子侵犯发明专利

东软载波全资子公司获得一项发明专利
艾佛光通创新实力显著,再获美国发明专利授权
凯米斯科技发明专利家族再添一员

中国人工智能发明专利企业排行榜(TOP50)






 工商网监
工商网监
评论