 如何通过机器学习来理解情绪划分,保持积极心态
如何通过机器学习来理解情绪划分,保持积极心态
“思考再思考,然后采取行动”,这样的流程是不是听起来很熟悉?大多数人都是这样做的。
然而,这个思考流程很可能是一把双刃剑:在一些情形下,结果可能积极有用,但在另一些情形下,结果可能有害,甚至反噬自身。后者是我们都希望避免的。为了清晰了解情绪的划分,我编写了这个机器学习(ML)程序。
隔离阶段让我有机会探索自我并审视自己的思路。我不是一个沉思者,但是总会陷入纷乱的思绪之中,每当这时,我都需要理清思路。因此我要创建一个可以分析我的思考过程的ML模型。我用KNN算法判断应该避免的情绪,并通过可视化技术将我的情绪以图形展示,使我清晰地一览全貌。下面是我的做法:
作为开始,我创建了一个有不同想法的数据集;
使用KNN算法;
使用可视化技术;
最后,我学会了分割思考过程。
创建数据集
数据集由九种情绪(特征)组成:沮丧,悲伤,卑微,哭泣,痛苦,困惑,快乐,振奋和坚定。我将它们分为三类(标签):积极,消极和中立。另外,我根据标签对这九种情绪/特征均按1-10的标准进行了评分。于是我创建了共150个案例。这是数据集的前几行:
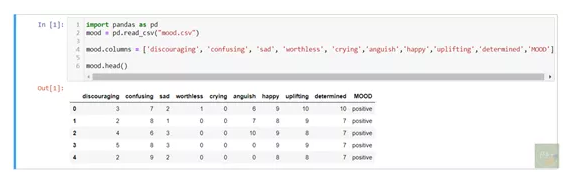
使用KNN算法
在开始下一步之前,首先需要掌握一些监督式学习的ML基本术语:
为了训练、测试和评估一个模型,我们使用一系列案例;
这些案例包括与模型相关的特征和标签值;
特征是用于训练算法的基础值;
一旦训练部分结束,算法就能预测测试特征的正确标签值。
目标是正确预测标签。因此,受训算法的精度应该很高。如果不高,应使预测的标签值和原本标签之间的误差最小化。有了这些基础知识,让我们接着来了解KNN算法。KNN是监督式的机器学习算法,“K”是待分类点邻近值的个数 (例如,K=1、2、3等)。
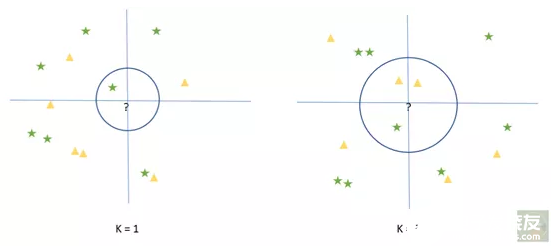
左图中,KNN会将“?”归类为绿色星星,因为它最近。同样,在右例中KNN会将“?”归为黄色三角,因为这些三角形是最接近的多数情况。
新案例与已知案例之间的接近程度,可以使用任意距离函数,如欧几里得尺度和明可夫斯基尺度等体现。因此称之为最邻近。这样,KNN算法对新案例进行了分类。在这种特定模式中,KNN要正确预测各个情绪的分类。预处理所有数据后,我使用了KNN算法,然后计算出准确度为98.6%。这是显示相同的代码段:
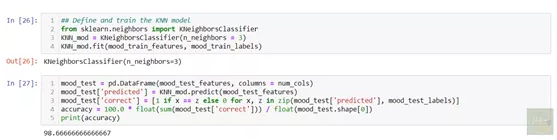
使用可视化技术
我用数据可视化进行了分类,图表更便于理解,并创建了一种解决方案,用来预测我应该避免什么样的情绪才能保持一个积极的心态。这个技术将帮助我分辨标签类别(积极、消极和中性),为此我使用了“箱形图”。
结果
KNN生成的图表显示:
沮丧:算法将该特征归类为消极,这是显而易见的。但值得注意的是,在消极和中立之间有小部分的重叠。同时消极与中性界限也非常细微。这表明沮丧的情绪在某种程度上能够激励自己取得积极成果。综合考虑后,它被归类为消极标签。
困惑:这项结果很有意思,算法将其标记为积极。在分析之前,我曾避免自己有困惑情绪。也许这些摇摆不定的情绪也能产生积极的结果,也许它们给了我们时间来衡量形势的正反面。
悲伤:毫无疑问,这类情绪注定会产生消极的结果。
自卑:有时候头脑中会出现一些随机的想法。它们没有来由没有依据。算法将这些情绪归类为中性。
哭泣:与悲伤特征类似,该特征也被归为消极。但我认为它可能也有中立的一面,因为哭泣可以帮助平衡情绪。但如果依据图表来给定标签,很可能将其归类为积极而非中性。总体来看,它会引发消极情绪。
痛苦:根据模型的预测,痛苦是导致心情不好的最重要特征。因此,它是极其消极的。
振奋:KNN预测这个特征对我有益。但是,该图显示中性和消极情绪略有重叠。此外,令人吃惊的是,如果我们仅考虑这两个标签,消极标签的影响要比中性标签大得多。
坚定:该特征非常有趣。结果之间几乎没有任何区别,很难立即做出诠释,但是使用箱形图可以轻易地理解这一点。
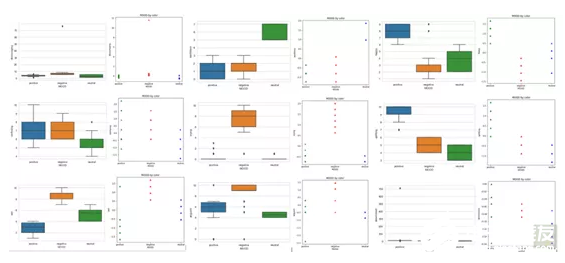
箱形图提供了详尽的图示。图示清晰易懂,它们根据特征或思想给出了三种不同情绪或标签的清晰区分。它描绘的结果与KNN图或多或少相同,但它提供了更好的解释:
坚定:尽管看起来这一特征明显会被归类为积极,但是KNN图表根据数据显示了这三个标签之间的相似性,这种相似性可能会产生误导。看看箱型图你就会发现,积极的结果只比另外两个高一点。因此,该特征被归类为积极标签。
快乐:毋庸置疑,此特征为积极标签。但是,它对中性的四分位数远大于正数,如果仅考虑中性和负数,则中性要高于两者。
这个项目非常有趣。起初,我以为分类结果是简单且显而易见的,但完成后,我才意识到这不仅仅是个分类。一个ML程序不仅能预测人类可以轻松完成的特定任务,还可以对数据集深入分析。
虽然这只是仿人智能的开始,但却非常有趣,也许这就是‘机器学习’命名的由来。
责编AJX
-
算法
+关注
关注
23文章
4615浏览量
93001 -
应用程序
+关注
关注
37文章
3277浏览量
57738 -
机器学习
+关注
关注
66文章
8422浏览量
132743
发布评论请先 登录
相关推荐
什么是机器学习?通过机器学习方法能解决哪些问题?

eda在机器学习中的应用
具身智能与机器学习的关系
【「时间序列与机器学习」阅读体验】时间序列的信息提取
【《时间序列与机器学习》阅读体验】+ 时间序列的信息提取
【「时间序列与机器学习」阅读体验】+ 简单建议
【「时间序列与机器学习」阅读体验】全书概览与时间序列概述
机器学习算法原理详解
深度学习与传统机器学习的对比
请问PSoC™ Creator IDE可以支持IMAGIMOB机器学习吗?
freertos系统如何划分任务?

机器学习怎么进入人工智能
机器学习8大调参技巧





 工商网监
工商网监
评论