 做芯片要软硬结合
做芯片要软硬结合
2016 年,第一颗基于可重构计算的人工智能芯片诞生于清华。该成果曾发表在《IEEE 固态电路期刊》,《麻省理工科技评论》也报道过该芯片。
这是清华可重构计算实验室 “十年磨一剑” 的成果。2006 年起,清华开始研究可重构计算并成立实验室。
2018 年,该实验室开始走向产品化,并成立清微智能公司。两年来,公司已在语音识别、视觉识别等领域研发出规模化应用产品,并和阿里巴巴等互联网巨头建立合作。如今,清微智能将最新技术运用于 AI 编译工具链中,并服务于其量产芯片 TX5 系列中,通过编译优化,全球首款多模态智能计算芯片TX510 用于人脸识别时,其处理速度能够提升一倍。
DeepTech 近日联系到清微智能首席科学家、清华大学微电子与纳电子学系教授尹首一,就该公司的主要产品、和他本人近日以通讯作者发表的新论文进行了深度交流。
自 2018 年以来,清微智能针对终端产品的语音和视觉两大应用场景,量产出货两款芯片产品:超低功耗的智能语音 SoC 芯片 TX210,已应用至多款 TWS 耳机、电子产品及多种智能家居产品中;TX510 芯片于 2020 年 7 月实现量产,在金融支付、智能安防、工业机器人、航空等领域也已分批交付客户,出货量已超十万片,并承担多个国家重大项目的建设。
图|TX 510 应用领域
以清微智能的 TX510 智能视觉芯片系列为例,该芯片的休眠功耗为 10uW、支持中断唤醒,冷启动下的人脸检测识别时间小于 100ms,典型工作功耗为 350mW,算力达 1.2T (Int8)/9.6T (Binary),AI 有效能效比达 5.6TOPS/W。
TX510 还拥有可重构 AI 引擎,其支持 AlexNet、GoogleNet、ResNet、VGG、Faster-RCNN、YOLO、SSD、FCN 和 SegNet 等主流神经网络,可实现人脸识别、物体识别和手势识别等功能,适用于 AIoT、智能安防、智能家居、智能穿戴、智能制造等领域。
TX510 内置 3D 引擎,支持 3D 结构光、TOF(Time of flight,飞行时间)和立体视觉,误识率千万分之一的情况下识别率大于 90%。
在接口方面,TX510 支持市面上主流的视频接口、存储接口和通用接口,可保证产品兼容性。
尽管从硬件层面芯片性能已经取得了较大进步,但尹首一告诉 DeepTech,业界向来有一个共识,光有芯片架构还不够,编译工具和开发工具等软硬件体系也必须做好。否则,很难完全把硬件功能的优势发挥出来。
在软件上面,其团队已经有新进展。
做芯片要软硬结合
在近日的第 16 届 ACM/IEEE 国际嵌入式系统会议 上,清华微电子所魏少军、尹首一教授团队的论文《面向神经网络处理器的非规则网络结构高效调度技术》(“Efficient Scheduling of Irregular Network Structures on CNN Accelerators”) 获得最佳论文奖。
尹首一表示,这是中国完成单位首次在 AI 编译优化领域获得国际学术会议最佳论文奖。该研究成果填补了大规模、非规则神经网络编译映射这一技术空白,可大幅提升神经网络处理器的计算性能。
该成果解决的痛点在于,随着 AI 算法的不断普及,以 AIoT 为代表的嵌入式系统应用,给 AI 芯片的性能、功耗、成本、可靠性和可编程性等提出了严格且迫切的需求。为此,基于可重构架构、专用指令集架构、存内计算架构等技术的神经网络处理器应运而生。
相比 CPU/GPU 等传统架构,神经网络处理器可将 AI 算法的计算能效提高 1~2 个数量级,目前其已在移动设备、可穿戴设备、智能传感器等应用场景中获得广泛的应用。
但是,神经网络处理器的应用离不开编译器的支撑,编译器一方面实现了 AI 应用到芯片的自动化部署,另一方面通过优化算法到芯片架构的适配,能为 AI 应用的执行效率带来大幅提升。
当架构设计经过工艺制造并固化为硬件电路后,硬件电路的运算行为则由编译器所生成的机器码来指挥,执行速度和能量开销也将因此而确定。因此,编译器的优化程度是研发 AI 芯片的关键所在。
然而,当前最先进的神经网络模型,仍旧具备不可预测的非规则网络拓扑结构,在编译层面表现为错综复杂的数据流图、和呈指数增长的解空间,而这给编译器中的表达式优化、算子调度、资源分配、循环优化、自动代码生成等关键技术环节带来严峻挑战。
现有的深度学习编译框架,如 TVM、TensorRT 等仅针对网络中的某些特定模式进行优化,它们没有处理任意结构的能力,因此未能有效解决上述难题。
针对上述问题,魏少军、尹首一团队在本次研究中,研发出支持任意网络拓扑结构的端到端深度学习编译框架(下称编译框架),相比同类编译映射方法实现了 1.41-2.61 倍的计算加速。
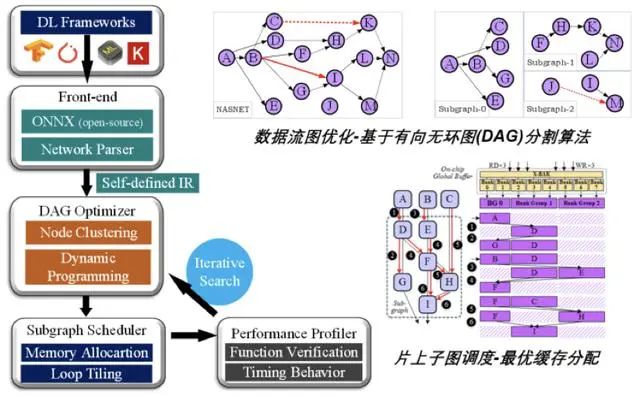
图|支持任意网络拓扑结构的端到端深度学习编译框架
具体来说,本次编译框架有三大创新性技术贡献点。
第一, 针对结构复杂的数据流图,提出了基于计算节点深度聚类的编译方法,该方法可对图结构进行复杂度降维和搜索路径生成,进而可求解到具备全局最优特性的图调度方案,在硬件处理器上表现为多级存储系统间的数据传输开销、与额外计算开销之间的最佳平衡,即推理计算性能达到最优;
第二,针对非规则网络结构导致的解空间指数增长,提出了一种基于回溯搜索和参数匹配的启发式资源分配方法,并对神经网络基本算子在时空域上的分布进行联合优化,从而实现硬件层面上处理器缓存资源利用率最大化;
第三,针对新型网络结构的循环优化问题,该团队推导得出最小循环变换粒度,并在编译框架中建立了最优阵列映射机制,使得嵌套循环的运算与计算资源达到最优匹配。
由于该编译框架的优化方法具备通用性,因此它也能用于专用神经网络处理器以外的其他架构。
对于研究该问题的初衷,尹首一表示,这来自该团队亲身经历的痛点。过去,在开发神经网络处理器时,人们往往只考虑到处理单元阵列的搭建和底层的数据复用等问题。而对于神经网络算法编译,由于当时的模型结构简单、调度空间有限,仅仅采用常规编译优化就已足够。
然而,在面对近年来基于神经架构搜索(NAS)等方法所生成的复杂网络结构时,之前的设计范式不再能提供具备接近最优性能的解决方案,从而大大制约了算力的发挥。因而该团队认识到,必须要有针对性的软件编译工具,才能对新型 AI 应用进行充分的优化和加速。
尹首一告诉 DeepTech,在编译方面他们并非 “新人”。他和团队十多年来一直研究通用可重构处理器编译问题,已具备较为深厚的研究基础,因而在面对神经网络编译这一新问题时,能迅速把握问题本质,从而得以快速完成研究。
据他介绍,目前由其担任首席科学家的清微智能,已经将该论文的技术发明运用在 AI 编译工具链中,并已服务于量产芯片 TX5 系列中。对终端客户而言,这意味着可用同样的费用买到更多的算力。例如,通过编译优化,TX510 芯片用于人脸识别时,其处理速度能够提升一倍。
目前,清微智能的 AI 编译工具链还在不断升级优化中,旨在使实际运行中的神经网络处理器逼近其理论算力上限。
AI 芯片公司应 “软硬” 结合
尹首一认为,和所有初创公司一样,AI 芯片企业要想构建成功的商业模式,在市场竞争中站稳脚跟,就得扎实细致地研究客户实际需求。
当前,AI 芯片的客户多数是整机和应用开发相关企业,这类客户主要面向算法和应用来开发神经网络模型,他们急需的是将生成的模型、便捷高效地在硬件设备上进行部署,因此他们不太关心硬件的底层架构和编译细节。
但是,芯片公司光有先进的硬件和架构是不够的,因为这无法让客户快速用起来,也无法将硬件算力转化为可观的计算性能。这时,AI 芯片公司就得提供软硬件全栈式解决方案。参照英伟达在图形加速领域的成功经验,有两点值得其他公司学习:其一是先进的 GPU 硬件架构,其二则是 GPU 开发工具链的成熟和完善。
目前,尹首一把主要精力集中在前沿研究上,这些研究成果不断支撑着产品的竞争优势。以清微智能 AI 编译工具链为例,它集成了模型自动量化、定点训练、通用算法计算和网络调度映射等多方面的先进技术,可高效处理神经网络和及其他 AI 算法,并且兼容主流的深度学习框架,因而实现了从应用算法、到可重构计算硬件的端到端部署。
通过这套 AI 工具链,开发者可在不改变编程习惯的情况下,快速高效地部署 AI 算法。以已经量产出货的视觉智能芯片 TX510 为例,开发者可以仅仅通过调用功能级 API,就实现包含剪枝参数和权值位宽参数在内的最优模型压缩策略,以及包括数据流图优化、算子时空域映射在内的最优调度结果。
尹首一最后总结到,和操作系统一样,编译器也是核心基础软件,它是一切可编程芯片的灵魂,应当受到国内公司的更多重视。做 AI 芯片的公司,应当从开发伊始就对软硬件两方面的技术路线进行充分布局,这样才能走得更远。
-End-
原文标题:AI芯片公司,架构、编译两手都要硬!搭载清华最新深度学习编译研究成果的芯片已商用
文章出处:【微信公众号:DeepTech深科技】欢迎添加关注!文章转载请注明出处。
责任编辑:haq
-
芯片
+关注
关注
456文章
50908浏览量
424484 -
AI
+关注
关注
87文章
31028浏览量
269381 -
人工智能
+关注
关注
1792文章
47373浏览量
238875
原文标题:AI芯片公司,架构、编译两手都要硬!搭载清华最新深度学习编译研究成果的芯片已商用
文章出处:【微信号:deeptechchina,微信公众号:deeptechchina】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
芯片为什么要进行封装?
瑞萨电子与吉利汽车联合举办汽车主控芯片软硬解耦能力提升训练营

结合芯片行业现状,数字芯片设计什么方向最值得投身?

地平线征程家族出货量突破700万
使用NE555芯片做MOS管延时的控制芯片,带载启动的时候,定时器工作在打嗝状态,MOS管不能正常打开,怎么解决?
香橙派与昇思MindSpore合作提速,软硬结合助力开发者构建创新AI应用

Orin芯片与边缘计算结合
线路板厂一文详解PCB软硬结合板优缺点
紫光同芯重磅发布两款芯片,未来重点布局人工智能等领域

激光焊锡技术在R-FPC线路板制造领域的应用


官宣10家首批量产合作车企,地平线征程6发布即爆款







 工商网监
工商网监
评论