 关于Dropout、BN及数据预处理方案
关于Dropout、BN及数据预处理方案

一、随机失活(Dropout)
具体做法:在训练的时候,随机失活的实现方法是让神经元以超参数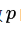 的概率被激活或者被设置为 0。如下图所示:
的概率被激活或者被设置为 0。如下图所示:
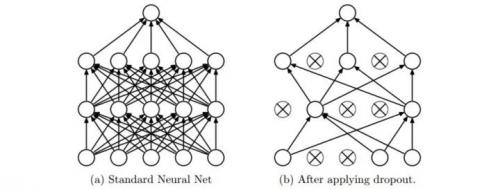
Dropout 可以看作是 Bagging 的极限形式,每个模型都在当一种情况中训练,同时模型的每个参数都经过与其他模型共享参数,从而高度正则化。在训练过程中,随机失活也可以被认为是对完整的神经网络抽样出一些子集,每次基于输入数据只更新子网络的参数(然而,数量巨大的子网络们并不是相互独立的,因为它们都共享参数)。在测试过程中不使用随机失活,可以理解为是对数量巨大的子网络们做了模型集成(model ensemble),以此来计算出一个平均的预测。
关于 Dropout 的 Motivation:一个是类似于性别在生物进化中的角色:物种为了生存往往会倾向于适应这种环境,环境突变则会导致物种难以做出及时反应,性别的出现可以繁衍出适应新环境的变种,有效的阻止过拟合,即避免环境改变时物种可能面临的灭绝。还有一个就是正则化的思想,减少神经元之间复杂的共适应关系,减少权重使得网络对丢失特定神经元连接的鲁棒性提高。
这里强烈推荐看下论文原文。虽然是英文的,但是对于更深刻的理解还是有很大帮助的!
二、图像数据的预处理
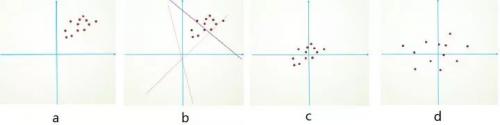
为什么要预处理:简单的从二维来理解,首先,图像数据是高度相关的,假设其分布如下图 a 所示(简化为 2 维)。由于初始化的时候,我们的参数一般都是 0 均值的,因此开始的拟合 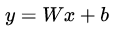 ,基本过原点附近(因为 b 接近于零),如图 b 红色虚线。因此,网络需要经过多次学习才能逐步达到如紫色实线的拟合,即收敛的比较慢。如果我们对输入数据先作减均值操作,如图 c,显然可以加快学习。更进一步的,我们对数据再进行去相关操作,使得数据更加容易区分,这样又会加快训练,如图 d。
,基本过原点附近(因为 b 接近于零),如图 b 红色虚线。因此,网络需要经过多次学习才能逐步达到如紫色实线的拟合,即收敛的比较慢。如果我们对输入数据先作减均值操作,如图 c,显然可以加快学习。更进一步的,我们对数据再进行去相关操作,使得数据更加容易区分,这样又会加快训练,如图 d。
下面介绍下一些基础预处理方法:
归一化处理
均值减法(Mean subtraction):它对数据中每个独立特征减去平均值,从几何上可以理解为在每个维度上都将数据云的中心都迁移到原点。(就是每个特征数据减去其相应特征的平均值)
归一化(Normalization);先对数据做零中心化(zero-centered)处理,然后每个维度都除以其标准差。
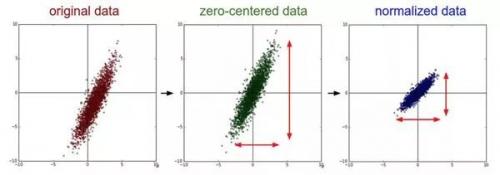
(中间零中心化,右边归一化)
PCA 和白化(Whitening)
白化(Whitening):白化操作的输入是特征基准上的数据,然后对每个维度除以其特征值来对数值范围进行归一化。该变换的几何解释是:如果数据服从多变量的高斯分布,那么经过白化后,数据的分布将会是一个均值为零,且协方差相等的矩阵
特征向量是按照特征值的大小排列的。我们可以利用这个性质来对数据降维,只要使用前面的小部分特征向量,丢弃掉那些包含的数据没有方差的维度。这个操作也被称为主成分分析( Principal Component Analysis)简称 PCA)降维
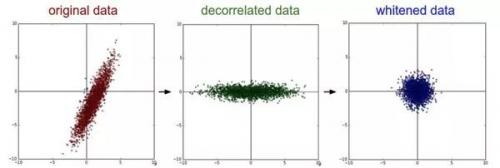
(中间是经过 PCA 操作的数据,右边是白化)
需要注意的是:
对比与上面的中心化,与 pca 有点类似,但是不同的是,pca 把数据变换到了数据协方差矩阵的基准轴上(协方差矩阵变成对角阵),也就是说他是轴对称的,但简单的零中心化,它不是轴对称的;还有 PCA 是一种降维的预处理,而零中心化并不是。
常见错误:任何预处理策略(比如数据均值)都只能在训练集数据上进行计算,算法训练完毕后再应用到验证集或者测试集上。例如,如果先计算整个数据集图像的平均值然后每张图片都减去平均值,最后将整个数据集分成训练 / 验证 / 测试集,那么这个做法是错误的。应该怎么做呢?应该先分成训练 / 验证 / 测试集,只是从训练集中求图片平均值,然后各个集(训练 / 验证 / 测试集)中的图像再减去这个平均值。
三、Batch Normalization

原论文中,作者为了计算的稳定性,加了两个参数将数据又还原回去了,这两个参数也是需要训练的。说白了,就是对每一层的数据都预处理一次。方便直观感受,上张图:
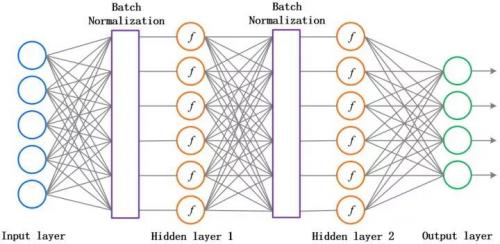
这个方法可以进一步加速收敛,因此学习率可以适当增大,加快训练速度;过拟合现象可以得倒一定程度的缓解,所以可以不用 Dropout 或用较低的 Dropout,而且可以减小 L2 正则化系数,训练速度又再一次得到了提升。即 Batch Normalization 可以降低我们对正则化的依赖程度。
还有要注意的是,Batch Normalization 和 pca 加白化有点类似,结果都是可以零均值加上单位方差,可以使得数据弱相关,但是在深度神经网络中,我们一般不要 pca 加白化,原因就是白化需要计算整个训练集的协方差矩阵、求逆等操作,计算量很大,此外,反向传播时,白化操作不一定可导。最后,再次强烈直接看 BN 的相关论文,有很多细节值得一看!
编辑:hfy
-
神经网络
+关注
关注
42文章
4842浏览量
108177
发布评论请先 登录
机器学习为什么需要数据预处理

C预处理与C语言基本数据类型
C语言的编译预处理
Web使用挖掘中的数据预处理模块、实现方法及发展前景




评论