 深度解析Neoverse V1对Arm的重要意义
深度解析Neoverse V1对Arm的重要意义

2018年10月,Arm首次宣布推出面向云到边缘基础设施产品Neoverse及其初步路线图,并承诺平台效能30%的年增长率指标将持续到2022年及以后。
根据Neoverse平台PPA设计原则,N系列强调性能、功率、面积得到同等考量,擅长可扩展;E系列主要关注效率,对于网络流量和数据应用程序非常有效,在功耗和面积的缩减上进行优化;V系列旨在提供最佳性能,需要添加更大的缓存、窗口和队列,相对来说会消耗更多面积和功耗。如果客户更看重线程需求,N系列就比较合适,假若客户需要高性能计算工作负载,V系列就能提供更大的价值,这完全取决于客户在功耗、性能、面积上的需求与配置。

图1:Neoverse平台PPA设计原则
最早的“Cosmos”平台基于16nm工艺,采用A72、A75核心,在当时公布的路线图中,Arm就提出了每年每代产品30%的性能提升目标。2019年初,N1和E1平台公布,相比“Cosmos”,N1单线程性能提升了60%,超出预期一倍,云端负载性能提升2.5倍;E1吞吐量性能提升超过2.7倍,吞吐效率提升超2.4倍,计算性能提升超2倍。
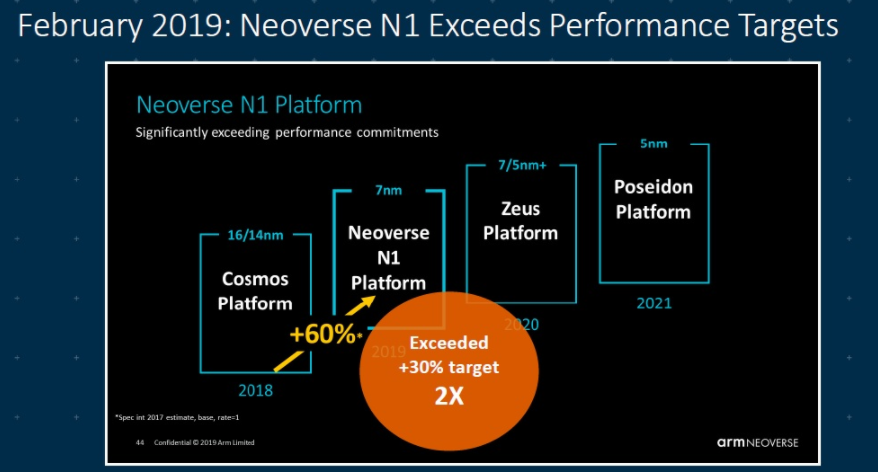
图2:2019年推出的N1平台相比“Cosmos”单线程性能提升了60%
图3和图4分别展示了N1的公开测试数据,以及基于传统架构的机架与基于ArmNeoverse机架的数据对比。可以看出,无论是在存储、移动还是计算数据领域,N1都表现出了优良的性能。而且在同为标准42U机架和12.5KW功率条件下,ArmNeoverse平台提供了更高的整数吞吐量和单线程性能,使得云服务商得以在单个机架上托管更多客户,从而带来更高收入和更多计算周期。
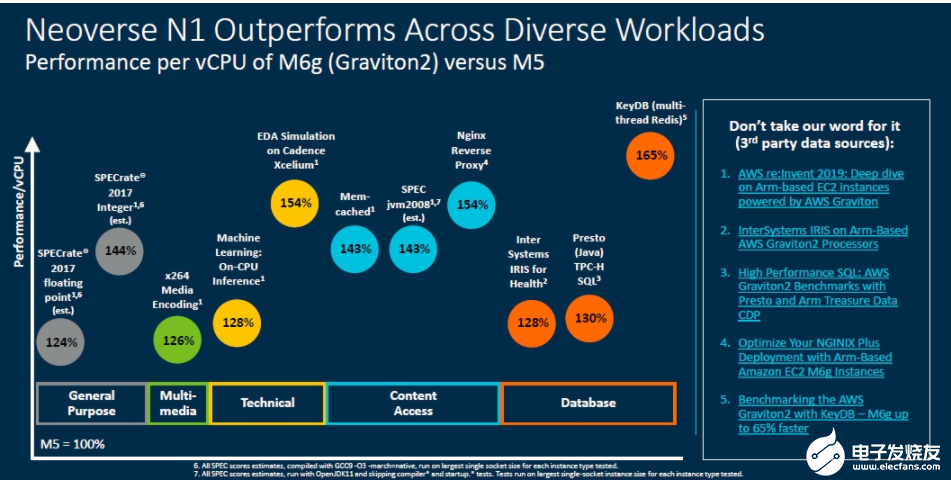
图3:N1性能测试数据

图4:基于传统架构的机架与基于ArmNeoverse的机架对比
开启终极性能之路
两年后,也就是2020年9月,Neoverse家族宣布再度进阶,新增两个全新的平台—NeoverseV1平台以及第二代N系列平台NeoverseN2。日前,Arm基础设施事业部高级副总裁兼总经理ChrisBergey则公开了V1和N2平台的更多产品细节。
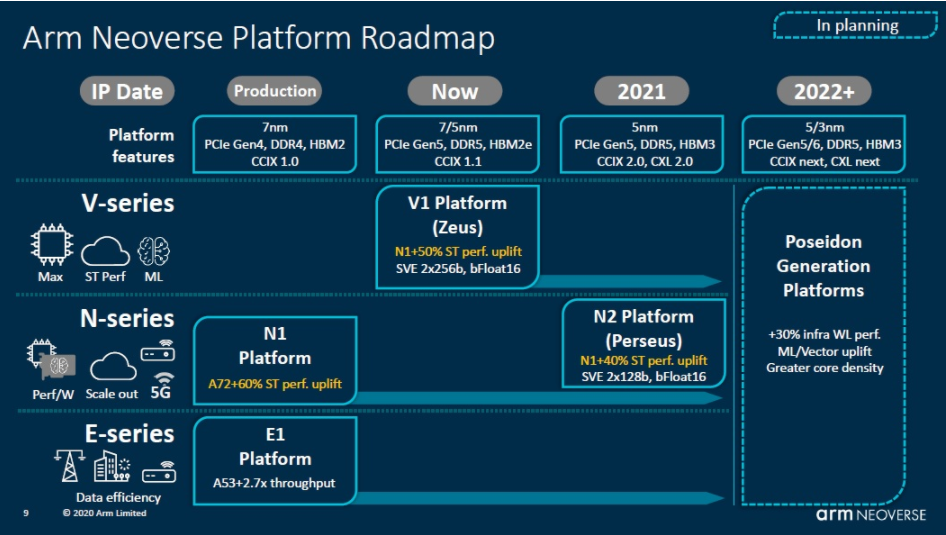
图5:ArmNeoverse平台路线图
NeoverseV1作为V系列的第一个平台,主要面向7nm和5nm工艺而设计,是Arm强调性能优先的新型计算系列的第一个平台。与N1相比,V1支持256位宽度的向量,带来了50%的性能提升、1.8倍的矢量工作负载优化、以及4倍的机器学习工作负载优化,适用于高性能计算、高性能云和机器学习处理等对CPU性能与带宽有更高要求的应用。
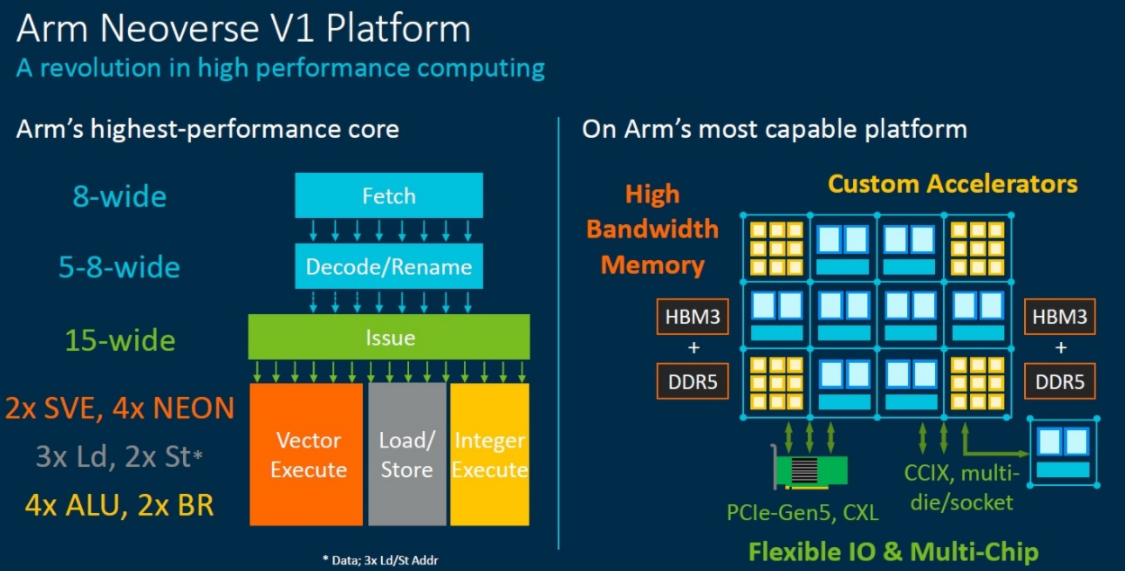
图6:NeoverseV1性能详述
值得一提的是,V1是Arm第一个支持可伸缩矢量扩展(ScalableVectorExtensions,SVE)的处理器平台。SVE可基于未知宽度向量单元的软件编程模型执行单指令流多数据流(SIMD)整数、bfloat16、浮点指令,从而确保软件编码的可移植性与使用寿命,并兼顾高效的执行。

图7:V1是Arm第一个支持SVE的处理器平台
对开发者而言,SVE架构的好处在于能够帮助他们在寄存器宽度之间无缝转换,也就是说,开发者们既可以合并新的宽向量SVE指令,也可以重新使用为较小的寄存器编写的辅助函数。富士通A64FXCPU就是一个很好的例子,在执行SVE代码时,他们可以完全控制SVE电压和频率转换,确保其可以全天全频率运行。
Chris说,Arm现有的SIMD指令集NEON难以对某些代码进行矢量化处理,而SVE可以直接取用相同的代码,并很好地对其进行自动矢量化,相比于NEON,可提升将近3.5倍的处理速度。由于SVE与矢量长度无关,因此相同的代码可以不加修改地在V1上运行。另外,如果在V1上加倍SVE矢量的宽度,对应的处理速度也几乎提速一倍。
当然,SVE也为HPC提供了一种新的高性能且对开发者友好的编程功能。
今年4月,印度电子和信息技术部MeitY宣布其百万兆级高性能计算CPU设计将采用NeoverseV1平台,使之成为继法国芯片初创企业SiPearl和韩国电子通信研究所ETRI之后,第三家公开支持通过NeoverseV1驱动百万兆级高性能计算SoC的Arm合作伙伴。
除此之外,Chris还分享了其他合作伙伴在基础设施市场的最新进展,包括:
. Marvell发布了基于NeoverseN2的OCTEON系列网络解决方案,并预计于2021年底前试产。相较于前一代的OCTEON解决方案,其性能提升高达3倍。
. 甲骨文计划在Oracle云基础设施上采用AmpereAltraCPU,为各种工作负载提供最佳的性价比。
. 由Arm技术驱动的AWSGraviton2通过稳定的增长与区域扩展,正持续快速地扩张其EC2的覆盖。
. 阿里云在即将上线的基于Arm架构ECS实例上完成了测试,结果显示在SPECjbb的测试数据中获得了惊艳的表现,且基于Arm架构运行的DragonWellJDK性能提高了50%。
阿里巴巴首席工程师周经森(KingsumChow)称,公司现有的软件里会有两个考虑的点,一个是有些软件是需要重新编译的,另外一种不需要重新编译,只需要把Javaapplications在JVM(JavaVirtualMachine)上跑好就可以了。过去一年里,双方从JDK8到JDK11,通过OpenJDK,通过阿里巴巴Dragonwell(OpenJDK的一个发行版),就把现有一些Java应用的一些性能提高了50%。
. 腾讯在硬件测试和软件支持方面持续投入,使其在云应用上能采用ArmNeoverse技术。
腾讯专项测试技术中心总监黄闻欣(VictorHuang)表示,去年,腾讯和Arm正式签署了一份合作协议,希望通过合作加速ArmNeoverse技术的测评和适配。之后通过TencentBench测试框架发现,得益于更多可扩展的CPU核心数,Arm服务器比传统的服务器性能表现更强劲。非常值得一提的是,其在AI推理和图片处理领域优势非常明显。
“我们认为单核性能、功效以及对新SVE矢量扩展的支持是合作伙伴选择V1的主要原因。与富士通的A64FX一样,这些设计凸显了高性能计算SoC的发展趋势:即利用SVE、高带宽DDR5和HBM内存以及其他专用处理能力的整合,打造出百万兆级的CPU。”Chris说。
N2被定位为可提供更高性能计算的解决方案,用来满足横向扩展的性能需求,其用例可横跨云、智能网卡(SmartNIC)、企业网络到功耗受限的边缘设备。同时,N2也是第一个基于Armv9架构的平台,在安全性、能耗以及性能方面都有全面的提升。N2面向5nm工艺而设计,支持PCIe5.0和DDR5,通过支持用于高带宽存储器的HBM3以及用于结构的CCIX2.0和CXL2.0来进一步扩展。此外,相比于N1,N2在保持相同水平的功率和面积效率之余,单线程性能提升了40%,在云端上提升1.3倍的NGINX,在5G和边缘应用上提升1.2倍的DPDK数据包处理。
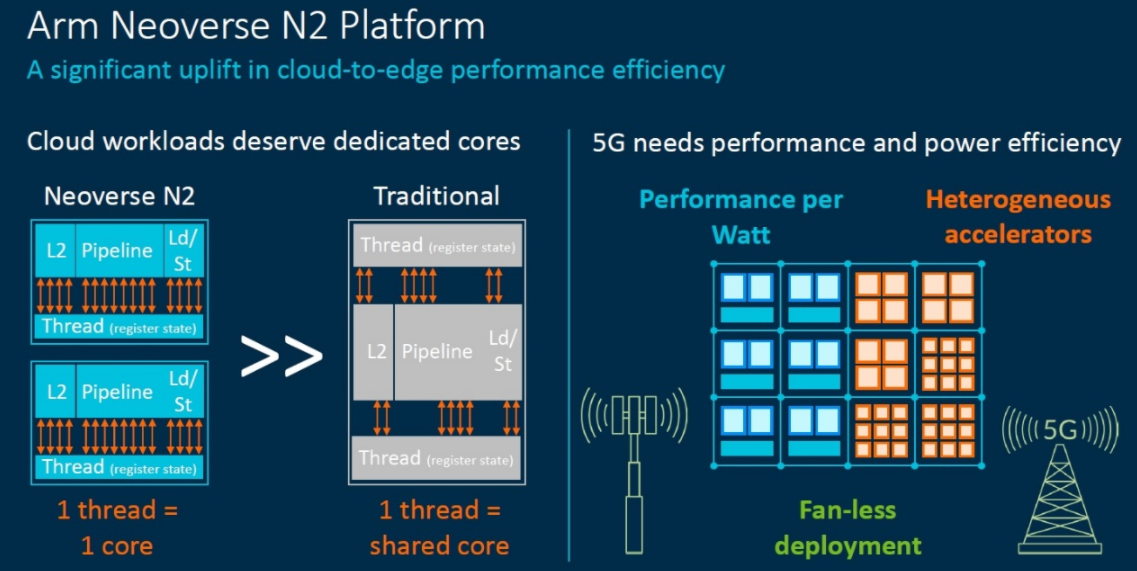
图8:NeoverseN2性能详述
5G无线接入网RAN是N2的一个典型应用。使用5G时,网络资源会被池化为射频单元RU、分布式单元DU和中央单元CU,对于每个单元而言,提供正确的计算以优化性能指标(例如在紧凑功率范围内的带宽和吞吐量)的能力至关重要。尽管网络上层日趋云端化,但下层却需要借助专用处理器和加速器来实现软件和硬件的正确组合。所以除了数据中心,随着网络虚拟化和容器化程度不断提高,加上安全性和存储等功能也被卸载以换取性能和效率,智能网卡或DPU在网络中正变得越来越重要。
NeoverseN2还是第一个具备SVE2功能的平台,该功能可为云到边缘的性能效率带来巨大的提升。在诸如机器学习、数字信号处理、多媒体和5G等广泛应用场景中,SVE2除了带来大幅性能提升外,还带来了SVE具备的编程简易性及可移植性等优势。

图9:SVE2指令集
SVE和SVE2都属于与矢量长度无关的指令集,用户只需编写、编译一次代码,即可在各种多样的硬件上运行,同时还能充分利用可用的矢量带宽。但与SVE加速HPC相比,SVE2将应用场景扩展到ML、DSP、多媒体和5G等更广阔的市场,它融合了NEON丰富的数据操作、逻辑和算术指令集,以及SVE自动矢量化和可扩展性等功能。
下图中,X轴代表芯片级性能,Y轴代表每线程性能。可以看出,在128核/128线程下,N1在芯片级吞吐量和单线程性能方面都达到领先,N2性能更强,代表着最高单芯片性能;V1在96核96线程下拥有最高单线程性能,意味着可以在核心数更少的情况下发挥更好的性能。
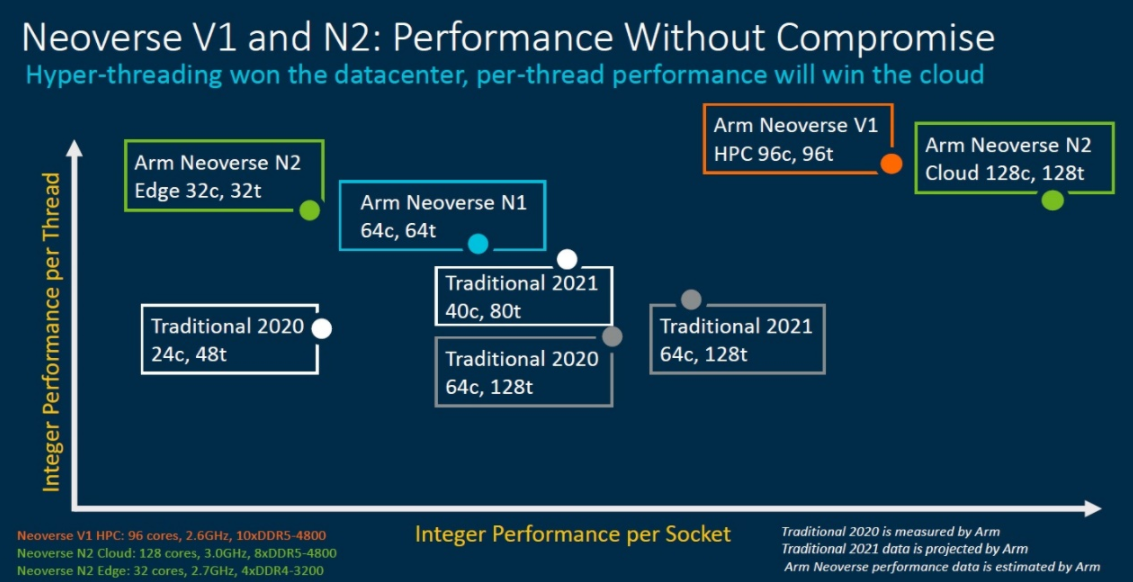
图10:NeoverseN1/N2/V1芯片级性能/单线程性能
除了处理器内核,Arm还为合作伙伴提供可扩展性的交换网,用以支持大量的处理器核。同时,针对加速器的缓存一致性互联(CCIX)与开放互联技术(CXL)的投资则可以确保其生态系统得以快速且高效地推出相关的技术。
基于CMN-600,ArmCMN-700Mesh互连技术在每个矢量上进一步提升了性能——从内核的数量和缓存的大小,到附加内存和IO设备的数量和类型。对于基于V1的HPC平台而言,支持高带宽DDR5和HBM内存系统至关重要,而CMN-700恰好可以实现这一点。
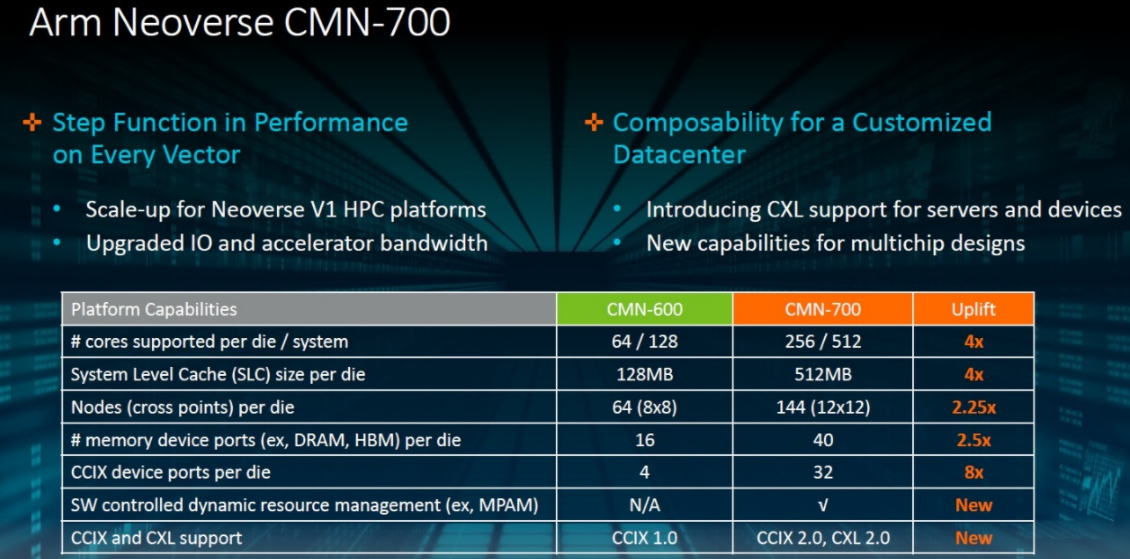
图11:ArmCMN-700Mesh互连技术
CMN-700的另一个关注重点是对多芯片功能的助益,以便为数据中心资源池化的增长提供更多的定制选项。CMN-700中还增加了CXL功能,可为内存扩展和智能一致性加速器,构建主机或端点设备。
多芯片功能的另一项重要升级是,针对传统多插槽设计和新的芯片集或多芯片集成提高性能和优化功能,多芯片集成将为突破传统的硅掩模版限制提供新的机遇,并为紧密耦合的异构计算提供更大的灵活性。
打造“装机即用”的软件生态
软件生态方面,Arm通常将软件分为两种类型:一是云原生软件,二是传统企业级软件。
ChrisBergey说云原生软件是Arm一直以来相当重视的领域,拥有最大的持续集成/持续交付(CI/CD)平台,并在大多数编程语言的生态环境中扮演着核心角色。以AWSGraviton2为例,当前用户在Graviton2上部署的软件将有更多选择,云原生容器安全性、托管持续集成/持续交付、下一代防火墙也得到了持续更新,Graviton2也为Redis、Memcached、Elasticsearch等关键工作负载提供了性能优势。
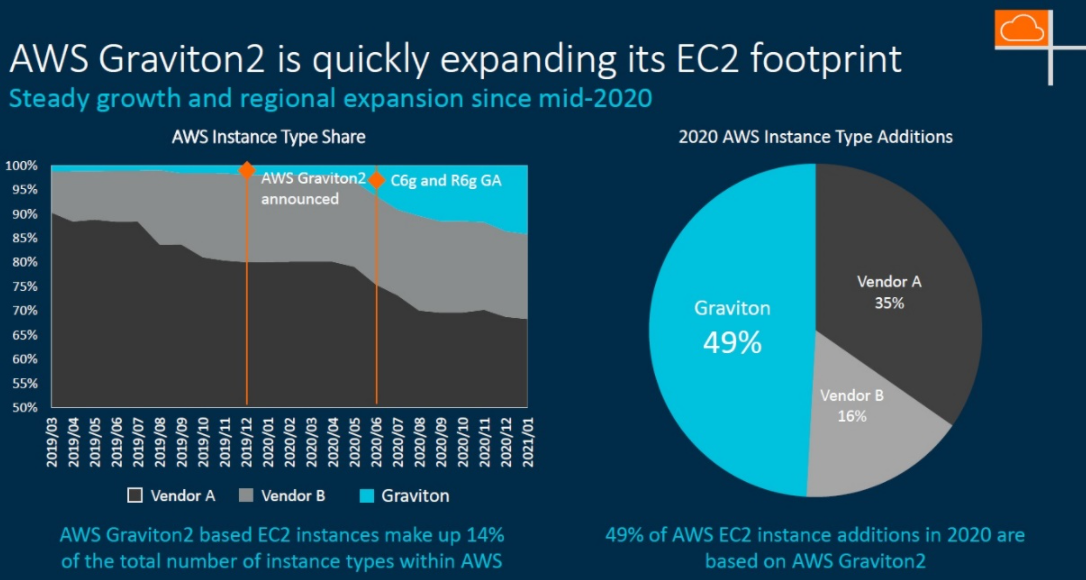
图12:AWSGraviton2性能优势明显
最近,Formula1就表示,相较于其他竞品,C6g和C6gn实例让他们的计算成本降低了40%。因此,Formula与Twitter、Snap、Lyft和Netflix等公司共同成为了Graviton2的用户,他们都通过Graviton2的使用,取得巨大的价格和性价比优势。

图13:构建软件生态
在谈到边缘和物联网基础设施时,Chris认为“异构且多样化”正成为该领域最为显著的特征之一,但由于碎片化,它也可能在跨各种Arm平台上实现云原生堆栈的无缝托管时造成阻碍。
为了应对这一挑战,Arm在2019年推出了ProjectCassini项目,旨在确保在多样化且安全的边缘生态系统中提供云原生体验,并聚焦三个方向进行开展:平台标准和参考实施、边缘安全性以及云原生堆栈。Arm希望能够为软件开发者提供流畅的体验,通过标准、平台安全性与参考实施,让行业伙伴对在Arm平台上部署“装机即用”的软件充满信心。
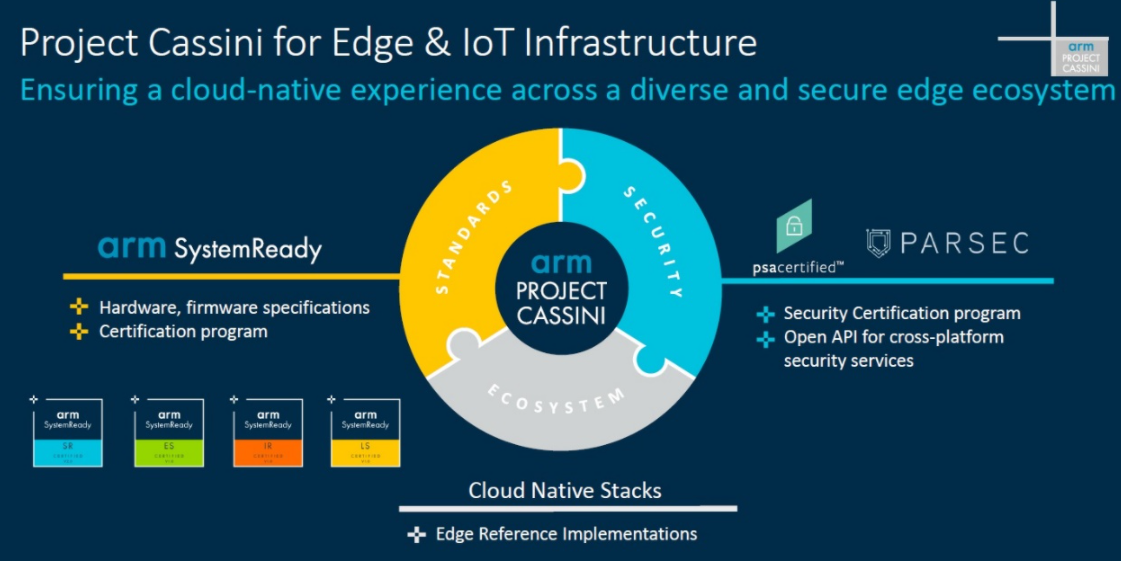
图14:ArmProjectCassini项目
为了凸显Cassini项目的成效,Arm以沃达丰的通用客户端设备uCPE概念验证作为示例:传统的客户端设备已部署为具有紧密耦合的专有硬件和软件的固定功能网络设备,而uCPE的设计用意,就是要通过将软件与硬件解耦,并在开放式商用硬件上运行现代云原生软件,以达到取而代之的目的。Arm与沃达丰及其他合作伙伴共同展示uCPE可以同时运行虚拟化和容器化的网络功能,并且与传统供应商相比可节省大量电力,这能让运营商降低成本、提高能效,并加快用于软件定义广域网SDWAN、防火墙和其他连接服务的网络设备性能。
而在传统企业软件领域,“软件即服务”(SaaS)正成为显著趋势。由于在Arm架构之上能够创造非常有利的软件即服务产品,因此很多独立软件开发商(ISV)开始对Arm表现出浓厚的兴趣,在中国市场尤其显著。目前,包括Xen、KVM、Docker容器以及越来越多的Kubernetes在内的基础软件都已经陆续宣布支持Arm架构,许多初期由Arm推动的开源项目正在变得自主运转。
编辑:hfy
-
ARM
+关注
关注
135文章
9588浏览量
393617 -
物联网
+关注
关注
2950文章
48126浏览量
418366 -
5G
+关注
关注
1368文章
49214浏览量
638997
发布评论请先 登录
STEVAL - ISA114V1:5V、160mA非隔离降压转换器的深度解析
SGMNQ36430:30V单N沟道PDFN封装MOSFET的深度解析
如何在Arm Neoverse N2平台上提升llama.cpp扩展性能
回顾那些具有里程碑意义的Arm架构产品(1)
Arm Neoverse平台集成NVIDIA NVLink Fusion
工业互联网的重要意义
西门子 Veloce CS 助力 Arm Neoverse 计算子系统验证与确认
论高速电主轴动平衡检测的重要意义

Arm Neoverse N2平台实现DeepSeek-R1满血版部署




评论