 为何要精读鸿蒙内核源码?
为何要精读鸿蒙内核源码?
为何要精读内核源码?
每位码农的学职生涯,都应精读一遍内核源码.以浇筑好计算机知识大厦的地基,地基纵深的坚固程度,很大程度能决定未来大厦能盖多高。那为何一定要精读细品呢?
因为内核代码本身并不太多,都是浓缩的精华,精读是让各个知识点高频出现,不孤立成点状记忆,让各点相连成线,线面成体,刻意练习,闪爆大脑,如此短时间内容易结成一张高浓度,高密度的底层网,内核画面越描越清晰,越雕越深刻,不断训练大脑肌肉记忆,将记忆从临时区转移到永久区。跟骑单车一样,一旦学会,即便多年不骑,照样跨上就走,游刃有余。
热爱是所有的理由和答案
因大学时阅读linux 2.6内核痛并快乐的经历,一直有个心愿,如何让更多对内核感兴趣的朋友减少阅读时间,加速对计算机系统级的理解,而不至于过早的放弃.但因过程种种,多年一直没有行动,基本要放弃这件事了.恰逢2020/9/10鸿蒙正式开源,重新激活了多年的心愿,就有那么点一发不可收拾了.
到2021/3/10刚好半年, 对内核源码的注解已完成了70%,对内核源码的博客分析已完成了40篇, 每天都很充实,很兴奋,连做梦内核代码都在往脑海里鱼贯而入.如此疯狂地做一件事还是当年谈恋爱的时候, 只因热爱, 热爱是所有的理由和答案. :P
鸿蒙内核开发者
感谢开放原子开源基金会,致敬鸿蒙内核开发者提供了如此优秀的源码,一了多年的夙愿,津津乐道于此.精读内核源码加注并整理成档是件很有挑战的事,时间上要以月甚至年为单位,但正因为很难才值得去做! 干困难事,方有所得;专注聚焦,必有所获.
从内核一行行的代码中能深深感受到开发者各中艰辛与坚持,及鸿蒙生态对未来的价值,这些是张嘴就来的网络喷子们永远不能体会到的.可以毫不夸张的说鸿蒙内核源码可作为大学C语言,数据结构,操作系统,汇编语言,计算机组成原理五门课程的教学项目.如此宝库,不深入研究实在是暴殄天物,于心不忍,注者坚信鸿蒙大势所趋,未来可期,其必须成功,也必然成功,誓做其坚定的追随者和传播者.
加注方式是怎样的?
因鸿蒙内核6W+代码量,本身只有较少的注释, 中文注解以不对原有代码侵入为前提,源码中所有英文部分都是原有注释,所有中文部分都是中文版的注释,同时为方便同步官方版本的更新,尽量不去增加代码的行数,不破坏文件的结构,注释多类似以下的方式:
在重要模块的.c/.h文件开始位置先对模块功能做整体的介绍,例如异常接管模块注解如图所示:

而函数级注解会详细到重点行,甚至每一行, 例如申请互斥锁的主体函数,不可谓不重要,而官方注释仅有一行,如图所示

另外画了一些字符图方便理解,直接嵌入到头文件中,比如虚拟内存的全景图,因没有这些图是很难理解虚拟内存是如何管理的.

理解内核的三个层级
注者认为理解内核可分三个层级:
普通概念映射级:这一级不涉及专业知识,用大众所熟知的公共认知就能听明白是个什么概念,也就是说用一个普通人都懂的概念去诠释或者映射一个他们从没听过的概念.让陌生的知识点与大脑中烂熟于心的知识点建立多重链接,加深记忆.说别人能听得懂的话这很重要!!! 一个没学过计算机知识的卖菜大妈就不可能知道内核的基本运作了吗? 不一定!在系列篇中试图用鸿蒙内核源码分析(总目录)之故事篇去引导这一层级的认知,希望能卷入更多的人来关注基础软件,尤其是那些资本大鳄,加大对基础软件的投入.
专业概念抽象级:对抽象的专业逻辑概念具体化认知, 比如虚拟内存,老百姓是听不懂的,学过计算机的人都懂,具体怎么实现的很多人又都不懂了,但这并不妨碍成为一个优秀的上层应用开发者,因为虚拟内存已经被抽象出来,目的是要屏蔽上层对它具体实现的认知.试图用鸿蒙内核源码分析(总目录)百篇博客去拆解那些已经被抽象出来的专业概念, 希望能卷入更多对内核感兴趣的应用软件人才流入基础软件生态, 应用软件咱们是无敌宇宙,但基础软件却很薄弱.
具体微观代码级:这一级是具体到每一行代码的实现,到了用代码指令级的地步,这段代码是什么意思?为什么要这么设计?有没有更好的方案?鸿蒙内核源码注解分析试图从细微处去解释代码实现层,英文真的是天生适合设计成编程语言的人类语言,计算机的01码映射到人类世界的26个字母,诞生了太多的伟大奇迹.但我们的母语注定了很大部分人存在着自然语言层级的理解映射,希望鸿蒙内核源码注解分析能让更多爱好者快速的理解内核,共同进步.
编辑:hfy
-
虚拟内存
+关注
关注
0文章
77浏览量
8058 -
鸿蒙系统
+关注
关注
183文章
2634浏览量
66306
发布评论请先 登录
相关推荐
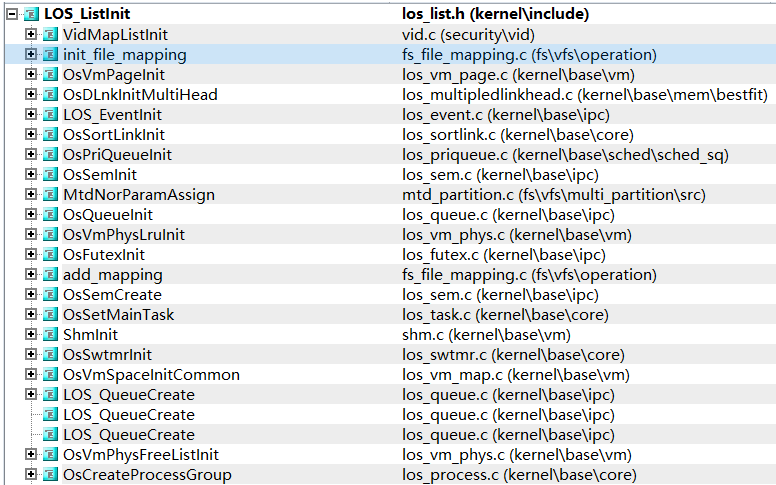
鸿蒙内核源码分析:给HarmonyOS源码逐行加上中文注释
鸿蒙源码分析系列(总目录) | 给HarmonyOS源码逐行加上中文注释
HarmonyOS内核源码分析(上)电子书-上线了
HarmonyOS内核源码分析(中)——电子书上线啦!
HarmonyOS 内核源码分析(下)—电子书上线啦!
鸿蒙内核源码分析(百篇博客分析.挖透鸿蒙内核)
鸿蒙内核进程间为何要通讯?

鸿蒙内核源码分析:鸿蒙内核的每段汇编代码解析

鸿蒙内核源码分析: 虚拟内存和物理内存是怎么管理的






 工商网监
工商网监
评论