 浅谈高速信号的64B/66B编码方式
浅谈高速信号的64B/66B编码方式
很多人可能在想,8B/10B编码主要作用的优化直流平衡,从8bit中插2个bit进去,这样的话最终效果能够使长0或者长1的位数不超过5位,达到很好的效果。那64B/66B编码方式呢?在从64个bit中仅加入2个bit,能够很好的解决长0长1的问题吗?作用似乎只是杯水车薪,2个bit相对于64个bit太少了。但是这种64B/66B的编码方式流行至今,肯定是有它自己的优势所在,其实它和8B/10B编码还是有原理上和算法上的区别的。
当然,如果仅靠这2个bit来实现8B/10B的作用显然不太现实。其实上,这两个bit只是起一个同步头的作用,主要用于接收端的数据对齐和接收数据位流的同步。这两个bit有“10”和“01”两种同步表征方式,“01”表征后面的64个bit都是数据bit,“10”表示后面的64bit是数据和控制信息的混合,其他的“00”或者“11”都表征为错误信息。数据bit用“D”表示,每个数据码是8bit;控制bit用“Z”表示,每个数据码是7bit。其中在“10”这种数据控制信息混合的情况下,后8个bit划分为表征类型域,其后的56bit才是真正的控制信息或数据控制两者的混合。另外“S”表示包开始传送,“T”表示包传送结束,值得注意的是“S”只能在第0和第4字节出现。“T”可以出现在任何的字节。结构图如下所示:
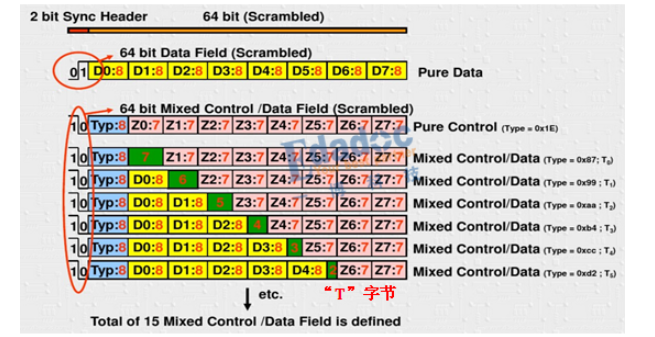
“S”字节

一个传输的例子如下:

那按照上面说的,新加的2个bit只是作为同步,那后面的数据可以如何优化呢?这里有一项区别于8B/10B编码的技术——扰码。
所谓扰码,就是一种将数据重新排列或者进行编码以使其最优化的方法。怎么才能最优化呢?就是使数据bit的“0”和“1”最大程度的达到随机分布,进一步减轻了抖动的码间串扰,提高了数据传输的可靠性。从本质上说,扰码就是为了达到这个目的而在传输数据进入信道传输之前,对其进行的比特层的随机化处理过程。它的方法就是使用上面prbs码型所说到的多项式,关于多项式的选择通常是基于扰码的特性,包括生成数据的随机度,以及打乱连0和连1的能力。从prbs多项式的角度说,其实就是重新生成伪随机码型的过程。
64B/66B的扰码使用的多项式是1+X39+X58。按照前期说的prbs生成器,得到该扰码器的框图如下所示:
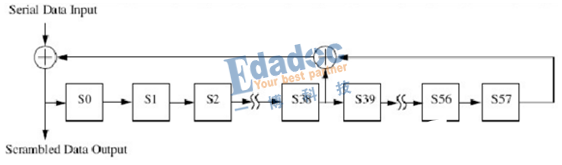
prbs说的第39和第58位的异或运算,然后通过移位寄存器输出的码型结果。当然,前面说了,64B/66B编码的这种扰码方式目标是使数据的“0”和“1”最大程度的随机分布,减小连续出现的情况,因此它可能并不能适用于所有的码型,不像8B/10B编码一样对所有的bit组合都有出色的表现,具体还要看接收器的能力。但是无可否认,它最大的好处是效率比较高,传输冗余的bit只有2位,不像8B/10B编码需要20%的开销。这方面在更高速的传输环境下更具有优势。
编辑:hfy
-
编码技术
+关注
关注
1文章
35浏览量
11071 -
高速信号
+关注
关注
1文章
228浏览量
17711
发布评论请先 登录
相关推荐
Texas Instruments品牌 ADC12DJ5200ALRSHP 耐辐射加固保障 (RHA)、300krad、12 位、双通道 5.2GSPS 或单通道 10.4GSPS ADC
是否可以通过表 8-29. JMODE 8的模式下同时传输3个ADC的数据好让我在SFP+部分进行打包传输给以太网?
N8851A 100GBASE-KR/CR 64b/66b解决方案,带链接训练解码软件数据表
如何将接口的单个输出信号连接到LED外部和RTL代码?
10G EPON 标准IEEE 802.3av V1.3
DS3600 安全监控电路,带有64B电池备份、加密SRAM
安捷伦推出支持以太网64b/66b协议解码和触发应用软件
Xilinx更新“利用千兆位级串行I/O进行设计”课程
Xilinx推出UltraScale FPGA收发器设计
高速串行通信常用的编码方式-8b/10b编码/解码解析
应用于以太网技术的64B/66B编码心得笔记






 工商网监
工商网监
评论