 对高速信号8B/10B编码的初步认识
对高速信号8B/10B编码的初步认识
在高速链路中导致接收端眼图闭合的原因,很大部分并不是由于高频的损耗太大了,而是由于高低频的损耗差异过大,导致码间干扰严重,因此不能张开眼睛。针对这种情况,前面有讲过可以通过CTLE和FFE(包括DFE)均衡进行解决,原理无非就是衰减低频幅度或者抬高高频幅度,从而达到在接收端高低频均衡的效果。
隔了一段时间,不知道大家还记得我们这个约定吗?不管你们记不记得,本人肯定没有忘记哈。现在就把这个关子拿出来讲讲,也就是今天要说的编码方式。说到针对于NRZ数据的编码方式,本人听过的有4B/5B,8B/10B,64B/66B,64/67B,128B/130B,128B/132B编码(可能各位还有其他吧),不同的编码方式针对于不同的信号协议,当然效率也是不一样的。
什么叫效率?在数据包传送的术语叫开销,意思就是除了实际需要的数据之外的一些数据bit,例如冗余校验等。那大家看上面的编码的数值比就知道了,例如8B/10B,要把8bit的实际数据扩展为10B,那开销就是20%,效率就只有80%了,更通俗来说就是增加了20%的非实际数据的传输 。所以一个好的编码方式,除了看它本身的算法优化情况外,还要注重效率高不高。
本人将用两期的篇章主要介绍下8B/10B和64/66B编码方式,其他的主要都是由他们扩展开来的。那介绍完前面总体的情况后,进入本期的主题,8B/10B编码。
首先,为什么要编码?原来的码型有什么不好的地方吗?其中最主要的原因用下面这个图来进行解释:
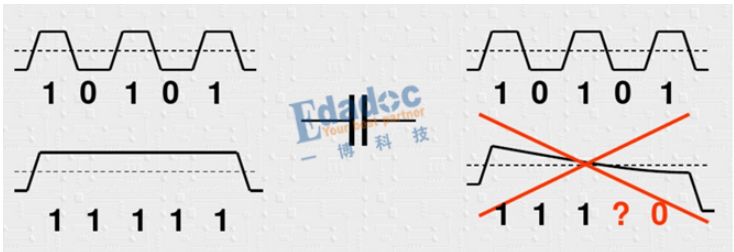
大家看明白了吧,由于我们的串行链路中会有交流耦合电容,我们知道理想电容的阻抗公式是Zc=1/2πf*C,因此信号频率越高,阻抗越低,反之频率越低,阻抗越高。因此上面的情况,当码型是高频的时候,基本上可以不损耗的传输过去,但是当码型为连续“0”或者“1”的情况时,电容的损耗就很大,导致幅度不断降低,带来的严重后果是无法识别到底是“1”还是“0”。因此编码就是为了尽量把低频的码型优化成较高频的码型,从而保证低损耗的传输过去。
上面解释了原因,下面就介绍下这种8B/10B的编码方式的算法。
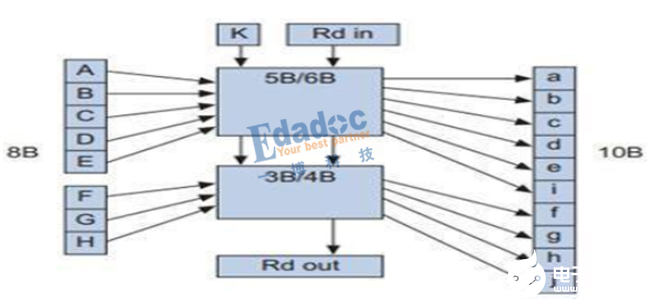
如上图,关于8B/10B编码算法有下面几点需要理解:
1, 低5位(ABCDE)中间加一位,进行5B/6B编码,高三位(FGH)中间加一位,进行3B/4B编码;
2, 编码后的bit仅会出现这三种情况:5个“0”与5个“1”、4个“0”与6个“1”、6个“0”与4个“1”;
3, 有两个术语要知道:不均等性(disparity)和极性偏差(running disparity,RD)。
不均等性是指编码后的码型数据是“1”多还是“0”多,如果是“1”多,则极性偏差RD为-RD,如果是“0”多则为+RD。那定义+-RD有什么意义呢?+-RD代表着同一个码型的两种编码方式。我们本身就是编码的目标就是为了缓解长“0”或长“1”的影响,因此在编码后如果“1”多的话,我们下一次的编码就要把这种码型做一个修正,因此从-RD码型变成+RD码型。如果是“0”和“1”一样多,极性则不用变,如下图:

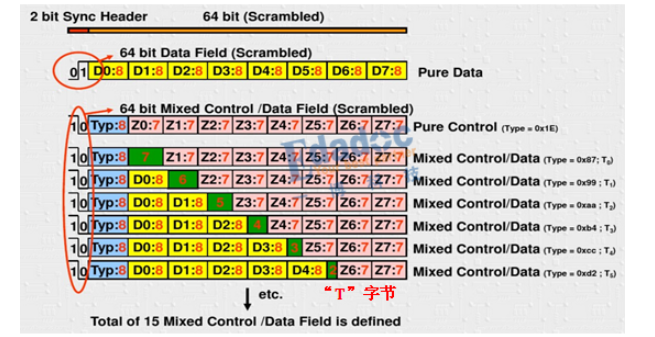
4, 我们怎么知道编码后映射成什么码型呢?因此会有一个专门的编码表,我们只需要在上面找到我们的原始码型,然后就一目了然了。编码表如下所示(部分截图):
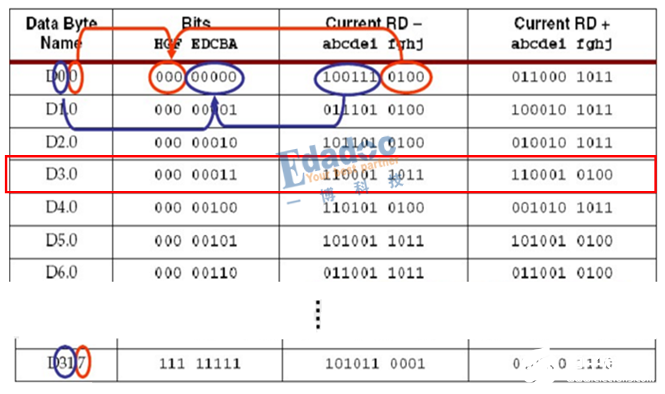
说了那么多,还不如举个例子更直观。
我们以上面的D3.0码型进行仿真验证:
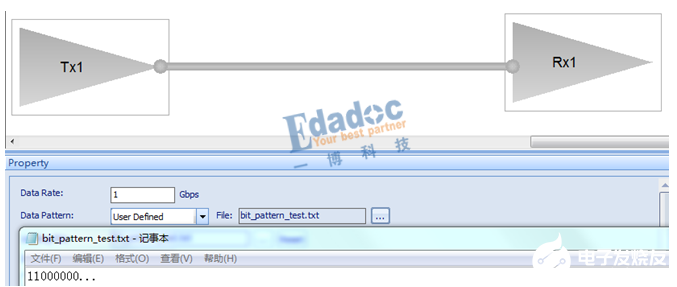
原始的码型如下:
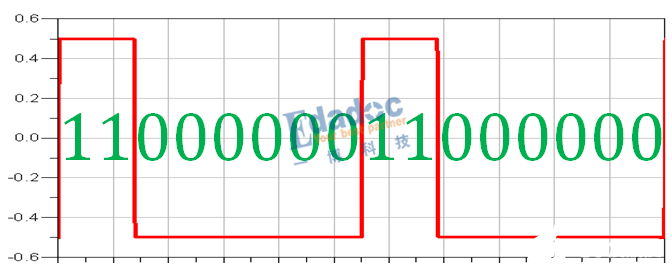
仿真得到8B/10B编码后的码型如下:

对照上面的编码表,结果完全相同,从RD-的模型出发,编码后RD-的码型“1”比较多,因此极性变成RD+的编码码型,接着RD+的编码码型“0”比较多,极性又变回RD-,因此码型就是RD-和RD+之间循环下去。
通过上面的介绍,大家对8B/10B编码有一个初步的认识了吧。
-
阻抗
+关注
关注
17文章
937浏览量
45790 -
编码
+关注
关注
6文章
933浏览量
54739 -
高速信号
+关注
关注
1文章
220浏览量
17674 -
耦合电容
+关注
关注
2文章
154浏览量
19777
发布评论请先 登录
相关推荐
8b10b编码verilog实现
Aurora 8b/10b IP核问题
收发器向导中启用8b/10b编码器的方法是什么?
如何使用Aurora 8B / 10B建立仅传输?
怎么禁用Aurora IP Core 8B / 10B中的时钟补偿功能?
基于FPGA的8B/10B编解码设计
基于PRBS的8B/10B编码器误码率为0设计
基于Virtex-6 的Aurora 8B/10B,PCIe2.0,SRIO 2.0三种串行通信协议分析
浅谈高速信号的64B/66B编码方式
高速串行通信常用的编码方式-8b/10b编码/解码解析





 工商网监
工商网监
评论