 一文解析人脸识别算法的广泛分类及构建块
一文解析人脸识别算法的广泛分类及构建块

作者:Akshat Agarwal,Ipshita Biswas
自远古以来,人脸一直是最直接的识别标准。因此,看到它成为最方便的生物识别技术就不足为奇了。与其他生物识别方法(例如语音,指纹,手形,掌纹)不同,分析面部不需要与所讨论的对象进行积极配合。面部识别可以通过照片,视频或实时捕获来完成。
人脸识别是一个广泛的术语,用于识别或验证照片和视频中的人物。该方法包括检测,对准,特征提取和识别。
尽管存在一些实际挑战,面部识别仍在医疗,执法,铁路预订,安全,家庭自动化和办公室等各个领域得到广泛使用。
在这篇文章中,您将发现以下内容:
什么是面部识别?
人脸识别算法的广泛分类
面部识别系统的各个阶段
面部识别构建块概述
看一下人脸识别SDK
什么是面部识别?
面部识别是一种生物识别技术,该软件使用深度学习算法来分析个人的面部特征并存储数据。然后,该软件将照片,视频或实时捕获的各种面孔与数据库存储的面孔进行比较,并验证身份。通常,该软件可以识别一个人的脸上大约80个不同的节点。节点用作定义个人面部变量的端点。这些变量包括–嘴唇的形状,眼睛,鼻子的长度和宽度以及眼窝的深度。
与其他生物识别技术相比,面部识别的普及是由于这样的事实,即它通常趋于更准确且侵入性最小。
面部识别算法的分类面部识别是一种识别已经在数据库中注册的面部的技术。面部识别系统广泛地涉及两个任务-验证和识别。
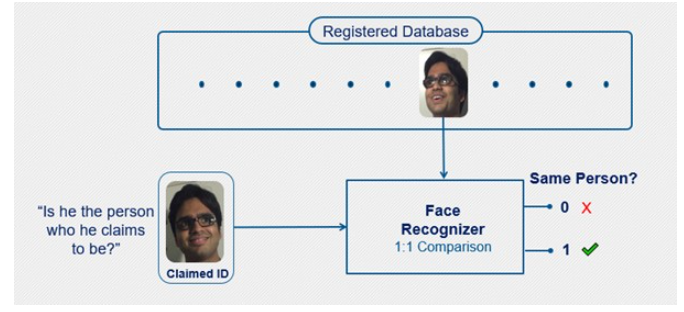
图1:人脸验证
验证旨在回答以下问题:“他是他声称的那个人吗?”当某人声称自己是特定人时,验证系统会在数据库中找到其个人资料。它将人的脸与数据库中显示的个人资料中的脸进行比较,以检查它们是否匹配。这是一个1对1的匹配系统,因为该系统必须将个人的脸部与链接的个人资料中已经存在的特定脸部进行匹配。因此,验证比识别更快,更准确。
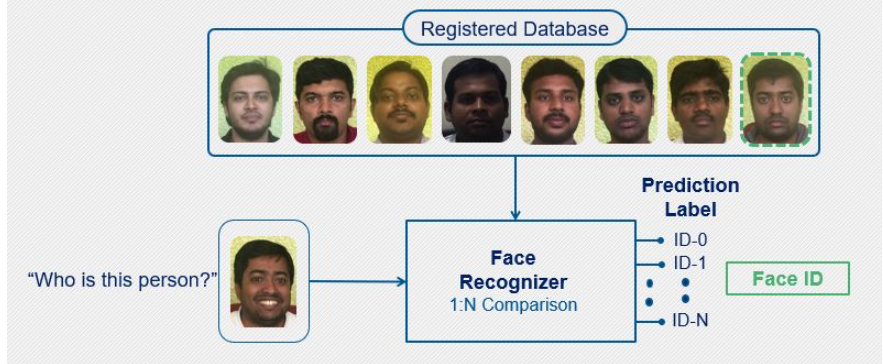
图2:人脸识别
在人脸识别中,系统尝试对照其数据库中存在的所有人脸来检查输入人脸。这是一对一的匹配系统。
面部识别系统的各个阶段
让我们谈谈面部识别系统的两个阶段:注册和识别。
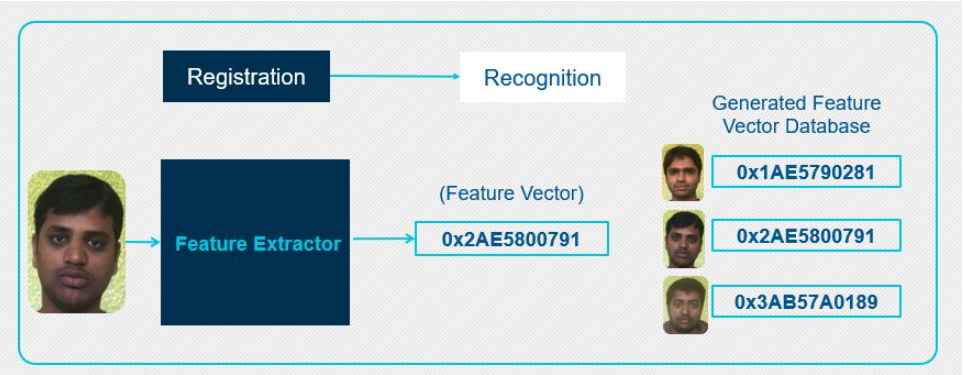
图3:面部识别阶段I
在第一阶段或注册阶段,将注册一组已知的面孔。然后,特征提取器为每个注册人脸生成唯一的特征向量。基于每个脸部的独特脸部特征来生成特征向量。提取的特征向量(对于每个人脸都是唯一的)成为已注册数据库的一部分,可用于将来参考。
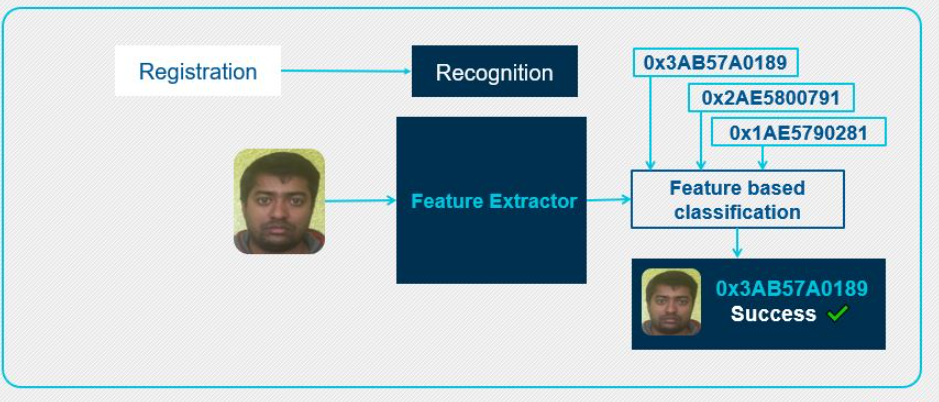
图4:面部识别阶段II
在识别阶段,将输入图像提供给特征提取器以执行面部识别。在此,特征提取器也生成对于输入面部图像唯一的特征向量。然后将该特征向量与数据库中已经可用的特征向量进行比较。“基于特征的分类”块比较输入人脸的人脸特征与数据库的已注册人脸之间的距离。当注册的面部满足匹配标准时,基于特征的分类将返回在数据库中找到的匹配面部ID。
面部识别系统的组成部分
面部识别系统的主要组件是:面部检测,界标检测,生动度检测,面部识别模块(面部识别,面部识别/面部验证)。
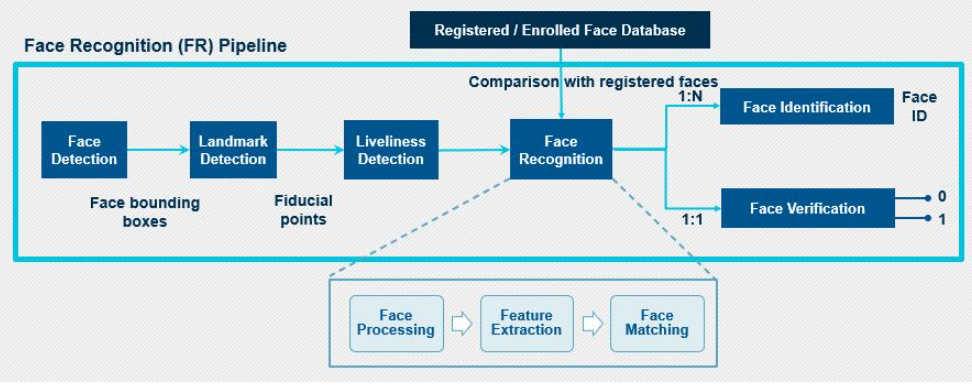
图5:面部识别模块
首先,来自视频流的图像或帧被发送到面部检测模块,在此从输入图像中检测面部。作为输出,它将发送检测到的面部的边界框坐标。这里要注意的是,即使人脸检测器定位了图像的人脸并为每个人脸创建了边框,它也不能保证人脸的正确对齐,并且人脸绑定框会发生抖动。因此,需要面部预处理阶段以获得有效的面部向量。该阶段有助于提高系统的面部检测能力。
人脸预处理在界标检测块中完成,界标检测块可识别参考点在眼睛,鼻子,嘴唇,下巴,下巴等人脸上的位置(也称为基准界标点)。然后,将这些检测到的脸部界标补偿为脸部的空间变化。这是通过识别面部的几何结构并基于各种转换(例如平移缩放旋转)获得规范的对齐方式来完成的。这将输出具有标准化规范坐标的人脸紧边界框。
在将对齐的脸部发送到脸部识别模块之前,必须检查脸部欺骗,以确保脸部是从图像或视频的实时供稿中获取的,并且不是为了获得未授权访问而被欺骗的脸部。活力检测器执行此检查。
然后将图像发送到下一个块,即人脸识别块。在成功完成人脸识别之前,此块执行一系列处理任务。第一步是人脸处理,这是处理输入人脸内类内变化所必需的。这是必不可少的步骤,因为我们不希望面部识别器模块因输入面部图像中存在的姿势,表情,照度变化和遮挡等变化而分散注意力。解决输入面中的类内差异之后,下一个重要的处理步骤是特征提取。上面已经讨论了特征提取器的功能。
面部识别模块的最后一步是面部匹配步骤,在该步骤中,将在最后一步中获得的特征向量与数据库中注册的面部向量进行比较。在该步骤中,计算相似度,并生成相似度分数,根据需要将该相似度分数进一步用于面部识别或面部验证。
面部识别SDK示例
图6:面部识别SDK的第一步
我们将使用PathPartner的可授权面部识别SDK软件解决方案来展示如何实现准确的面部检测和面部识别系统。该SDK包含机器学习和计算机视觉算法,可让您执行六个关键的人脸识别任务。
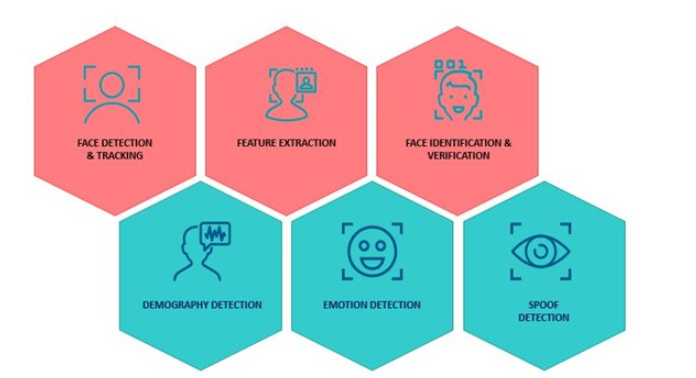
图7:使用SDK执行的六个面部识别任务
SDK有两种变体:
低复杂度型号,型号大小低至10MB,适合内存和处理能力低的终端设备。
高复杂度变量,模型大小为90MB,适用于全方位服务的边缘设备。
该算法在德州仪器(TI),高通(Qualcomm),英特尔(Intel),ARM(ARM),恩智浦(NXP)等一系列嵌入式平台上进行了优化,并且可以在云服务器平台上进一步工作。
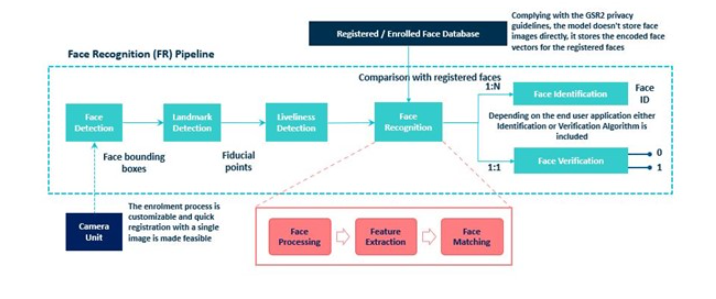
图8:SDK的构建块
开发基于CNN的面部识别系统
与基于非CNN的方法相比,基于CNN的方法更为可取,以便减少应对诸如遮挡和不同照明条件等挑战的精力。识别过程包括以下步骤:
数据采集
公开可用的数据集并未涵盖对面部识别至关重要的所有评估参数。因此,这需要在许多标准和内部数据集上进行详细的基准测试,这些数据集涵盖可用于人脸分析的各种变化。此SDK支持以下变体:姿势,照明,表情,遮挡,性别,背景,种族,年龄,眼睛,外观。
深度学习模型设计
模型的复杂性取决于最终用户的应用程序。该SDK在驾驶员监控系统(DMS)和智能考勤系统中实现。
驾驶员监控系统:为了评估驾驶员的机敏性和实时关注,需要边缘计算。因此,需要鲁棒的,低复杂度的系统。在这里,机器学习模型用于面部检测和界标回归,而浅层和深层CNN模型用于估计和分类。
培训和优化
这些模块在最初准备的数据集中进行了预训练。该解决方案已在各种开源数据集(例如FDDB,LFW和定制的内部开发数据集)上进行了测试。
克服各种挑战
照明变化–为了克服由于照明条件变化而引起的问题,采用了两种方法。一种是使用基于甘特图的方法将RGB转换为类似NIR的图像。另一个正在使用RGB数据训练模型,并在输入端使用NIR图像对其进行微调。
姿势和表情变化–如果可以从非正面视图获得面部图像,则必须从一个或多个可用图像中获得面部图像的规范视图。这是通过基于界标点估计相对于头部角度的姿势变化,然后使用倾斜,拉伸,镜像和其他操作来获得前额路线来实现的。这使得面部识别系统能够输出姿势不变的表示,并显着提高面部识别的准确性。为了克服由于表情差异而产生的影响,在预处理阶段执行面部对齐。
遮挡–目前,SDK正在接受训练以检测蒙面。在这种情况下,模型被训练为仅处理眼睛和额头周围的数据;但是,当系统中注册的人数有限时,这种方法在不受控制的环境(如办公室设置)中可获得最佳结果。
外观变化–发型,老化和使用化妆品的差异会导致个人外观的重大差异。因此,在很大程度上降低了面部识别精度。为了解决此问题,SDK使用了对外观变化具有鲁棒性的表示和匹配方案。
图9:即使没有胡须也可以识别出的脸;PathPartner的面部识别模型可用于从汽车应用程序(例如DMS)到零售应用程序(可能包括客户情感估计)的各个行业。
结论
如今,面部识别被认为是所有生物特征测量中最自然的。深度学习已成为大多数正在开发的面部识别算法的核心组成部分。面部识别算法正在呈指数级增长。根据NIST最近的一份报告,在过去的五年(2013-2018年)中,识别准确性取得了巨大的进步,超过了2010-2013年期间所取得的进步。
尽管存在一些实际挑战,但是面部识别技术已广泛应用于零售,汽车,银行,医疗保健,市场营销等各个行业。面部识别算法除了提高识别人的准确性外,还扩展了其在检测面部表情和行为方面的范围。
编辑:hfy
-
生物识别
+关注
关注
3文章
1222浏览量
54120
发布评论请先 登录
瑞芯微(EASY EAI)RV1126B 人脸98关键点算法识别

人脸识别门禁终端哪家做的比较好

人脸识别身份核验终端的应用场景和硬件要求有哪些?

如何挑选人脸识别终端?人脸识别一体机品牌排行榜


【EASY EAI Orin Nano开发板试用体验】EASY-EAI-Toolkit人脸识别
基于LockAI视觉识别模块:C++人脸识别




选择户外场景的人脸识别门禁一体机,需要具备哪些条件?




评论