 基于多视图协作学习的人岗匹配研究论文提要
基于多视图协作学习的人岗匹配研究论文提要

近日,第29届国际计算机学会信息与知识管理大会(CIKM 2020)在线上召开,CIKM是CCF推荐的B类国际学术会议,是信息检索和数据挖掘领域顶级学术会议之一。
本届CIKM会议共收到920篇论文投稿,其中录用论文193篇,录取率约为21%。 而在众多论文当中,一篇BOSS直聘和中国人民大学联合发表的基于多视图协作学习的人岗匹配研究吸引了我们的注意力。

论文题目:《Learning to Match Jobs with Resumes from Sparse Interaction Data using Multi-View Co-Teaching Network》。 论文链接:https://arxiv.org/abs/2009.13299 本论文针对求职者和招聘方的交互行为数据稀疏且带有噪声这一场景,基于多视图协作学习,提出了一个新型匹配模型。 新型模型相比以往模型,增加了基于关系的匹配模块,且将两个匹配模块融合进行协作训练,优化了该场景下的人岗匹配效率。 CIKM大会评审反馈,该论文提出的多视图协作学习网络能够解决人岗匹配系统的负样本噪声问题。同时,融合文本匹配模块和关系匹配模块进行的联合表示学习有助于解决双边交互行为数据稀疏问题,突破了以往匹配模型需要大量有效样本数据的限定条件。而该思路对于互联网求职招聘场景以外领域的推荐系统研究也有一定指导意义。
1
背景介绍
近年来,随着以BOSS直聘为代表的移动互联网求职招聘平台的兴起,人岗匹配任务越来越受到学术界的关注。 针对该问题,常见的方法是将其转化为一个有监督的文本匹配任务来解决,当标记样本足够充分时,此类方法往往能取得较好的效果。 然而,在真实的互联网求职招聘平台上,求职者和招聘方的交互行为数据往往是稀疏且带有噪声的,这严重影响着匹配算法的性能。 因此,本文提出了一种基于稀疏交互数据的多视图协作学习模型,并将其应用于人岗匹配任务,取得了较好的效果。 该方法的思路如下: 我们设计了一种全新的匹配模型,包含基于文本的匹配模块和基于关系的匹配模块两部分,这两部分能捕获不同视角下的语义信息,并相互补充。 此外,为了解决交互行为数据稀疏的问题,我们设计了两种特定训练策略来更好地融合这两个匹配模块: 一方面,两个模块共享学习参数和表示,可以增强每个模块初始的表示; 另一方面,我们采用了一种协作学习的机制来减少噪声数据对训练的影响。核心思想是让这两个模块通过选择更置信的训练实例来互相指导训练。 这两种策略可以更好地用于表示的增强和数据的增强。 与单纯基于文本的匹配模型相比,我们所提出的方法能够从有限甚至稀疏的交互数据中更好地学习数据的表示,在带有噪声的训练数据上该方法也更具鲁棒性。
2
问题定义
对于人岗匹配任务,给定职位文本数据集合

和简历文本数据集合

,以及匹配结果集合
。 其中,每一个职位j或简历r均由多句描述职位或简历的文本构成, 代表简历和职位是否匹配。根据上述定义,我们的任务是学习一个预测函数
代表简历和职位是否匹配。根据上述定义,我们的任务是学习一个预测函数
来预测未知的职位简历对的匹配结果。
3
方法描述
多视图协作学习的人岗匹配模型图 为了解决在线求职招聘场景下由于交互数据稀疏和采样负例而带来的噪声问题,我们提出了一种基于多视图协作学习的人岗匹配模型。
基于文本的匹配模块近年来,基于预训练语言模型的方法在各种自然语言处理任务上均取得了不错的效果。 鉴于此,这里采用BERT编码简历和职位的每一个句子表示,然后使用Transformer编码表示整篇文档表示。

j和r分别代表职位和简历文档,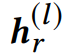 和分别代表第层的输入简历和职位的向量。
和分别代表第层的输入简历和职位的向量。

最后将职位表示和简历表示拼接后再接一个Sigmoid层输出得到的 作为候选简历和职位的匹配分。
作为候选简历和职位的匹配分。
基于关系的匹配模块前文所述的匹配模块主要关注文本语义上的匹配,但由于显式交互数据是相对稀疏的,因此挖掘潜在的隐式关联将有助于抽取出更多额外信息作为补充。 为此我们设计了基于关系的匹配模块,该模块包含构造职位-简历关系图和学习职位简历的表示两部分。构造职位-简历关系图首先定义职位-简历关系图

。其中,

代表职位和简历两类节点,

代表关系集合。 由于有职位和简历两类节点,所以共包含三种连接类型,即职位-职位,职位-简历和简历-简历。同时,采用如下两种数据信号来刻画节点间的连接关系:第一类是相同领域标签的职位或者简历之间构建连接关系;第二类是根据职位描述或简历文本中抽取出的关键词,职位或者简历之间出现了同样的关键词构建连接关系。职位简历的表示学习基于职位-简历关系图,可以进一步捕捉图上潜在的语义信息来学习节点上的特征表示(即职位和简历)。 图神经网络近年来已经成为学习图节点特征表示的最流行的方法,由于在职位-简历关系图中存在大量不同类别的关系连接,为了更好刻画在这类带有丰富关系的图结构,这里采用关系图卷积网络(Relational Graph Convolutional Network)来刻画不同关系和节点的表示。 第l层的节点学习到的表示的公式如下:


代表了第l层节点的表示, 代表节点
代表节点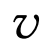 的邻接节点集合。由于每一种关系t对应一个特定的参数矩阵
的邻接节点集合。由于每一种关系t对应一个特定的参数矩阵 ,所以能够基于关系的语义信息学习到节点的表示。 通过在图上学习的节点表示,最终得到简历和职位的表示,与之前的方法类似,通过拼接简历表示和职位表示计算最终匹配分。
,所以能够基于关系的语义信息学习到节点的表示。 通过在图上学习的节点表示,最终得到简历和职位的表示,与之前的方法类似,通过拼接简历表示和职位表示计算最终匹配分。

多视图的协作学习网络接下来将介绍所设计的多视图协作学习网络,以及如何将基于文本和基于关系的匹配模块集成到统一的训练方法中。 首先,网络会共享学习到的信息和参数,以增强每个模块的原始表示;其次,针对如何减少训练数据对噪声的影响,我们借鉴了机器学习中协同学习的思想,通过选择更可靠的训练实例来让这两个组件相互帮助。接下来,介绍这两种策略的细节。表示增强由于在匹配过程中包含文本表示和关系表示两类表示方法,为了在初始表示学习的过程中互相增强,在初始学习文本模块的表示时会拼接关系图上节点的表示。

类似地,为了增强图关系上节点的表示,会采用文本模块学习到的表示作为关系图训练时的初始表示。
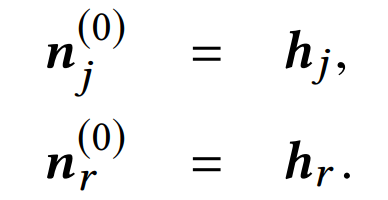
利用协作学习的数据增强这里的基本假设是,真实样本通常在不同的模型视角下会得到相似的预测结果,而噪声数据则会在不同视角下表现得不稳定。 在协作学习网络中,文本匹配模块和关系匹配模块可以视为两个对等的learner。用于训练一个learner的样本首先由另一个learner进行检查,并且仅将标记为高置信度的实例保留在训练过程中。 由于这两个learner从不同视角对数据建模,学习的策略有所不同,因此他们可以互相帮助选择高置信度的训练样本,从而提升模型效果。 具体训练方法如下图所示:

提出的co-teaching的算法流程图 这里具体提出了两种实现策略。(1)实例的重加权给定一个模型,其对等模型目的是在不同视角下,增加高置信度样本的权重并降低不可靠样本的权重。例如,对于模型B,假设在训练过程中的一个batch中有K个实例。

让其对等模型A为这个K个实例分配权重。其核心想法是根据样本真实标签信息与A的预测之间的一致程度对实例赋予权重:

这里的权重越高代表了该实例越可信。同时将这些权重结果传递给模型B并让其进行模型参数的更新。(2)实例的筛选过滤除了对不同样本重新加权外,还可以直接筛除相对较差的实例。直观地,如果实例对应的损失较小,则它离决策边界很远,更有可能是可靠的样本。可以通过以下公式建模:
实例重加权和筛选过滤方法都旨在为模型学习选择更可靠的样本。他们用不同的方法达到这个目的。 实例重新加权是一种相对“软”的方法,其所有实例均保留,只不过不同实例具有不同的重要程度。而实例筛选过滤是一种相对“硬”的方法,会直接丢弃一些样本。还有一种思路是通过在对样本重新加权之前对样本进行过滤来将这两种方法结合起来。
4
实验结果
数据集介绍本文基于在线招聘平台BOSS直聘的数据集进行相关实验。该数据集包括三个领域类别,便于测试我们的模型在不同领域下的稳定性。 表1总结了处理后的数据统计信息,可以看到:(1)所有数据集都很稀疏,无论是达成匹配或拒绝;(2)不同领域下的数据稀疏程度有所不同。例如,技术类规模较大但较稀疏,而销售相对稠密;(3)对于每个领域类别,发生显示拒绝(即不匹配)的数量要比达成匹配的数量少得多。
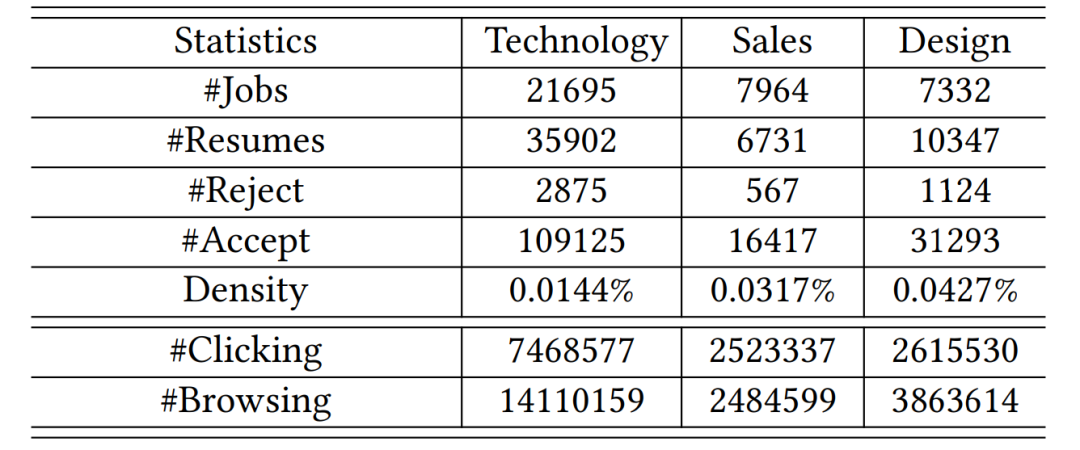
表1:数据集的统计信息
实验结果对比方法1、DSSM [1]提出的深度结构语义匹配模型。 2、BPJFNN [2]提出的基于循环神经网络的匹配模型。 3、PJFNN [3]提出的基于卷积神经网络的匹配模型。 4、APJFNN [2]提出的基于层级注意力机制的匹配模型。 5、DGMN [4]提出的基于全局句子粒度交互的匹配模型。 6、JRMPM [5]提出的引入历史交互作为记忆模块的匹配模型。 7、UBD [6]用来解决噪声数据带来的影响,采用分歧的思想对分类器双方产生不同结果的数据进行参数更新。 8、NFM [7]使用神经因子分解机来学习高阶交互,使用文本和ID特征作为输入。

表2:主实验的结果 根据表2中的实验结果,结论如下:1、首先,NFM很难在我们的任务上取得良好的效果。原因是该任务比传统推荐场景数据更加稀疏;同时,DSSM在大多数情况下表现不佳,因为它无法捕获文本信息中的时序信息;BPJFNN、PJFNN、APJFNN、JRMPM和DGMN之间的性能差异很小,并且针对不同指标或不同领域会有微小差别;此外,UBD是唯一训练时解决噪声问题的baseline,与其他baseline方法相比,该方法的效果有显著提升,这也侧面证实了该任务下处理噪声数据的必要性。2、我们提出的模型在不同数据集的所有指标上均获得了最佳性能。与其他方法相比,模型中的协作学习机制能够识别更多信息量丰富且更可靠的样本来学习参数,也更容易削弱噪声数据带来的影响,因此优于其他baseline方法。3、对比筛选过滤和重加权这两种策略,我们发现后者在大多数情况下更优异。可能因为重新加权策略采用了“软”降噪的方法,该方法在处理噪声数据时会更鲁棒。 除了上述主实验结果分析外,我们也同时分析了不同模块组件对最终效果的影响。 如表3所示,这里T代表文本匹配模块、R代表关系匹配模块、C代表协作学习网络。 结果表明,所有这三个组件对提高人岗匹配的性能都有正向作用。尤其是文本匹配模块和协作学习网络给模型带来的提升较大。 此外,一个有趣的观察是,简单地融合多视图的数据可能不会导致良好的性能(即TR
表3:消融实验结果
5
总结
本文提出了一种基于多视图协同教学网络,该网络能够在交互行为数据稀疏且带有噪声这一场景下进行学习,以进行人岗匹配。我们考虑融合文本匹配模块和关系匹配模块进行的联合表示学习,该方法能够结合各自模块的优势来更好的学习匹配表示。同时我们设计了两种特定训练策略来更好地融合这两个匹配模块,即表示增强和数据增强。一方面,两个模块共享学习参数和表示,可以增强每个模块初始的表示; 另一方面,我们采用了一种协作学习的机制来减少噪声数据对训练的影响。大量实验表明,与以往的方法对比,该方法能够从数据稀疏且带有噪声的交互数据中获得更好的匹配效果。在本文中,我们聚焦于宏观的交互行为,例如接受或拒绝面试邀请这样的行为。然而一些微观交互也会对匹配产生一定的影响,例如单击或停留时间。未来我还将考虑将此类信息融入进来以设计一个更加全面的匹配模型。此外,我们还将考虑将我们的方法应用于更多的领域类别,研究不同类别之间的领域自适应问题。
参考文献
[1]Po-Sen Huang, Xiaodong He, Jianfeng Gao, Li Deng, Alex Acero, and Larry Heck. 2013. Learning deep structured semantic models for web search using clickthrough data. In Proceedings of the 22nd ACM international conference on Conference on information and knowledge management, pages 2333–2338. ACM.
[2]Chuan Qin, Hengshu Zhu, Tong Xu, Chen Zhu, Liang Jiang, Enhong Chen, and Hui Xiong. 2018. Enhancing person-job fit for talent recruitment: An ability-aware neural network approach. In In Proceedings of the 41st International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR-2018) , Ann Arbor, Michigan, USA. [3]Chen Zhu, Hengshu Zhu, Hui Xiong, Chao Ma, Fang Xie, Pengliang Ding, and Pan Li. 2018. Person-job fit: Adapting the right talent for the right job with joint representation learning. ACM Transactions on Management Information Systems ACM TMIS. [4]Shuqing Bian, Wayne Xin Zhao, Yang Song, Tao Zhang, and Ji-Rong Wen. 2019. Domain Adaptation for Person-Job Fit with Transferable Deep Global Match Network. In EMNLP-IJCNLP 2019. 4809–4819. [5]Rui Yan, Ran Le, Yang Song, Tao Zhang, Xiangliang Zhang, and Dongyan Zhao. 2019. Interview Choice Reveals Your Preference on the Market: To Improve Job-Resume Matching through Profiling Memories. In KDD 2019. 914–922. [6]Eran Malach and Shai Shalev-Shwartz. 2017. Decoupling "when to update" from "how to update". In NeurIPS 2017. 960–970. [7]XiangnanHe and Tat-SengChua. 2017.Neural Factorization Machines for Sparse Predictive Analytics. In SIGIR 2017. 355–364.
责任编辑:xj
原文标题:【CIKM 2020】基于多视图协作学习的人岗匹配研究
文章出处:【微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
-
噪声
+关注
关注
13文章
1162浏览量
49451 -
数据
+关注
关注
8文章
7349浏览量
95058 -
深度学习
+关注
关注
73文章
5610浏览量
124656 -
协作学习系统
+关注
关注
0文章
2浏览量
1714
原文标题:【CIKM 2020】基于多视图协作学习的人岗匹配研究
文章出处:【微信号:zenRRan,微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
飞腾联合发布基于自研CIS-RAN通算智融合基站的多机器人协作标杆方案

远程协作新范式:工业场景下的专家支持技术演进
专为MCU协作优化:HT4093充电芯片的关键特性与应用场景

多机协作如何实现机加工无人生产?


面向多枪并联快充的固变SST动态负载平衡与阻抗匹配控制策略研究



基于级联分类器的人脸检测基本原理
应用多光谱数字图像区分苗期作物与杂草的研究进展
华为、中国科学院计算技术研究所联合开发论文获USENIX收录

机器学习赋能的智能光子学器件系统研究与应用

云知声四篇论文入选自然语言处理顶会ACL 2025

基于LockAI视觉识别模块:C++多模板匹配
基于LockAI视觉识别模块:C++多模板匹配




评论