 语义分割算法系统介绍
语义分割算法系统介绍
图像语义分割是图像处理和是机器视觉技术中关于图像理解的重要任务。语义分割即是对图像中每一个像素点进行分类,确定每个点的类别,从而进行区域划分,为了能够帮助大家更好的了解语义分割领域,我们精选知乎文章。作者Xavier CHEN针对语义分割进行系统的介绍,从原理解析到算法发展总结,文章思路清晰,总结全面,推荐大家阅读。
本文作者为Xavier CHEN,毕业于浙江大学,在知乎持续分享前沿文章。
01
前言
之前做了一个语义分割的综述报告,现在把报告总结成文章。这篇文章将分为三个部分:
1.语义分割基本介绍:明确语义分割解决的是什么问题。
2.从FCN到Deeplab v3+:解读语义分割模型的发展,常用方法与技巧
3.代码实战中需要注意的问题。
02
语义分割基本介绍
2.1 概念
语义分割(semantic segmentation) : 就是按照“语义”给图像上目标类别中的每一点打一个标签,使得不同种类的东西在图像上被区分开来。可以理解成像素级别的分类任务。
输入:(H*W*3)就是正常的图片
输出:( H*W*class )可以看为图片上每个点的one-hot表示,每一个channel对应一个class,对每一个pixel位置,都有class数目 个channel,每个channel的值对应那个像素属于该class的预测概率。
figure1
2.2评价准则
1.像素精度(pixel accuracy ):每一类像素正确分类的个数/ 每一类像素的实际个数。
2.均像素精度(mean pixel accuracy ):每一类像素的精度的平均值。
3.平均交并比(Mean Intersection over Union):求出每一类的IOU取平均值。IOU指的是两块区域相交的部分/两个部分的并集,如figure2中 绿色部分/总面积。
4.权频交并比(Frequency Weight Intersection over Union):每一类出现的频率作为权重
figure2
03
从FCN 到Deeplab V3+
语义分割的原理和常用技巧
3.1 FCN
FCN是语义分割的开山之作,主要特色有两点:
1.全连接层换成卷积层
2.不同尺度的信息融合FCN-8S,16s,32s
看详细讲解 推荐:
https://zhuanlan.zhihu.com/p/30195134
3.1.1 全连接层换成卷积层
figure3
以Alexnet的拓扑结构为例
原本的结构:224大小的图片经过一系列卷积,得到大小为1/32 = 7的feature map,经过三层全连接层,得到基于FC的分布式表示。
我们把三层全连接层全都换成卷积层,卷积核的大小和个数如下图中间行所示,我们去掉了全连接层,但是得到了另外一种基于不同channel的分布式表示:Heatmap
举一个例子,我们有一个大小为384的图片,经过替换了FC的Alexnet,得到的是6*6*1000的Heatmap,相当于原来的Alexnet 以stride = 32在输入图片上滑动,经过上采样之后,就可以得到粗略的分割结果。
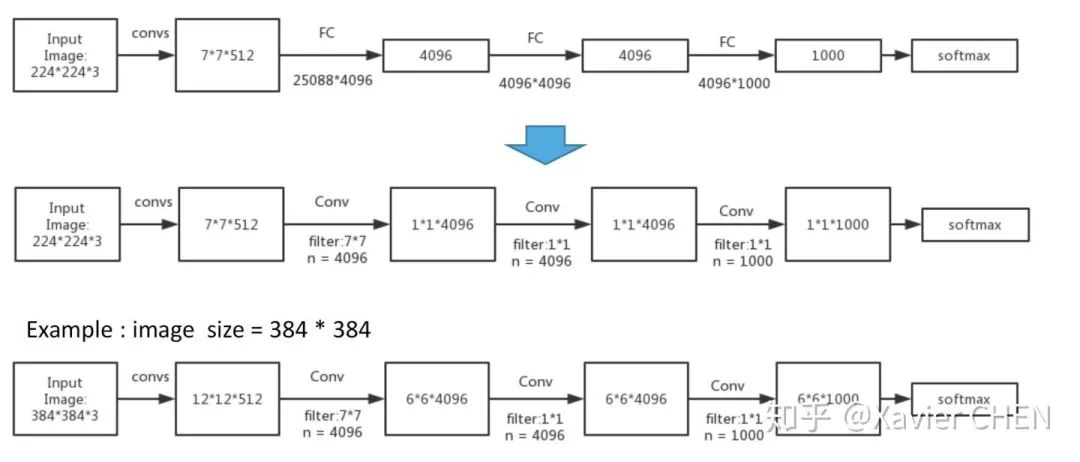
figure4
3.1.2 不同尺度的信息融合
就像刚刚举的Alexnet的例子,对于任何的分类神经网络我们都可以用卷积层替换FC层,只是换了一种信息的分布式表示。如果我们直接把Heatmap上采样,就得到FCN-32s。如下图
figure5
但是我们知道,随着一次次的池化,虽然感受野不断增大,语义信息不断增强。但是池化造成了像素位置信息的丢失:直观举例,1/32大小的Heatmap上采样到原图之后,在Heatmap上如果偏移一个像素,在原图就偏移32个像素,这是不能容忍的。
见figure6,前面的层虽然语义信息较少,但是位置信息较多,作者就把1/8 1/16 1/32的三个层的输出融合起来了。先把1/32的输出上采样到1/16,和Pool4的输出做elementwose addition , 结果再上采样到1/8,和Pool3的输出各个元素相加。得到1/8的结果,上采样8倍,求Loss。
figure6
3.2 U-net
figure7
U-net用于解决小样本的简单问题分割,比如医疗影片的分割。它遵循的基本原理与FCN一样:
1.Encoder-Decoder结构:前半部分为多层卷积池化,不断扩大感受野,用于提取特征。后半部分上采样回复图片尺寸。
2.更丰富的信息融合:如灰色剪头,更多的前后层之间的信息融合。这里是把前面层的输出和后面层concat(串联)到一起,区别于FCN的逐元素加和。不同Feature map串联到一起后,后面接卷积层,可以让卷积核在channel上自己做出选择。注意的是,在串联之前,需要把前层的feature map crop到和后层一样的大小。
3.3 SegNet
figure 8
在结构上看,SegNet和U-net其实大同小异,都是编码-解码结果。区别在意,SegNet没有直接融合不同尺度的层的信息,为了解决为止信息丢失的问题,SegNet使用了带有坐标(index)的池化。如下图所示,在Max pooling时,选择最大像素的同时,记录下该像素在Feature map的位置(左图)。在反池化的时候,根据记录的坐标,把最大值复原到原来对应的位置,其他的位置补零(右图)。后面的卷积可以把0的元素给填上。这样一来,就解决了由于多次池化造成的位置信息的丢失。
figure 9
3.4 Deeplab V1
figure10
这篇论文不同于之前的思路,他的特色有两点:
1.由于Pooling-Upsample会丢失位置信息而且多层上下采样开销较大,把控制感受野大小的方法化成:带孔卷积(Atrous conv)
2.加入CRF(条件随机场),利用像素之间的关连信息:相邻的像素,或者颜色相近的像素有更大的可能属于同一个class。
3.4.1 Atrous Conv
如右下图片所示,一个扩张率为2的带孔卷积接在一个扩张率为1的正常卷积后面,可以达到大小为7的感受野,但是输出的大小并没有减小,参数量也没有增大。
figure 11
3.4.2 条件随机场CRF
figure 12
3.5 PSPnet
figure13
原理都大同小异,前面的不同level的信息融合都是融合浅层和后层的Feature Map,因为后层的感受野大,语义特征强,浅层的感受野小,局部特征明显且位置信息丰富。
PSPnet则使用了空间金字塔池化,得到一组感受野大小不同的feature map,将这些感受野不同的map concat到一起,完成多层次的语义特征融合。
3.6 Deeplab V2
figure 14
Deeplab v2在v1的基础上做出了改进,引入了ASPP(Atrous Spatial Pyramid Pooling)的结构,如上图所示。我们注意到,Deeplab v1使用带孔卷积扩大感受野之后,没有融合不同层之间的信息。
ASPP层就是为了融合不同级别的语义信息:选择不同扩张率的带孔卷积去处理Feature Map,由于感受野不同,得到的信息的Level也就不同,ASPP层把这些不同层级的feature map concat到一起,进行信息融合。
3.7 Deeplab v3
Deeplab v3在原有基础上的改动是:
1.改进了ASPP模块
2.引入Resnet Block
3.丢弃CRF
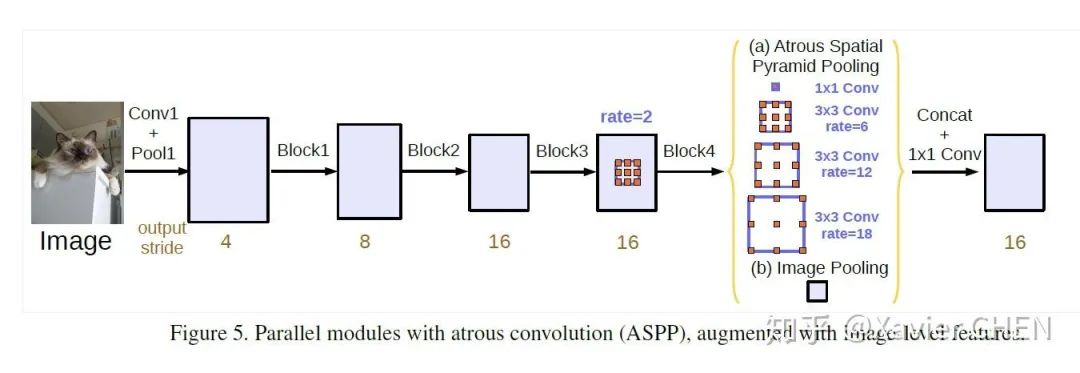
figure15
新的ASPP模块:
1.加入了Batch Norm
2.加入特征的全局平均池化(在扩张率很大的情况下,有效权重会变小)。如图14中的(b)Image Pooling就是全局平均池化,它的加入是对全局特征的强调、加强。
在旧的ASPP模块中:我们以为在扩张率足够大的时候,感受野足够大,所以获得的特征倾向于全局特征。但实际上,扩张率过大的情况下,Atrous conv出现了“权值退化”的问题,感受野过大,都已近扩展到了图像外面,大多数的权重都和图像外围的zero padding进行了点乘,这样并没有获取图像中的信息。有效的权值个数很少,往往就是1。于是我们加了全局平均池化,强行利用全局信息。
3.8 Deeplab v3+
figure16
可以看成是把Deeplab v3作为编码器(上半部分)。后面再进行解码,并且在解码的过程中在此运用了不同层级特征的融合。
此外,在encoder部分加入了Xception的结构减少了参数量,提高运行速递。关于Xception如何减少参数量,提高速度。建议阅读论文 : Mobilenet
https://arxiv.org/pdf/1704.04861.pdf
3.9 套路总结
看完这么多论文,会发现他们的方法都差不多,总结为一下几点。在自己设计语义分割模型的时候,遵循一下规则,都是可以涨点的。但是要结合自己的项目要求,选择合适的方法。
1.全卷积网络,滑窗的形式
2.感受野的控制:Pooling+Upsample => Atrous convolution
3.不同Level的特征融合:统一尺寸之后Add / Concat+Conv, SPP, ASPP…
4.考虑相邻像素之间的关系:CRF
5.在条件允许的情况下,图像越大越好。
6.分割某一个特定的类别,可以考虑使用先验知识+ 对结果进行图像形态学处理
7.此外还有一些其他的研究思路:实时语义分割,视频语义分割
责任编辑:xj
原文标题:一文速览!语义分割算法盘点
文章出处:【微信公众号:新机器视觉】欢迎添加关注!文章转载请注明出处。
-
算法
+关注
关注
23文章
4608浏览量
92852 -
FC
+关注
关注
1文章
77浏览量
42001 -
卷积
+关注
关注
0文章
95浏览量
18509
原文标题:一文速览!语义分割算法盘点
文章出处:【微信号:vision263com,微信公众号:新机器视觉】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
利用VLM和MLLMs实现SLAM语义增强

【「从算法到电路—数字芯片算法的电路实现」阅读体验】+介绍基础硬件算法模块
手册上新 |迅为RK3568开发板NPU例程测试
语义分割25种损失函数综述和展望

画面分割器怎么调试
手册上新 |迅为RK3568开发板NPU例程测试
图像语义分割的实用性是什么
图像分割和语义分割的区别与联系
迅为RK3568手册上新 | RK3568开发板NPU例程测试
图像分割与语义分割中的CNN模型综述
算法系列:彩色转灰度
算法系列:基于 FPGA 的图像边缘检测系统设计(sobel算法)
助力移动机器人下游任务!Mobile-Seed用于联合语义分割和边界检测

计算机视觉的十大算法





 工商网监
工商网监
评论